

Знайомство з картою Приєднайтесь до вулика
Об’єднання карт - це функція, яка використовується у запитах вуликів для підвищення його ефективності щодо швидкості. Приєднання - це умова, що використовується для об'єднання даних з 2 таблиць. Отже, коли ми виконуємо звичайне об'єднання, завдання надсилається до завдання зменшення карт, яке розбиває основне завдання на 2 етапи - "Етап карти" та "Зменшити етап". Етап «Карта» інтерпретує вхідні дані та повертає висновок на етап зменшення у вигляді пар ключ-значення. Далі йде через етап перетасування, де вони сортуються та поєднуються. Редуктор приймає це відсортоване значення і виконує завдання з'єднання.
Таблиця може бути завантажена в пам'ять повністю в картографічному режимі і без використання процесу Map / Reducer. Він зчитує дані з меншої таблиці і зберігає їх у хеш-таблиці пам'яті, а потім серіалізує їх у файл хеш-пам'яті, тим самим скорочуючи час. Він також відомий як Map Side Join в вулику. В основному це передбачає виконання з'єднань між двома таблицями, використовуючи лише фазу Map і пропускаючи фазу зменшення. Зниження часу обчислень ваших запитів може спостерігатися, якщо вони регулярно використовують невеликі таблиці.
Синтаксис приєднання до карти у вулику
Якщо ми хочемо виконати запит приєднання за допомогою map-join, то нам слід вказати ключове слово "/ * + MAPJOIN (b) * /" у викладі, як показано нижче:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Для цього прикладу нам потрібно створити 2 таблиці з іменами tablename1 та tablename2, що мають 2 стовпці: emp_id та emp_name. Один повинен бути більшим файлом, а другий - меншим.
Перш ніж запустити запит, ми повинні встановити наведене нижче властивість на істинне:
hive.auto.convert.join=true
Запит запиту на приєднання до карти записується як вище, і результат, який ми отримуємо:
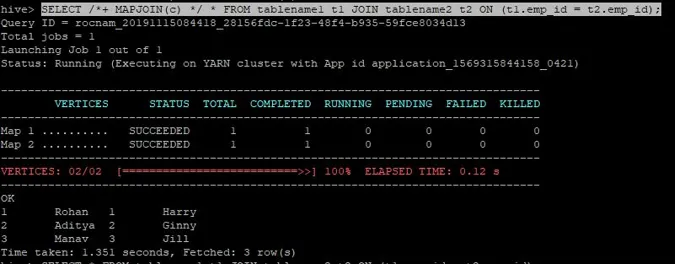
Запит завершено за 1.351 секунду.
Приклади приєднання до карти у вулику
Ось наступні приклади, згадані нижче
1. Приклад об’єднання карти
Для цього прикладу створимо 2 таблиці з назвою table1 та table2 зі 100 та 200 записами відповідно. Ви можете вказати команду та скріншоти нижче, щоб виконати те саме:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

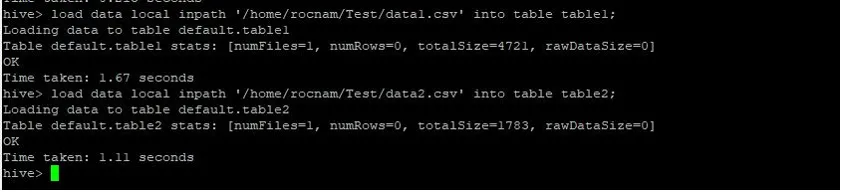
Тепер ми завантажуємо записи в обидві таблиці, використовуючи команди нижче:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Давайте виконаємо звичайний запит на приєднання до карти на своїх ідентифікаційних номерах, як показано нижче, і перевіримо час, необхідний для цього:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
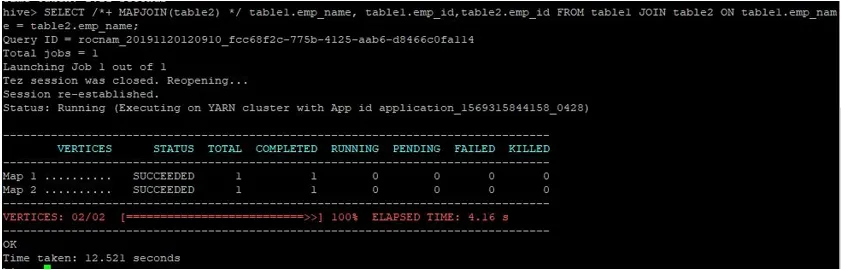
Як ми бачимо, звичайний запит на приєднання до карти зайняв 12.521 секунду.
