

Вступ до лінійного регресійного аналізу
Часто заплутано вивчати якесь поняття, яке навіть є частиною нашого повсякденного життя. Але це не проблема, ми можемо допомогти та розвинутись, щоб навчитися нашої повсякденної діяльності, просто проаналізувавши речі і не боячись задавати питання. Чому ціна впливає на попит на товари, чому зміна процентної ставки впливає на пропозицію грошей. На все це можна відповісти простим підходом, відомим як лінійна регресія. Єдина складність, яку відчуваєш при роботі з лінійним регресійним аналізом, - виявлення залежних та незалежних змінних.
Ми повинні знайти, що впливає на що, і половина проблеми вирішена. Ми маємо побачити, чи впливає ціна на попит чи ціну на поведінку один одного. Після того, як ми дізналися, яка з них є незалежною та залежною змінною, ми добре піти на аналіз. Існує кілька типів регресійного аналізу. Цей аналіз залежить від доступних нам змінних.
3 типи регресійного аналізу
Ці три регресійні аналізи мають максимум випадків використання в реальному світі, інакше існує більше 15 типів регресійного аналізу. Типи регресійного аналізу, які ми будемо обговорювати:
- Лінійний регресійний аналіз
- Множинний лінійний регресійний аналіз
- Логістична регресія
У цій статті ми зупинимось на простому лінійному регресійному аналізі. Цей аналіз допомагає нам виявити зв’язок між незалежним фактором та залежним фактором. Простішими словами, модель регресії допомагає нам виявити, як зміни незалежного фактора впливають на залежний фактор. Ця модель допомагає нам кількома способами, такими як:
- Це проста і потужна статистична модель
- Це допоможе нам зробити прогнози та прогнози
- Це допоможе нам прийняти краще бізнес-рішення
- Це допоможе нам проаналізувати результати та виправити помилки
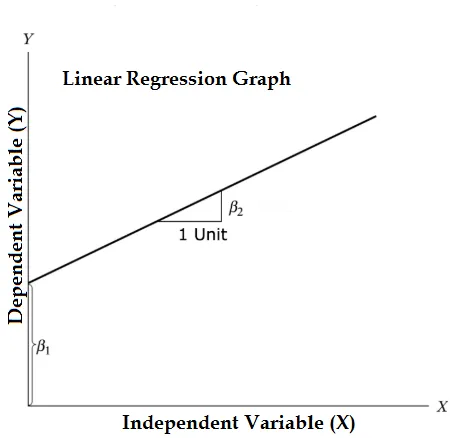
Рівняння лінійної регресії та розділити її на відповідні частини
Y = β1 + β2X + ϵ
- Де β1 в математичній термінології відомий як перехоплення і β2 в математичній термінології відомий як нахил. Вони також відомі як коефіцієнти регресії. ϵ - термін помилки, це частина Y регресійної моделі неможливо пояснити.
- Y - залежна змінна (інші терміни, які взаємозамінно використовуються для залежних змінних, - це змінна відповідь, регрес і вимірювана змінна, спостерігається змінна, відповідна змінна, пояснена змінна, змінна результат, експериментальна змінна та / або вихідна змінна).
- X - незалежна змінна (регресори, керована змінна, керована змінна, пояснювальна змінна, змінна експозиція та / або вхідна змінна).
Проблема: Для розуміння того, що таке лінійний регресійний аналіз, ми беремо набір даних "Автомобілі", який за замовчуванням надходить у каталогах R. У цьому наборі даних є 50 спостережень (в основному рядки) та 2 змінні (стовпці). Назви стовпців - “Dist” та “Speed”. Тут ми маємо побачити вплив на змінні відстані через змінні швидкості змін. Щоб побачити структуру даних, ми можемо запустити код Str (набір даних). Цей код допомагає нам зрозуміти структуру набору даних. Ці функції допомагають нам приймати кращі рішення, оскільки ми маємо кращу картину щодо структури набору даних. Цей код допомагає нам визначити тип наборів даних.
Код:

