
Вступ до Пуассонової регресії в R
Пуассонова регресія - це тип регресії, подібний до множинної лінійної регресії, за винятком того, що відповідь або залежна змінна (Y) є змінною кількістю. Залежна змінна слід за розподілом Пуассона. Прогноз або незалежні змінні можуть мати суцільний або категоричний характер. Певним чином це схоже на логістичну регресію, яка також має дискретну змінну реакції. Попереднє розуміння розподілу Пуассона та його математичної форми дуже важливо, щоб використовувати його для прогнозування. В R регресія Пуассона може бути реалізована дуже ефективно. R пропонує повний набір функціональних можливостей для його реалізації.
Реалізація Пуассонової регресії
Зараз ми продовжимо розбиратися в застосуванні моделі. У наступному розділі подано покрокову процедуру для того ж. Для цієї демонстрації ми розглядаємо "гала" набір даних з пакету "далекий". Це стосується видового різноманіття на островах Галапагоські острови. У наборі даних є 7 змінних. Ми будемо використовувати регресію Пуассона, щоб визначити залежність між кількістю видів рослин (видів) з іншими змінними в наборі даних.
1. Спочатку завантажте "далекий" пакет. У випадку, якщо пакета немає, завантажте його за допомогою функції install.packages ().
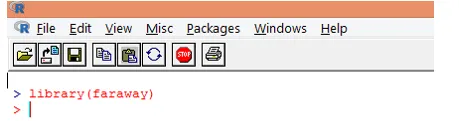
2. Після завантаження пакета завантажте "гала" набір даних у R за допомогою функції data (), як показано нижче.
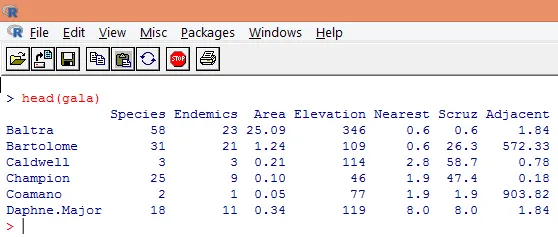
3. Завантажені дані слід візуалізувати для вивчення змінної та перевірки, чи є розбіжності. Ми можемо візуалізувати або цілі дані, або лише перші кілька рядків, використовуючи функцію head (), як показано на скріншоті нижче.
4. Щоб отримати більш детальну інформацію про набір даних, ми можемо використовувати довідкову функцію в R, як показано нижче. Він генерує документацію R, як показано на скріншоті, наступному на скріншоті нижче.


5. Якщо ми вивчимо набір даних, як згадувалося в попередніх кроках, то можемо виявити, що види - це змінна відповідь. Зараз ми вивчимо основний підсумок змінних предиктора.
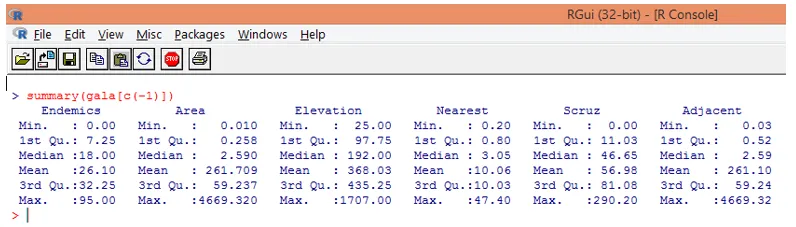
Зауважте, як видно вище, ми виключали змінну Вид. Функція підсумків дає нам основні уявлення. Просто поспостерігайте за медіанними значеннями для кожної з цих змінних, і ми зможемо виявити, що величезна різниця, з точки зору діапазону значень, існує між першою половиною та другою половиною, наприклад, для медіанного значення перемінної області дорівнює 2, 59, але максимальне значення - 4669.320.
6. Тепер, коли ми закінчилися з базовим аналізом, ми створимо гістограму для видів, щоб перевірити, чи відповідає змінна розподілу Пуассона. Це проілюстровано нижче.

Вищевказаний код генерує гістограму для змінної виду разом з кривою щільності, накладеною на неї.
