

Вступ до приєднання до Spark SQL
Як нам відомо, з'єднання в SQL використовуються для об'єднання даних або рядків з двох або більше таблиць на основі загального поля між ними. У цій темі ми дізнаємось про Join in Spark SQL Join in Spark SQL.
У Spark SQL Dataframe або Dataset - це таблична структура пам'яті, що містить рядки та стовпці, які розподілені по декількох вузлах. Як і звичайні таблиці SQL, ми також можемо виконувати операції приєднання на Dataframe або Dataset, наявних у Spark SQL, на основі спільного поля між ними.
У SQL існують різні типи операцій Join. Залежно від випадку використання бізнесу, ми робимо вибір операції Join. У наступному розділі ми продемонструємо на прикладі кожен тип з'єднання.
Типи приєднання до Spark SQL
Нижче наведено різні типи приєднань, доступних у Spark SQL:
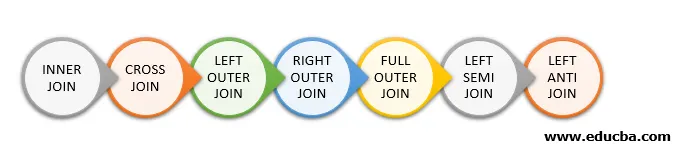
- ВНУТРІШНЄ З'ЄДНАННЯ
- КРОВИЙ ПРИЄДНАЙТЕСЬ
- ЛІВНІЙ ЗОВНІШНІ ПРИЄДНАЙТЕСЬ
- ПРАВО ПРИЄДНАЙТЕСЬ
- ПОВНОГО ПРИЄДНАЙТЕСЬ
- ЛІВА СЕМІ ПРИЄДНАЙТЕСЬ
- ЛІВО АНТИ ПРИЄДНАЙТЕСЬ
Приклад створення даних
Ми будемо використовувати такі дані, щоб продемонструвати різні типи приєднань:
Набір даних книги:
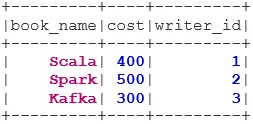
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Набір даних Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Типи приєднань
Нижче згадуються 7 різних типів приєднань:
1. ВНУТРІШНЕ ПРИЄДНАННЯ
INNER JOIN повертає набір даних, у яких є рядки, які мають відповідні значення в обох наборах даних, тобто значення загального поля буде однаковим.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. КРОВИЙ ПРИЄДНАЙТЕСЬ
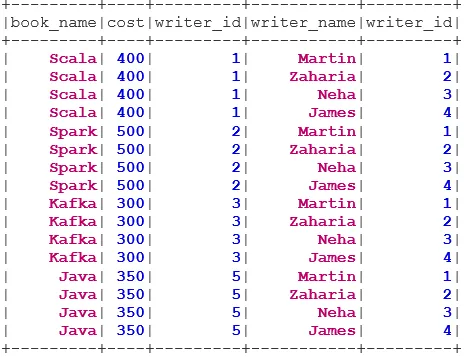
CROSS JOIN повертає набір даних, що є числом рядків у першому наборі даних, помноженим на кількість рядків у другому наборі даних. Такого роду результат називається декартовим продуктом.
Необхідна умова: Для використання перехресного з'єднання, spark.sql.crossJoin.enabled має бути встановлено на значення true. Інакше виняток буде кинутий.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. ЛІВНІЙ ЗОВНІШНІЙ ПРИЄДНАЙТЕСЬ
LEFT OUTER JOIN повертає набір даних, у якому є всі рядки з лівого набору даних, і відповідні рядки з правого набору даних.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. ПРАВИЛЬНО ПРИЄДНАЙТЕСЬ ДО ВНУ
RIGHT OUTER JOIN повертає набір даних, який містить усі рядки з правого набору даних, а відповідні рядки - з лівого набору даних.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. ПОВНОГО ПРИЄДНАЙТЕСЬ
FULL OUTER JOIN повертає набір даних, що має всі рядки, коли є збіг у лівій чи правій наборі даних.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. ЛІВНІ СЕМІ ПРИЄДНАЙТЕСЬ
LEFT SEMI JOIN повертає набір даних, який містить усі рядки з лівого набору даних, маючи свою кореспонденцію у правій наборі даних. На відміну від LEFT OUTER JOIN, повернутий набір даних у LEFT SEMI JOIN містить лише стовпці з лівого набору даних.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. ЛІВО АНТИ ПРИЄДНАЙТЕСЬ
ANTI SEMI JOIN повертає набір даних, який містить усі рядки з лівого набору даних, які не відповідають їх правильному набору даних. Він також містить лише стовпці з лівого набору даних.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Висновок - Приєднуйтесь до Spark SQL
Дані про приєднання є однією з найпоширеніших та найважливіших операцій для виконання нашої справи щодо використання бізнесу. Spark SQL підтримує всі основні типи приєднань. Під час приєднання ми також повинні враховувати продуктивність, оскільки вони можуть вимагати великих мережевих передач або навіть створювати набори даних, що перевищують наші можливості. Для підвищення продуктивності Spark використовує оптимізатор SQL для повторного замовлення або натискання фільтрів. Іскра також обмежує небезпечне з'єднання i. e CROSS ПРИЄДНАЙТЕСЬ. Для використання перехресного з'єднання, spark.sql.crossJoin.enabled має бути встановлено в прямому імені.
Рекомендовані статті
Це посібник для приєднання до Spark SQL. Тут ми обговорюємо різні типи приєднань, доступних у Spark SQL, із прикладом. Ви також можете подивитися наступну статтю.
- Типи об'єднань у SQL
- Таблиця в SQL
- SQL Insert Query
- Операції в SQL
- PHP Фільтри | Як перевірити введення користувача за допомогою різних фільтрів?