

Відмінності між Sqoop і Flume
Sqoop - продукт із програмного забезпечення Apache. Sqoop витягує корисну інформацію з Hadoop, а потім передає до зовнішніх сховищ даних. За допомогою Sqoop ми можемо імпортувати дані з RDBMS або мейнфрейму в HDFS. Flume також від програмного забезпечення Apache. Він збирає та переміщує генеруються рекурсивні дані. Пристрій Apache Flume не тільки обмежується агрегуванням даних, але джерела даних налаштовуються, тому Flume можна використовувати для транспортування величезних кількостей даних. Найкращим способом збору, агрегації та переміщення великих обсягів даних між розподіленою файловою системою Hadoop та RDBMS є використання інструментів, таких як Sqoop або Flume.
Давайте обговоримо ці два найпоширеніші інструменти для вищезазначеної мети.
Що таке Sqoop
Щоб використовувати Sqoop, користувач повинен вказати інструмент, який користувач хоче використовувати, та аргументи, які керують певним інструментом. Потім можна експортувати дані назад в RDBMS за допомогою Sqoop. Експортна функціональність Sqoop використовується для отримання корисної інформації з Hadoop та експорту їх у зовнішні структуровані сховища даних. Він працює з різними базами даних, такими як Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Архітектура: -
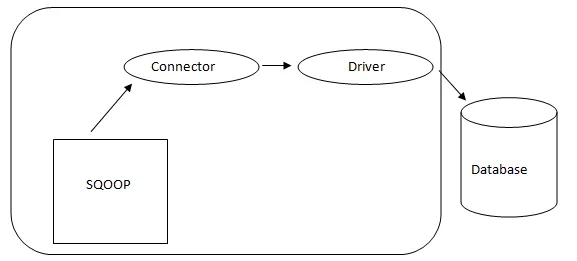
Архітектура Sqoop
Роз'єм у Sqoop є плагіном для певного джерела бази даних, тому основним є те, що він є частиною встановлення Sqoop. Незважаючи на те, що драйвери є частинами бази даних і поширюються різними постачальниками баз даних, Sqoop сам постачається в комплекті з різними типами роз'ємів, які використовуються для поширених систем зберігання баз даних та інформації. Таким чином, Sqoop також поставляється зі змішаною різноманітністю роз'ємів поза коробкою. Sqoop надає підключається компонент для ідеальної мережі та зовнішньої системи. API Sqoop дає корисну структуру для збирання нових роз'ємів, тому будь-які роз'єми бази даних можуть бути скинуті в установку Sqoop, щоб забезпечити підключення до різних систем даних.
Що таке Flume
Flume Apache не тільки обмежується агрегуванням даних журналів, але джерела даних налаштовуються, тому Flume можна використовувати для транспортування величезної кількості даних, включаючи, але не обмежуючись ними, повідомлення електронної пошти, дані, що генеруються в соціальних медіа, дані про мережевий трафік і багато іншого можливе джерело даних.
Архів архітектури: - Архів архітектури базується на багатьох основних концепціях:
- Flume Event - він представлений як одиниця потоку даних, що має байтовий набір і набір рядків з необов'язковими заголовками рядків. Flume вважає подію просто загальним байтом.
- Flume Agent - це процес JVM, в якому розміщуються такі компоненти, як канали, раковина та джерела. Він має потенціал приймати, зберігати та пересилати події із зовнішнього джерела на наступний рівень.
- Flume Flow - це момент часу, коли подія створюється.
- Flume Client - це посилання на інтерфейс, де клієнт працює в точці початку події та доставляє його агенту Flume.
- Джерело - Джерело - це те, що споживає події, що мають певний формат, і доставляє їх за допомогою певного механізму.
- Канал - це пасивний магазин, де проводяться заходи, поки раковина не прибере її для подальшого транспортування.
- Раковина - Вилучає подію з каналу та розміщує її у зовнішньому сховищі, наприклад, HDFS. В даний час він підтримує створення текстових та послідовних файлів та підтримує стиснення обох типів файлів.
