
Вступ до зворотнього усунення
По мірі того, як людина і машина стукають до цифрової еволюції, різноманітні технічні машини ведуть облік, щоб вони не тільки були навчені, але і спритно навчені виходити з кращим розпізнаванням об'єктів реального світу. Така методика, запроваджена раніше під назвою "Зворотна елімінація", яка мала на меті сприяти необхідним функціям, викорінюючи обов'язкові функції, щоб забезпечити кращу оптимізацію в машині. Вся майстерність розпізнавання об'єктів Машиною пропорційна тому, які особливості розглядає.
Функції, які не мають посилання на передбачуваний вихід, повинні бути вивантажені з машини, і це завершується шляхом усунення назад. Хороша точність та часова складність розпізнавання будь-якого реального об'єкта слова машиною залежать від його засвоєння. Тож зворотне усунення відіграє свою жорстку роль для вибору особливостей. Він вважає швидкість залежності ознак від залежної змінної, знаходить значущість її приналежності в моделі. Щоб акредитувати це, він перевіряє нараховану ставку зі стандартним рівнем значущості (скажімо, 0, 06) і приймає рішення про вибір функції.
Чому ми запускаємо зворотне усунення ?
Несуттєві та зайві риси сприяють складності логіки машини. Це непотрібно пожирає час і ресурси моделі. Отже, згадана вище техніка грає грамотну роль, щоб сформувати модель на просте. Алгоритм культивує найкращу версію моделі, оптимізуючи її продуктивність та використовуючи витрачені призначені ресурси.
Це зменшує найменш уважні риси моделі, що викликає шум при визначенні лінії регресії. Нерелевантні риси об'єкта можуть спричиняти неправильну класифікацію та прогнозування. Нерелевантні особливості суб'єкта господарювання можуть становити дисбаланс у моделі стосовно інших суттєвих особливостей інших об'єктів. Відсталене усунення сприяє пристосуванню моделі до найкращого випадку. Отже, зворотне усунення рекомендується використовувати в моделі.
Як застосувати зворотне усунення?
Відступ назад починається з усіх змінних характеристик, випробовуючи його залежною змінною відповідно до обраного критерію моделі. Він починає викорінювати ті змінні, які погіршують придатну лінію регресії. Повторюючи це видалення, поки модель не набуде належної форми. Нижче наведено кроки, спрямовані на практику зворотного усунення:
Крок 1: Виберіть відповідний рівень значущості для розміщення в моделі машини. (Візьміть S = 0, 06)
Крок 2: Подайте всі доступні незалежні змінні моделі щодо залежної змінної та комп’ютерного нахилу та перехоплення, щоб провести лінію регресії чи лінію підгонки.
Крок 3: Перейдіть по всій незалежній змінній, яка має найвище значення (Take I), одна за одною, і перейдіть до наступного тосту:
а) Якщо I> S, виконайте 4-й крок.
б) Інакше перервати, і модель ідеальна.
Крок 4: Видаліть вибрану змінну та збільште прохід.
Крок 5: Повторно підробляйте модель ще раз і обчислюйте схил та перехоплення лінії підгонки за допомогою залишкових змінних.
Вищезазначені кроки підсумовуються до відмови від тих ознак, ступінь значущості яких перевищує вибране значення значущості (0, 06) для ухилення від перекласифікації та надмірного використання ресурсів, що спостерігається як висока складність.
Заслуги та недоліки відсталого усунення
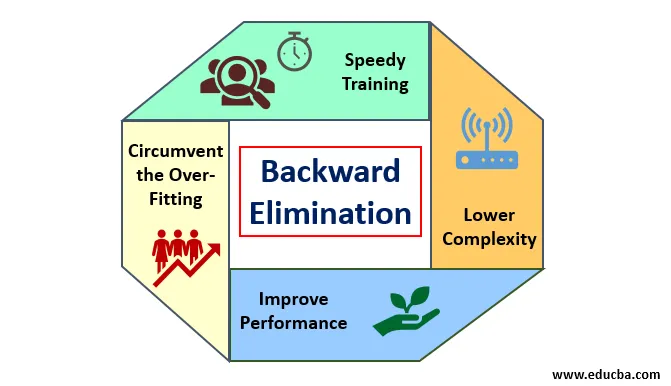
Ось деякі достоїнства та недоліки зворотнього усунення, наведені нижче докладно:
1. Заслуги
Заслугою зворотного усунення є:
- Швидке навчання: Машина проходить навчання з набором доступних функцій шаблону, який робиться за дуже короткий час, якщо з моделі вилучені несуттєві функції. Швидке навчання набору даних з’являється на увазі лише тоді, коли модель має значні особливості та виключає всі змінні шуму. Це малює просту складність для навчання. Але модель не повинна зазнавати недооцінки, яка виникає через відсутність особливостей або неадекватних зразків. Особливість вибірки повинна бути рясною в моделі для найкращої класифікації. Час, необхідний для підготовки моделі, повинен бути меншим, зберігаючи при цьому точність класифікації, і не має змінної недооцінки.
