
Що таке GLM в R?
Узагальнені лінійні моделі - це підмножина лінійних регресійних моделей і ефективно підтримує ненормальні розподіли. Для підтримки цього рекомендується використовувати функцію glm (). GLM добре працює зі змінною, коли дисперсія не є постійною і розподіляється нормально. Визначена функція зв'язку для перетворення змінної реакції на відповідну модель. Модель LM робиться як із сім’єю, так і з формулою. Модель GLM має три ключові компоненти, які називаються випадковими (ймовірність), систематичними (лінійний предиктор), компонентами зв'язку (для функції logit). Перевага використання glm полягає в їх гнучкості моделі, відсутності необхідності в постійній дисперсії, і ця модель відповідає максимальній оцінці вірогідності та її співвідношенням. У цій темі ми збираємося дізнатись про GLM в Р.
Функція GLM
Синтаксис: glm (формула, сімейство, дані, ваги, підмножина, Start = null, модель = TRUE, method = ””…)
Тут типи сімей (включають типи моделей) включають біноміальну, пуассонську, гауссову, гамма, квазі. Кожен дистрибутив має різне використання і може використовуватися як в класифікації, так і в прогнозуванні. А коли модель є гауссовою, відповідь має бути справжнім цілим числом.
А коли модель є двочленною, відповідь має бути класами з бінарними значеннями.
А коли модель - Пуассон, відповідь має бути негативною із числовим значенням.
А коли модель гамма, відповідь має бути позитивним числовим значенням.
glm.fit () - Для підгонки до моделі
Lrfit () - позначає логістичну регресію придатності.
update () - допомагає в оновленні моделі.
anova () - його факультативний тест.
Як створити GLM в R?
Тут ми побачимо, як створити просту узагальнену лінійну модель з бінарними даними за допомогою функції glm (). І продовжуючи набір даних про Дерева.
Приклади
// Імпорт бібліотекиlibrary(dplyr)
glimpse(trees)

Для перегляду категоричних значень призначаються фактори.
levels(factor(trees$Girth))
// Перевірка безперервних змінних
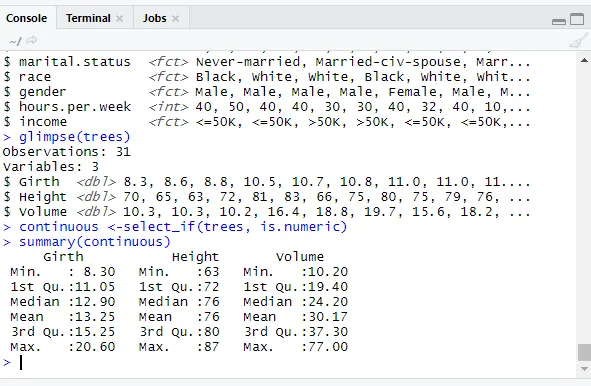
library(dplyr)
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Включення набору даних дерев у пошук R Pathattach (дерева)
x<-glm(Volume~Height+Girth)
x
Вихід:
| Виклик: glm (формула = Об'єм ~ Висота + обхват)
Коефіцієнти: (Перехоплення) Висота обхвату -57.9877 0.3393 4.7082 Ступені свободи: 30 Всього (тобто нуль); 28 Залишковий Нульове відхилення: 8106 Залишкове відхилення: 421, 9 AIC: 176, 9 |
summary(x)
| Виклик:
glm (формула = об'єм ~ висота + обхват) Залишки відхилення: Мінімум 1Q Медіана 3Q Макс -6.4065 -2.6493 -0.2876 2.2003 8.4847 Коефіцієнти: Оцінити Std. Помилка t значення Pr (> | t |) (Перехоплення) -57.9877 8.6382 -6.713 2.75e-07 *** Висота 0, 3393 0, 1302 2, 607 0, 0145 * Обхват 4.7082 0.2643 17.816 <2e-16 *** - Сигнаф. коди: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (Параметр дисперсії для сімейства гауссів прийнято до 15.06862) Нульове відхилення: 8106, 08 на 30 градусів свободи Залишковий відхилення: 421, 92 на 28 градусів свободи АПК: 176, 91 Кількість повторень підрахунку Фішера: 2 |
Вихід з підсумкової функції видає виклики, коефіцієнти та залишки. Вищезгадана відповідь визначає, що коефіцієнт корисної дії як по висоті, так і по обхвату є незначним, оскільки ймовірність їх менше 0, 5. І є два варіанти відхилення, названі нульовими та залишковими. Нарешті, підрахунок рибалки - це алгоритм, який вирішує максимально можливі питання. При двочленні відповідь є вектором або матрицею. cbind () використовується для зв'язування векторів стовпців у матриці. А для отримання детальної інформації підходить підсумок.