Аналогічно для перевірки статистичних контрольних точок набору даних ми можемо використовувати код Підсумок (машини). Цей Кодекс надає середній, середній, діапазон набору даних на ходу, який дослідник може використовувати під час вирішення проблеми.
Вихід:
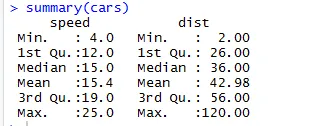
Тут ми можемо побачити статистичний вихід кожної змінної у нашому наборі даних.
Графічне представлення наборів даних
Типи графічного зображення, яке буде висвітлено тут, є і чому:
- Графік розсіювання: За допомогою графіка ми можемо побачити, в якому напрямку рухається наша модель лінійної регресії, чи є якісь вагомі докази, що підтверджують нашу модель чи ні.
- Сюжетна скринька: допомагає нам знайти людей, що вижили.
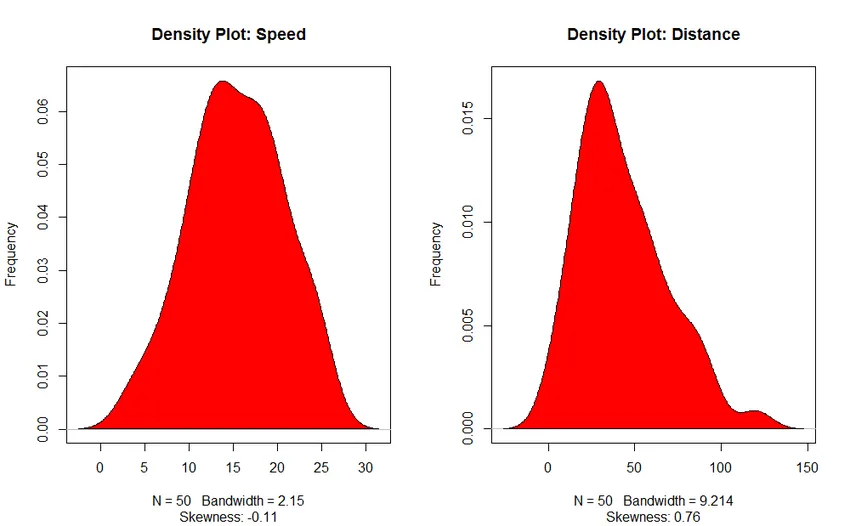
- Діаграма щільності: Допоможіть нам зрозуміти розподіл незалежної змінної, в нашому випадку незалежною змінною є “Швидкість”.
Переваги графічного зображення
Тут є такі переваги:
- Легко зрозуміти
- Допомагає нам швидко прийняти рішення
- Порівняльний аналіз
- Менше зусиль та часу
1. Графік розсіювання: Він допоможе візуалізувати будь-які зв’язки між незалежною змінною та залежною змінною.
Код:

Вихід:
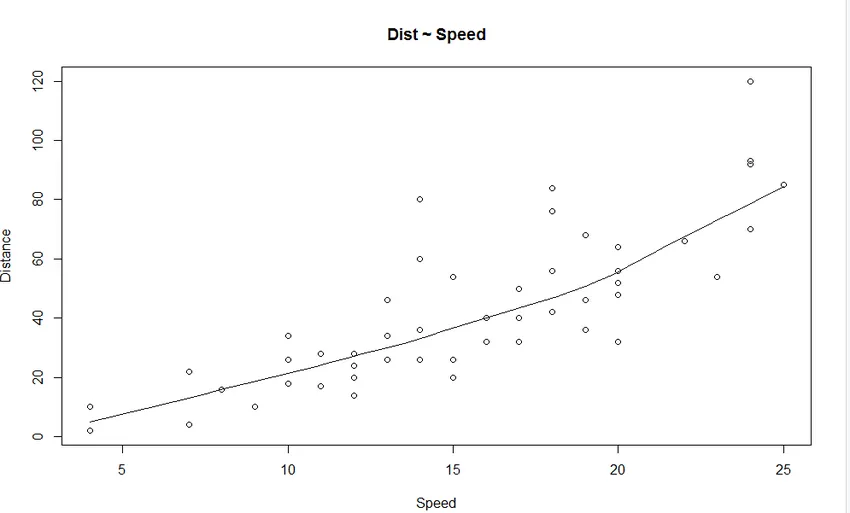
З графіка ми бачимо лінійно зростаючу залежність між залежною змінною (Відстань) і незалежною змінною (Швидкість).
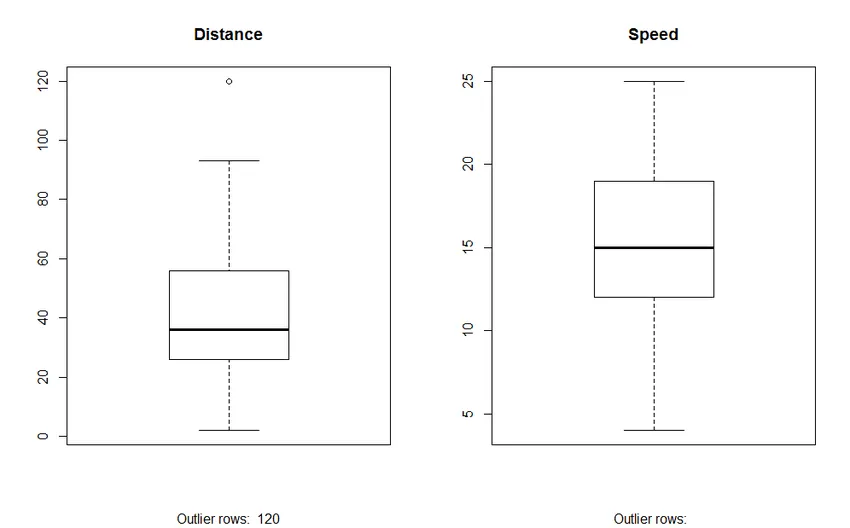
2. Сюжетна скринька: Сюжетна скринька допомагає нам ідентифікувати людей, що випадають у наборах даних. Перевагами використання коробкової ділянки є:
- Графічне відображення розташування та поширення змінних.
- Це допомагає нам зрозуміти стислість та симетричність даних.
Код:

