

Введення в обмін даними
Тут, у цій статті, ми збираємось дізнатися про вступ до видобутку даних, оскільки люди століттями видобувають із землі, щоб отримати всілякі цінні матеріали. Іноді під час видобутку речі виявляються із землі, яку ніхто не очікував знайти в першу чергу. Наприклад, у 1898 р. Під час розкопок гробниці з метою пошуку мумій у Саккарі, Єгипет, було знайдено дерев’яний артефакт, який точно нагадував літак. Він був датований 200 роками до нашої ери, приблизно 2200 років тому! Але яку можливу інформацію ми могли б отримати з великого набору даних? І навіть якщо ми розпочнемо його розробляти, чи є шанси отримати якісь несподівані результати з набору даних? Перед цим давайте розберемося, що саме таке Data Mining.
Що таке майнінг даних?
- Це в основному вилучення життєво важливої інформації / знань з великого набору даних.
- Розгляньте дані як велику ґрунтову / скелясту поверхню. Ми не знаємо, що знаходиться всередині нього, ми не знаємо, чи є щось корисне під скелями.
- У цьому вступі до пошуку даних ми шукаємо приховану інформацію, але, не маючи уявлення про те, який тип інформації ми хочемо знайти і що ми плануємо використати, ми знаходимо її.
- Як і в традиційному майнінгу, і в Data mining також існують різні методи та інструменти, які залежать від типу даних, які ми видобуваємо, тому ми зрозуміли, що таке обмін даними через цю тему вступу до обміну даними.
Приклад обміну даними
Ми дізналися про введення в обробку даних у розділі вище, а зараз переходимо до прикладів пошуку даних, які наведені нижче:
- Отже, є оператор мобільної мережі. Вони консультуються з Data Miner для запису в записи викликів оператора. Мінеру даних не визначено конкретних цілей.
- Дано кількісну ціль пошуку щонайменше 2 нових моделей за місяць.
- Коли майнер даних починає копати дані, він виявляє схему, що в середу є менше міжнародних дзвінків порівняно з іншими днями.
- Цією інформацією ділиться з керівництвом, і вони придумують план зниження тарифів на міжнародні дзвінки в середу та розпочати кампанію.
- Вартість дзвінків зростає, клієнти задоволені низькою ціною дзвінків, більше клієнтів підписується і компанія заробляє більше грошей! Безпрограшна ситуація!
Маючи на увазі наведений вище приклад, давайте тепер розглянемо різні етапи, пов'язані з обробкою даних.
Етапи, що беруть участь у пошуку даних
Ми дізналися про введення в обробку даних у наведеному вище розділі і тепер рухаємося вперед із кроками, пов'язаними з обробкою даних, які наведені нижче: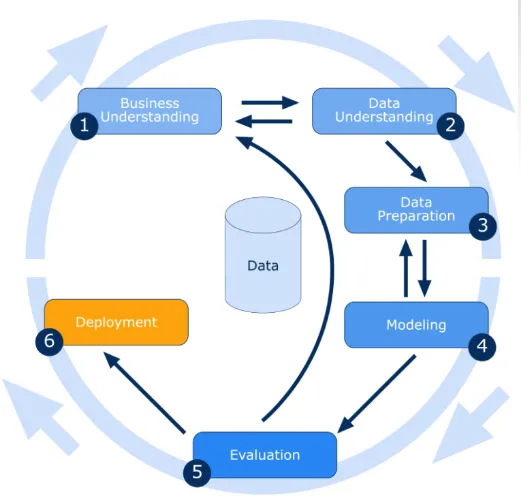
-
Розуміння бізнесу
У цьому вступі до пошуку даних ми зрозуміємо кожен аспект бізнес-цілей та потреб. Поточна ситуація оцінюється шляхом пошуку ресурсів, припущень та інших важливих факторів. Відповідно, створення належного ознайомлення з планом видобутку даних для досягнення як бізнес, так і цілей видобутку даних.
-
Розуміння даних
Спочатку дані збираються з усіх доступних джерел. Тоді ми вибираємо найкращий набір даних, звідки ми можемо витягти дані, які можуть бути кориснішими.
-
Підготовка даних
Після ідентифікації набору даних він вибирається, очищається, будується та відформатовується у потрібній формі.
-
Моделювання даних
Це процес ремоделювання заданих даних відповідно до вимог користувача. на підготовленому наборі даних можна створити одну або кілька моделей, і нарешті, моделі повинні бути ретельно оцінені із залученням зацікавлених сторін, щоб переконатися, що створені моделі відповідають бізнес-ініціативам.
-
Оцінка
Це один із найнеобхідніших процесів у видобутку даних. Він включає проходження кожного аспекту процесу, щоб перевірити можливі несправності чи витоки даних у процесі. Також нові вимоги бізнесу можуть бути підвищені завдяки виявленим новим моделям.
-
Розгортання
Це означає просто представити знання таким чином, щоб зацікавлені сторони могли його використовувати, коли вони цього хочуть. У нашому вище прикладі було встановлено, що міжнародних дзвінків по середах менше, тому ця інформація була представлена зацікавленим сторонам, які в свою чергу використовували цю інформацію на свою користь та збільшували свій прибуток.
Методи, що застосовуються при обробці даних
У наведеному вище розділі ми дізналися про введення в обмін даними, і тепер ми переходимо до тих методів, які використовуються в обробці даних, які наведені нижче:
-
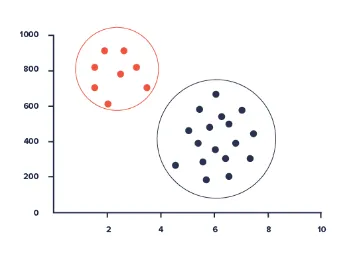
Кластерний аналіз
Кластерний аналіз дозволяє ідентифікувати дану групу користувачів відповідно до загальних особливостей у базі даних. Ці ознаки можуть включати вік, географічне положення, рівень освіти тощо.
-
Виявлення аномалії
Він використовується для визначення, коли щось помітно відрізняється від звичайного шаблону. Він використовується для усунення будь-яких невідповідностей або аномалій бази даних у джерелі.