Як зробити тест з витяжкою, виконується наступний код.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
Модель підходить
a<-cbind(Height, Girth - Height)
> a
резюме (дерева)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
Для отримання відповідного стандартного відхилення
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
Далі ми посилаємось на змінну відповіді підрахунку для моделювання гарної відповіді відповіді. Щоб обчислити це, ми будемо використовувати набір даних USAccDeath.
Введемо наступні фрагменти в консоль R і подивимось, як на них виконується підрахунок року та квадратний рік.
data("USAccDeaths")
force(USAccDeaths)
// Проаналізувати рік 1973-1978.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Виклик:
glm (формула = count ~ рік + рікSqr, сімейство = “poisson”, дані = диск) Залишки відхилення: Мінімум 1Q Медіана 3Q Макс -22.4344 -6.4401 -0.0981 6.0508 21.4578 Коефіцієнти: Оцінити Std. Помилка z значення Pr (> | z |) (Перехоплення) 9.187e + 00 3.557e-03 2582.49 <2e-16 *** рік -7.207e-03 2.354e-04 -30.62 <2e-16 *** рікSqr 8.841e-05 3.221e-06 27.45 <2e-16 *** - Сигнаф. коди: 0 '***' 0, 001 '**' 0, 01 '*' 0, 05 '.' 0, 1 '' 1 (Параметр дисперсії для сімейства Пуассонів прийнято рівним 1) Нульове відхилення: 7357, 4 на 71 градус свободи Залишкове відхилення: 6358, 0 на 69 градусів свободи АПК: 7149, 8 Кількість повторень підрахунку Фішера: 4 |
Для перевірки відповідності моделі можна знайти наступну команду
залишки для тесту. З наведеного нижче результату значення дорівнює 0.
1 - pchisq(deviance(a1), df.residual(a1))
Використання сімейства QuasiPoisson для більшої дисперсії в даних даних
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Виклик:
glm (формула = count ~ рік + рікSqr, сімейство = “квазіпоассон”, дані = диск) Залишки відхилення: Мінімум 1Q Медіана 3Q Макс -22.4344 -6.4401 -0.0981 6.0508 21.4578 Коефіцієнти: Оцінити Std. Помилка t значення Pr (> | t |) (Перехоплення) 9.187e + 00 3.417e-02 268.822 <2e-16 *** рік -7.207e-03 2.261e-03 -3.188 0.00216 ** рікSqr 8.841e-05 3.095e-05 2.857 0.00565 ** - (Параметр дисперсії для сімейства квазіпуассонів прийнято до рівня 92, 28857) Нульове відхилення: 7357, 4 на 71 градус свободи Залишкове відхилення: 6358, 0 на 69 градусів свободи AIC: NA Кількість повторень підрахунку Фішера: 4 |
Порівняння Пуассона з величиною AIC бінома значно відрізняється. Їх можна проаналізувати за допомогою точності та відношення відношення. Наступним кроком є перевірка залишків дисперсії пропорційна середній. Тоді ми можемо побудувати графік, використовуючи бібліотеку ROCR для вдосконалення моделі.
Висновок
Тому ми зосередили увагу на спеціальній моделі під назвою узагальнена лінійна модель, яка допомагає у фокусуванні та оцінці параметрів моделі. Це насамперед потенціал для змінної безперервної відповіді. І ми бачили, як glm підходить до вбудованих пакетів R. Вони є найпопулярнішими підходами для вимірювання даних підрахунку і надійним інструментом для класифікаційних методів, які використовує науковець. Мова R, звичайно, допомагає виконувати складні математичні функції
Рекомендовані статті
Це посібник з GLM в Р. Тут ми обговорюємо функцію GLM та як створити GLM в R із прикладами наборів дерев та набором даних. Ви також можете переглянути наступну статтю, щоб дізнатися більше -
- R Мова програмування
- Велика архітектура даних
- Логістична регресія в R
- Вакансії з аналітики великих даних
- Пуассонова регресія в R | Реалізація Пуассонової регресії