2. Приклад приєднання Bucket-Map
Давайте тепер використовуємо приєднання Bucket-map, щоб виконати те саме. Існує кілька обмежень, яких необхідно дотримуватися для видобутку:
- Відра можна з'єднувати між собою лише у тому випадку, якщо загальна кількість відра будь-якої однієї таблиці кратна кількості відра в іншій таблиці.
- Повинно мати заряджені столи, щоб виконати виїмку. Отже, давайте створимо те саме.
Далі наведені команди, які використовуються для створення прихованих таблиць table1 та table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Ми також вставимо ті самі записи з table1 в ці таблиці, що забудуються:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
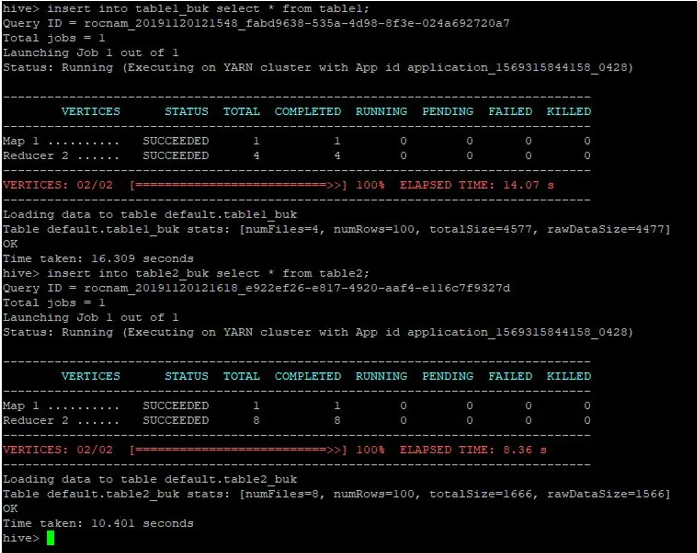
Тепер, коли у нас є дві таблички, що підлягають збиткові, виконаймо приєднання до них картки відра. Перша таблиця має 4 відра, тоді як друга таблиця має 8 відер, створених в одному стовпчику.
Для того, щоб запит приєднання bucket-map працював, ми повинні встановити наведене нижче властивість у true у вулику:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
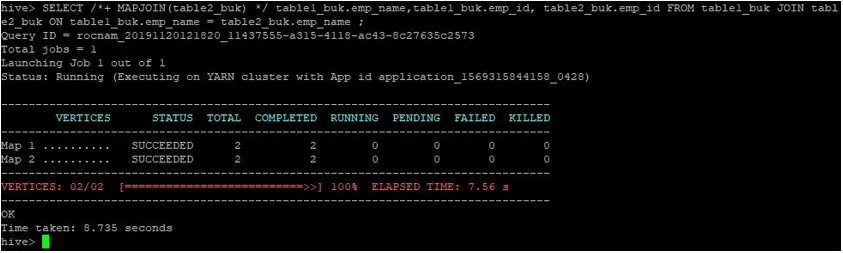
Як ми бачимо, запит завершився за 8, 735 секунд, що швидше, ніж звичайне об’єднання карти.
3. Сортування прикладу приєднання карти злиття відра (SMB)
SMB може бути виконано на таблицях, що мають групу, що мають однакову кількість відра, і якщо таблиці потрібно сортувати та записувати в колонки приєднання. Рівень Mapper приєднується до цих відер відповідно.
Як і в приєднанні до Bucket-map, є 4 відра для table1 та 8 відра для table2. Для цього прикладу ми створимо ще одну таблицю з 4 відрами.