-
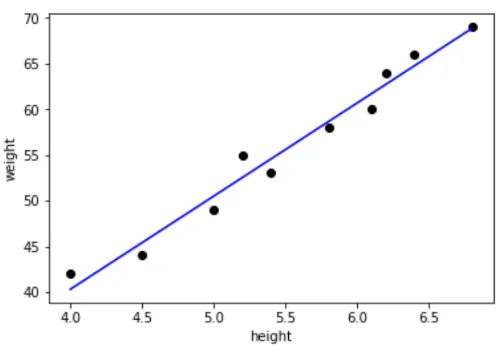
Регресійний аналіз
Ця методика використовується для прогнозування на основі взаємозв'язків у наборі даних. Наприклад, можна передбачити курс акцій певного товару, проаналізувавши минулу ставку, а також врахувавши різні фактори, що визначають ставку акцій. Або як показано нижче, якщо ми маємо дані про зріст і вагу різних осіб, то з огляду на будь-який зріст або вагу ми могли б визначити інше значення.
-
Класифікація
Це стосується речей, на яких є етикетки. Зауважимо, що при виявленні кластерів у речей не було мітки, і за допомогою використання даних ми повинні були мітити та сформувати в кластери, але в класифікації існує інформація, яку можна легко класифікувати за допомогою алгоритму. Прикладом є фільтри спаму в електронній пошті. Фільтр спаму надається як відповідними, так і повідомленнями про спам (Дані про навчання). Відмінність між ними обох ідентифікується, що дозволяє їй правильно класифікувати майбутні електронні листи.

- Асоціативне навчання
Він використовується для аналізу того, які речі мають тенденцію відбуватися разом або в парах, або в більших групах. Наприклад, люди, які схильні купувати лимони, також купують апельсини, люди, які схильні купувати хліб, теж купують молоко тощо. Таким чином, аналізуються закупівлі, здійснені всіма замовниками, і речі, які відбуваються разом, розташовуються поруч, щоб збільшити продажі. Так молоко кладуть близько до хліба, лимони розміщують поряд з апельсинами тощо.

Чи є обмін даними етичним?
Отже, я планую поїздку на вихідні до Гоа з другом, шукаю в Інтернеті гарні місця для відвідування в Гоа. Наступного разу, коли я відкриваю Інтернет, я знаходжу оголошення про різні готелі в Гоа для проживання.
-
Гарна річ?
Так, Інтернет допоміг мені спростити свою поїздку. Зрештою, якщо я все-таки вирішу відвідати Гоа, мені потрібно буде десь поспати, і реклама, що показує мені готель, набагато корисніша, ніж реклама, що показує мені випадковий одяг, щоб купити.
-
Погана річ?
Так! Чому компанія з пошуку даних, про яку я ніколи не чув, знала, куди їду у відпустку. Що робити, якщо я нікому не розповідав про цю поїздку, але тут Інтернет раптом знає, що я туди їду. Правда, від цього залежить бізнес-модель компанії з обміну даними. Вони збирають ці дані за допомогою файлів cookie та сценаріїв, потім продають їх рекламодавцям, які, у свою чергу, намагаються продати мені щось інше (У цьому випадку номер в готелі).
Тож це може бути добре чи погано залежно від того, як ми на це дивимось. Крім того, ми завжди могли вимкнути файли cookie або перейти в режим анонімного перегляду у наведеному вище випадку. Хоча як би там не було, одна річ - це точно. Дані даних тут залишаються.
Рекомендовані статті
Це було керівництвом щодо введення в обмін даними. Тут ми обговорюємо його значення, методи та кроки, пов'язані із впровадженням в обмін даними на прикладі, щоб зрозуміти краще. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Питання для інтерв'ю з інтелектуальною інформацією
- Прогнозована аналітика порівняно з майном даних
- Вступ до наукових даних
- Що таке регресійний аналіз?