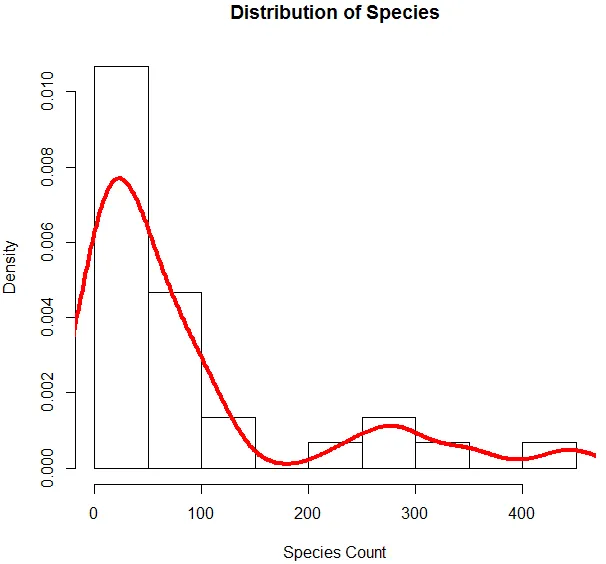
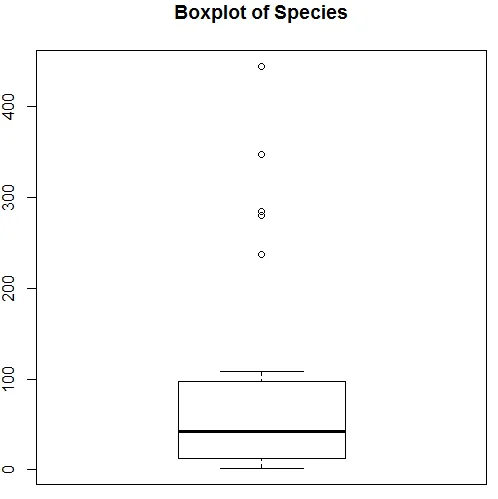
Наведена вище візуалізація показує, що види слідують за розповсюдженням Пуассона, оскільки дані перекошені вправо. Ми також можемо генерувати боксер, щоб отримати більш детальну інформацію про схему розподілу, як показано нижче.
7. Завершивши попередній аналіз, ми застосуємо регресію Пуассона, як показано нижче
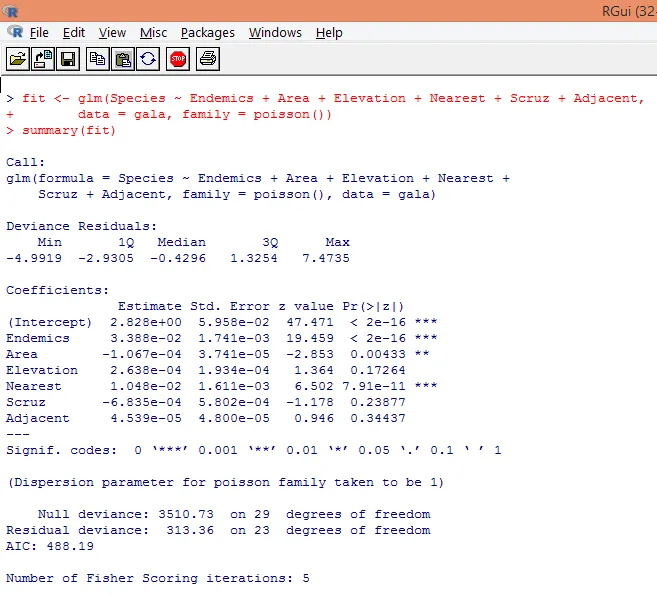
Виходячи з вищенаведеного аналізу, ми виявляємо, що змінні Ендеміка, Площа та Найближчі є вагомими і лише їх включення є достатнім для побудови правильної регресійної моделі Пуассона.
8. Ми побудуємо модифіковану регресійну модель Пуассона, беручи до уваги лише три змінні. Ендеміки, область та найближчі. Давайте подивимося, які результати ми отримаємо.