Вихід:
3. Діапазон щільності (для перевірки нормальності розподілу)
Код:
 Вихід:
Вихід:
Кореляційний аналіз
Цей аналіз допомагає нам знайти зв’язок між змінними. В основному існує шість типів кореляційного аналізу.
- Позитивна кореляція (0, 01 до 0, 99)
- Негативна кореляція (-0, 99 до -0, 01)
- Ніякої кореляції
- Ідеальна кореляція
- Сильна кореляція (значення ближче до ± 0, 99)
- Слабка кореляція (значення ближче до 0)
Графік розсіювання допомагає нам визначити, які типи наборів даних кореляції є серед них і код для знаходження кореляції

Вихід:
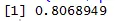
Тут ми маємо сильну позитивну кореляцію між Швидкістю та Відстані, що означає, що вони мають прямий зв’язок між ними.
Модель лінійної регресії
Це основний компонент аналізу, раніше ми просто намагалися перевірити, чи є у нас набір даних достатньо логічним для виконання такого аналізу чи ні. Функція, яку ми плануємо використовувати, - lm (). Ця функція містить два елементи, які є формулою та даними. Перш ніж призначити, яка змінна залежна чи незалежна, ми повинні бути дуже впевнені в цьому, оскільки від цього залежить вся наша формула.
Формула виглядає приблизно так,
Лінійна регресія <- lm (залежна змінна ~ незалежна змінна, дані = дата. Кадр)
Код:

Вихід:
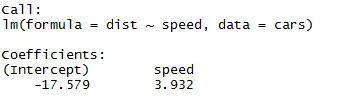
Як ми можемо згадати з наведеного сегмента статті, рівняння лінійної регресії є:
Y = β1 + β2X + ϵ
Тепер ми впишемося в інформацію, яку ми отримали з наведеного вище коду в цьому рівнянні.
dist = −17.579 + 3.932 ∗ швидкість
Тільки знаходження рівняння лінійної регресії недостатньо, ми також повинні перевірити його статистичну значимість. Для цього нам потрібно передати код «Підсумок» на нашій моделі лінійної регресії.
Код:

Вихід:

Існує кілька способів перевірки статистичної значущості моделі, тут ми використовуємо метод P-значення. Ми можемо вважати модель статистично придатною, коли значення Р менше, ніж заздалегідь визначений статистично значимий рівень, який в ідеалі становить 0, 05. Ми можемо побачити в нашій таблиці підсумків (linear_regression), що значення P знаходиться нижче рівня 0, 05, тому ми можемо зробити висновок, що наша модель є статистично значимою. Як тільки ми впевнені у своїй моделі, ми можемо використовувати наш набір даних для прогнозування речей.
Рекомендовані статті
Це посібник з лінійного регресійного аналізу. Тут ми обговорюємо три типи лінійного регресійного аналізу, графічне представлення наборів даних із перевагами та лінійні регресійні моделі. Ви також можете ознайомитись з іншими пов'язаними з нами статтями, щоб дізнатися більше -
- Формула регресії
- Регресійне тестування
- Лінійна регресія в R
- Типи методів аналізу даних
- Що таке регресійний аналіз?
- Основні відмінності регресії від класифікації
- Топ-6 відмінностей лінійної регресії від логістичної регресії