Для запуску SMB-запиту нам потрібно встановити наступні властивості вулика, як показано нижче:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Для виконання SMB приєднання потрібно сортувати дані відповідно до стовпців приєднання. Отже, ми перезаписуємо дані в таблицю1, закреслену нижче:
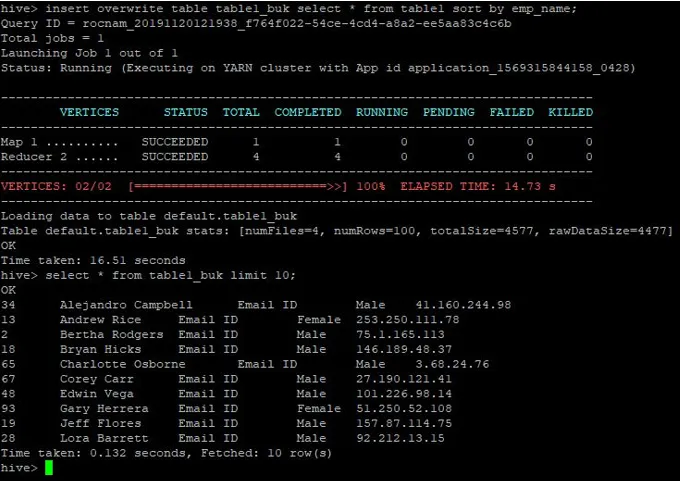
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Дані відсортовано зараз, що можна побачити на скріншоті нижче:
Також ми перезапишемо дані в зафіксовану таблицю2, як показано нижче:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Давайте виконаємо приєднання для вище двох таблиць наступним чином:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
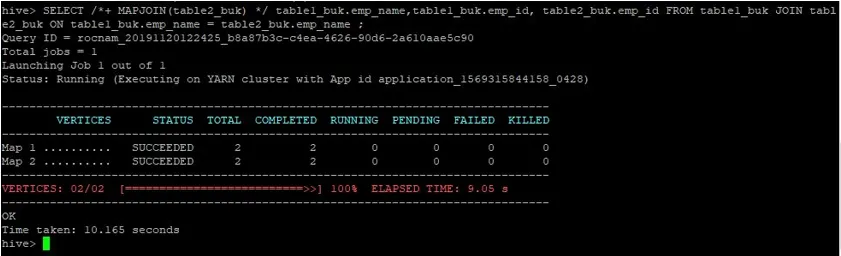
Ми можемо бачити, що запит зайняв 10.165 секунд, що знову краще, ніж звичайне об’єднання карти.
Тепер створимо ще одну таблицю для table2 з 4 відрами та тими ж даними, відсортованими за em_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
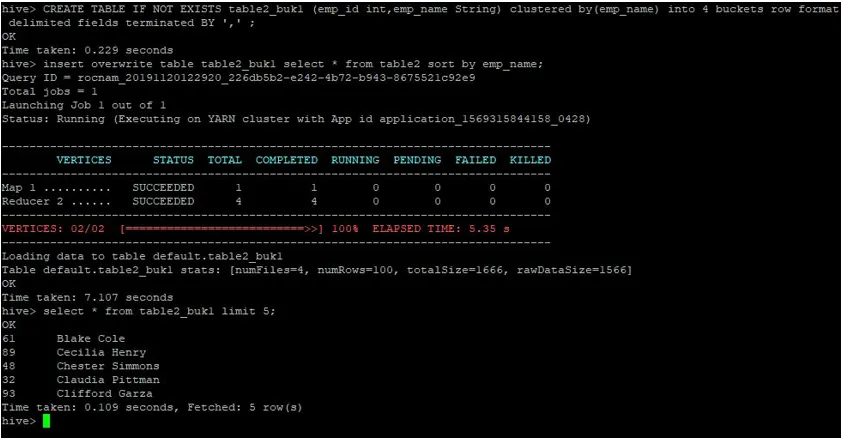
Враховуючи те, що зараз у нас обидві таблиці з 4 відрами, давайте знову виконаємо запит приєднання.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Запит знову зайняв 8, 851 секунди швидше, ніж звичайний запит на приєднання до карти.
Переваги
- Об'єднання карт скорочує час, який витрачається на процеси сортування та злиття, що протікають у перетасуванні, та скорочує етапи, таким чином мінімізуючи також витрати.
- Це підвищує ефективність виконання завдання.
Обмеження
- Таку ж таблицю / псевдонім заборонено використовувати для приєднання різних стовпців до одного запиту.
- Запит на приєднання до карти не може перетворити Повне зовнішнє з'єднання у з'єднання на стороні карти.
- Об'єднання карт може здійснюватися лише тоді, коли одна з таблиць є достатньо малою, щоб вона могла бути придатною до пам'яті. Отже, його неможливо виконати там, де даних таблиці величезні.
- Ліве об'єднання можливо зробити приєднанням до карти лише тоді, коли розмір правої таблиці невеликий.
- Праве приєднання можливо зробити приєднанням до карти лише тоді, коли розмір лівої таблиці невеликий.
Висновок
Ми намагалися включити найкращі можливі моменти Map Join в вулик. Як ми вже бачили вище, приєднання на стороні карти найкраще працює, коли одна таблиця має менше даних, щоб робота була швидко виконана. Час, необхідний для наведених тут запитів, залежить від розміру набору даних, отже час, показаний тут, призначений лише для аналізу. Об'єднання карт легко здійснити в додатках у режимі реального часу, оскільки у нас є величезна кількість даних, що сприяє зменшенню мережевого трафіку вводу / виводу.
Рекомендовані статті
Це посібник по карті приєднатися до вулика. Тут ми обговорюємо приклади Map Map in Hive разом з Перевагами та Обмеженнями. Ви також можете переглянути наступну статтю, щоб дізнатися більше -
- Приєднується до вулика
- Вбудовані функції вулика
- Що таке вулик?
- Команди вуликів