- Нижня складність: Складність моделі буває високою, якщо модель передбачає ступінь особливостей, включаючи шум та непов'язані функції. Модель вимагає багато місця та часу для обробки такого діапазону функцій. Це може збільшити швидкість точності розпізнавання шаблонів, але також може містити шум. Щоб позбутися настільки високої складності моделі, алгоритм усунення відсталого відіграє необхідну роль, віддаляючи від моделі небажані функції. Це спрощує логіку обробки моделі. Лише декілька суттєвих особливостей є достатньою, щоб зробити гарну форму, яка містить розумну точність.
- Підвищення продуктивності: Продуктивність моделі залежить від багатьох аспектів. Модель піддається оптимізації за допомогою зворотного усунення. Оптимізація моделі - це оптимізація набору даних, що використовується для навчання моделі. Продуктивність моделі прямо пропорційна швидкості її оптимізації, яка спирається на частоту значущих даних. Процес усунення назад не призначений для запуску змін з будь-якого низькочастотного передбачувача. Але зміни починаються лише з високочастотних даних, оскільки в основному складність моделі залежить від цієї частини.
- Обхід надмірного розміщення : Ситуація надмірного розміщення виникає тоді, коли модель отримала занадто багато наборів даних і проводиться класифікація чи прогнозування, в яких деякі прогнозатори отримують шум інших класів. У цьому примірці модель повинна надати несподівано високу точність. При надмірному розміщенні модель може не класифікувати змінну через плутанину, створену в логіці через занадто багато умов. Техніка усунення відсталого зменшує зовнішню особливість, щоб обійти ситуацію надмірного прилягання.
2. Демері
Дефекти відсталого усунення такі:
- У зворотному методі усунення не можна з’ясувати, який передбачувач відповідає за відхилення іншого передбачувача через його досягнення до незначущості. Наприклад, якщо передбачувач X має деяке значення, яке було достатньо добре для проживання в моделі після додавання Y-провісника. Але значення X застаріває, коли в модель потрапляє інший передбачувач Z. Таким чином, алгоритм усунення відсталого не свідчить про будь-яку залежність між двома предикторами, які трапляються в "техніці вибору вперед".
- Після вилучення будь-якої функції з моделі за допомогою зворотного алгоритму усунення цю функцію неможливо вибрати знову. Коротше кажучи, зворотне усунення не має гнучких підходів до додавання або видалення функцій / предикторів.
- Норми вибору значення значущості (0, 06) у моделі негнучкі. Зворотне усунення не має гнучкої процедури не лише вибору, але і зміни незначного значення, як це потрібно для того, щоб отримати найкраще пристосування під відповідним набором даних.
Висновок
Техніка усунення назад, реалізована для покращення продуктивності моделі та оптимізації її складності. Він яскраво використовується в декількох регресіях, де модель має справу з великим набором даних. Це простий і простий підхід порівняно з вибором вперед та перехресною валідацією, в якому виникає перевантаження оптимізації. Метод зворотного усунення ініціює усунення особливостей більш високого значення. Її основна мета - зробити модель менш складною і заборонити надмірну обстановку.
Рекомендовані статті
Це посібник із зворотного усунення. Тут ми обговорюємо, як застосувати зворотне усунення разом із достоїнствами та недоліками. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Гіперпараметр машинного навчання
- Кластеризація в машинному навчанні
- Віртуальна машина Java
- Непідконтрольне машинне навчання