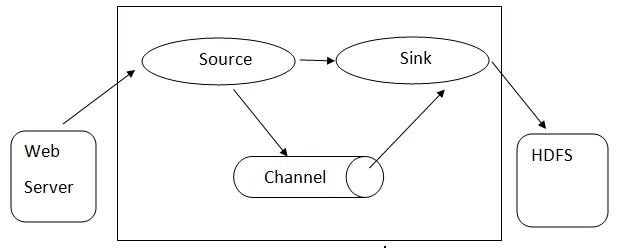
Архітектура Flume
Порівняння «голова до голови» між Sqoop проти Flume (Інфографіка)
Нижче представлено найкраще 7 порівняння між Sqoop і Flume

Ключові відмінності між Sqoop і Flume
Зараз ми знаємо, що між Sqoop і Flume існує багато відмінностей, ось найважливіші відмінності між ними наведені нижче -
1. Sqoop призначений для обміну масовою інформацією між Hadoop та реляційною базою даних.
Тоді як Flume використовується для збору даних з різних джерел, які генерують дані щодо конкретного випадку використання, а потім передають цей великий обсяг даних з розподілених ресурсів в єдине централізоване сховище.
2. Sqoop також включає набір команд, який дозволяє оглянути базу даних, з якою ви працюєте. Таким чином, ми можемо розглядати Sqoop як сукупність відповідних інструментів.
Під час збору дати Flume масштабує дані по горизонталі, і кілька агентів Flume можуть бути введені в дію для збору дати та їх агрегації. Після цього журнали даних переміщуються до централізованого сховища даних, тобто розподіленої файлової системи Hadoop (HDFS).
3. Основним фактором використання Flume є те, що дані повинні генеруватися безперервно та потоково. Так само Sqoop найкраще підходить у ситуаціях, коли ваші дані живуть у системах баз даних, таких як MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (Порівняльна таблиця)
| Основа для порівняння | SQOOP | ПОЛІВ |
|
Основна природа | Sqoop добре працює з будь-якими RDBMS, які мають JDBC (Java Database Connectivity), як Oracle, MySQL, Teradata тощо. | Flume добре працює для потокового джерела даних, який постійно генерує такі, як журнали, JMS, каталог, звіти про збої тощо. |
| Потік даних | Sqoop спеціально використовується для паралельної передачі даних. З цієї причини вихід може бути в декількох файлах | Flume використовується для збору та агрегації даних через розподілений характер. |
| Керовані події | Sqoop не керується подіями. | Flume повністю керований подіями. |
| Архітектура | Sqoop дотримується архітектури, що базується на роз'ємах, а це означає, що з'єднувачі знають, як підключитися до іншого джерела даних. | Flume дотримується архітектури на основі агентів, де написаний в ньому код відомий як агент, який відповідає за отримання даних. |
| Де використовувати | В основному використовується для швидшого копіювання даних, а потім їх використання для отримання аналітичних результатів. | Зазвичай використовується для отримання даних, коли компанії хочуть аналізувати шаблони, основні причини чи аналіз настроїв за допомогою журналів та соціальних медіа. |
| Продуктивність | Це знижує надмірні навантаження та обробку, переносячи їх на інші системи, та має швидку продуктивність. | Flume є стійким до відмов, надійним і має надійний механізм надійності для відмови та відновлення. |
| Історія випусків | Перша версія Apache Sqoop була запущена в березні 2012 року. Поточний стабільний реліз - 1.4.7 | Перша стабільна версія 1.2.0 Apache Flume була запущена в червні 2012 року. Поточний стабільний реліз - Apache Flume Version 1.8.0. |
Висновок - Sqoop проти Flume
Як ви дізналися вище Sqoop і Flume, в основному використовуються два інструменти прийому даних - це світ великих даних. Якщо вам потрібно передавати текстові дані журналу в Hadoop / HDFS, Flume - це правильний вибір для цього. Якщо ваші дані не генеруються регулярно, Flume все ще працюватиме, але це буде надмірним для цієї ситуації. Так само Sqoop не найкраще підходить для обробки даних, керованих подіями.
Рекомендовані статті
Це було керівництвом щодо відмінностей між Sqoop проти Flume, їх значенням, порівнянням між головами, ключовими відмінностями, таблицею порівняння та висновком. Ця стаття складається з усіх корисних відмінностей між Sqoop та Flume. Ви також можете переглянути наступні статті, щоб дізнатися більше
- Хадоп проти Терадата - Корисні відмінності для навчання
- 5 Найважливіша різниця між Apache Kafka і Flume
- Big Data vs Apache Hadoop - Топ-4 порівняння, які ви повинні навчитися
- 5 Найважливіша різниця між Apache Kafka і Flume
- Важлива розробка тексту та обробка природних мов - топ-5 порівнянь