

Різниця між MapReduce та Spark
Map Reduce - це рамка з відкритим кодом для запису даних у HDFS та обробки структурованих та неструктурованих даних, наявних у HDFS. Зменшення карт обмежено пакетною обробкою, а на інших Spark можна виконати будь-який тип обробки. SPARK - це незалежна обробна система для обробки в режимі реального часу, яка може бути встановлена в будь-якій системі розподілених файлів, наприклад Hadoop. SPARK забезпечує продуктивність, яка в 10 разів швидша, ніж зменшення карти на диску, і в 100 разів швидше, ніж зменшення карти в мережі в пам'яті.
Need for SPARK
- Ітеративна аналітика: Зниження карт не настільки ефективно, як СПАРК для вирішення проблем, які потребують ітеративної аналітики, оскільки вона має перейти на диск для кожної ітерації.
- Інтерактивна аналітика: зменшення карт часто використовується для запуску спеціальних запитів, для яких потрібно потрапити на дискову пам’ять, яка знову ж таки не є такою ефективною, як SPARK, тому що останній посилається на швидку пам'ять.
- Не підходить для OLTP: Оскільки він працює на пакетно-орієнтованій основі, він не підходить для великої кількості коротких транзакцій.
- Не підходить для графіка: бібліотека Apache Graph обробляє графік, що додає більшої складності зменшенню карти.
- Не підходить для тривіальних операцій. Для таких операцій, як фільтр та з'єднання, нам може знадобитися перезаписати завдання, що стає складнішим з-за шаблону ключа-значення.
Порівняння «голова до голови» між MapReduce і Spark (Інфографіка)
Нижче наведено топ-15 Різниця між MapReduce та Spark

Основні відмінності між MapReduce і Spark
Нижче наведено списки пунктів, опишіть ключові відмінності між MapReduce та Spark:
- Іскра підходить у режимі реального часу, оскільки вона обробляє за допомогою пам'яті, тоді як MapReduce обмежений пакетною обробкою.
- Spark має RDD (Resilient Distributed Dataset), що дає нам операторів високого рівня, але у зменшенні Map нам потрібно кодувати кожну операцію, що робить її порівняно важкою.
- Іскра може обробляти графіки та підтримує інструмент машинного навчання.
- Нижче наведена різниця між екосистемою MapReduce проти Spark.
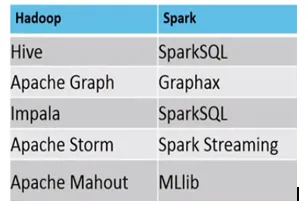
Приклад, де MapReduce проти Spark підходить, є наступним
Іскра: виявлення шахрайства на кредитній картці
MapReduce: Складання регулярних звітів, які потребують прийняття рішень.
Таблиця порівняння MapReduce vs Spark
| Основи порівняння | MapReduce | Іскра |
| Рамка | Рамка з відкритим кодом для запису даних у HDFS та обробки структурованих та неструктурованих даних, присутніх у HDFS. | Рамка з відкритим кодом для швидшої та загальної цільової обробки даних |
| Швидкість | Зменшити на карті обробляти дані (читання та записування) з диска, щоб просочення було повільним порівняно з Spark. | Іскра на диска принаймні на 10 разів швидша і на 100 разів швидша в пам'яті, ніж у зменшенні карт. |
| Складність | Нам потрібно кодувати / обробляти кожен процес. | З наявністю RDD (Resilient Distributed Dataset) програмувати легко. |
| Реальний час | Не підходить для транзакцій OLTP лише для пакетного режиму | Він може обробляти обробку в режимі реального часу. Використання SPARK Streaming. |
| Затримка | Система обчислень затримки високого рівня | Низький рівень затримки обчислювальної системи. |
| Відмовостійкість | Демони-майстри перевіряють серцебиття демонів-рабів, і якщо демони-раби не вдається, майстри-демони перенесуть усі очікувані та перебувають в операції на іншого раба. | RDD забезпечують відмову до SPARK. Вони посилаються на набір даних, наявний у зовнішніх сховищах (HDFS, HBase) і працюють паралельно. |
| Планувальник | У режимі зменшення карт ми використовуємо зовнішній планувальник, наприклад, Oozie. | Оскільки SPARK працює з обчисленнями в пам'яті, він виступає як власний планувальник. |
| Вартість | Зниження карт порівняно дешевше порівняно зі SPARK. | Оскільки він працює в пам'яті, тому він вимагає багато оперативної пам’яті, що робить його порівняно більш дорогим. |
| Платформа, розроблена на | Зменшення карт було розроблено за допомогою Java. | SPARK був розроблений за допомогою Scala. |
| Підтримується мова | Карта зменшення в основному підтримує C, C ++, Ruby, Groovy, Perl, Python. | Іскра підтримує Scala, Java, Python, R, SQL. |
| Підтримка SQL | Зменшити запуск запущених запитів за допомогою мови запитів Hive. | Spark має власну мову запитів, відому як Spark SQL. |
| Масштабованість | У зменшенні карт ми можемо додати до n кількості вузлів. Найбільший кластер Hadoop має 14000 вузлів. | У Spark також ми можемо додати n кількість вузлів. Найбільший кластер Spark має 8000 вузлів. |
| Машинне навчання | Map Reduce підтримує інструмент Apache Mahout для машинного навчання. | Spark підтримує MLlib інструмент для машинного навчання. |
| Кешування | Зниження карти не в змозі кешувати дані пам'яті, тому її не так швидко, як порівняно з Spark. | Spark кешує дані в пам'яті для подальших ітерацій, тому її дуже швидко порівняно зі зменшенням карти. |
| Безпека | Map Reduce підтримує більше проектів та функцій безпеки порівняно зі Spark | Захищеність від іскри ще не визріло, оскільки знизилася карта |
Висновок - MapReduce проти Spark
Згідно з наведеною вище різницею між MapReduce та Spark, цілком очевидно, що SPARK є набагато більш просунутим обчислювальним двигуном порівняно із зменшенням карт. Іскра сумісна з будь-яким типом формату файлів, а також досить швидше, ніж зменшення карти. Крім того, іскра має також можливості обробки графіків та можливостей машинного навчання.
З одного боку, зменшення карт обмежується пакетною обробкою, а з іншого Spark може виконувати будь-який тип обробки (пакетна, інтерактивна, ітеративна, потокова, графічна). Завдяки великій сумісності Spark є улюбленцем Data Scientist, а отже, його заміна Map зменшується та швидко зростає. Але все ж нам потрібно зберігати дані в HDFS, і нам також десь може знадобитися HBase. Тому нам потрібно запустити і Спарк, і Hadoop, щоб отримати найкраще.
Рекомендовані статті:
Це було керівництвом щодо MapReduce vs Spark, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- 7 важливих речей про Apache Spark (Керівництво)
- Hadoop vs Apache Spark - цікаві речі, які потрібно знати
- Apache Hadoop vs Apache Spark | Топ-10 порівнянь, які ти повинен знати!
- Як працює MapReduce?
- Злиття технології та бізнес-аналітики