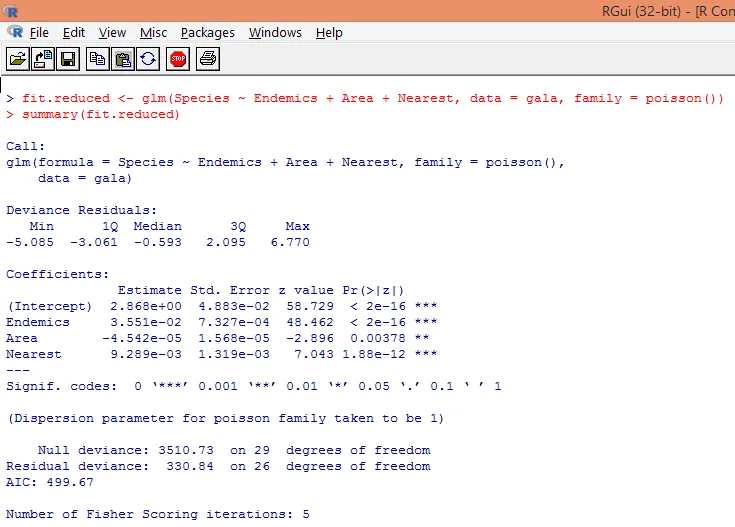
Вихід створює відхилення, параметри регресії та стандартні помилки. Ми можемо бачити, що кожен з параметрів є значущим на рівні p <0, 05.
9. Наступний крок - інтерпретація параметрів моделі. Модельні коефіцієнти можна отримати, досліджуючи Коефіцієнти у вищенаведеному виході, або використовуючи функцію coef ().
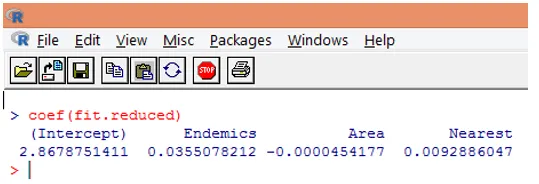
В регресії Пуассона залежна змінна моделюється як журнал умовного середнього ложу (l). Параметр регресії для ендеміків 0, 0355 вказує на те, що збільшення одиничної величини змінної пов'язане зі збільшенням на 0, 04 середнього числа журналу видів, утримуючи постійні інші змінні. Перехоплення - це середня кількість журнальних видів, коли кожен з предикторів дорівнює нулю.
10. Однак, інтерпретувати коефіцієнти регресії в оригінальній шкалі залежної змінної набагато простіше (кількість видів, а не кількість видів видів). Експоненція коефіцієнтів дозволить легко інтерпретувати. Робиться це наступним чином.
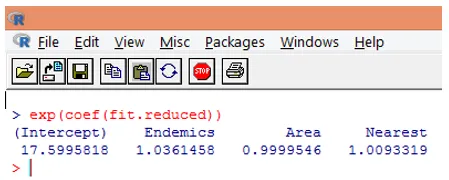
З вищенаведених висновків можна сказати, що один приріст площі збільшує очікувану кількість видів на 0, 9999, а на одиницю збільшення кількості ендемічних видів, представлених Ендеміком, примножує кількість видів на 1, 0361. Найважливіший аспект регресії Пуассона полягає в тому, що експонентовані параметри мають мультиплікативний, а не адитивний вплив на змінну відповіді.
11. Скориставшись вищезазначеними етапами, ми отримали регресійну модель Пуассона для прогнозування кількості видів рослин на островах Галапагоських островів. Однак, дуже важливо перевірити наявність завищ. У пуассоновій регресії дисперсія та засоби рівні.
Передисперсія виникає, коли спостережувана дисперсія змінної реакції більша, ніж було б передбачено розподілом Пуассона. Аналіз наддисперсії стає важливим, оскільки це є загальним для даних підрахунку, і може негативно вплинути на кінцеві результати. У R надмірність може бути проаналізована за допомогою пакету "qcc". Аналіз проілюстровано нижче.
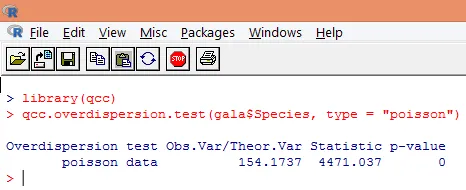
Наведений вище тест показує, що р-значення менше 0, 05, що настійно говорить про наявність наддисперсії. Ми спробуємо пристосувати модель за допомогою функції glm (), замінивши family = "Poisson" на family = "quasipoisson". Це проілюстровано нижче.
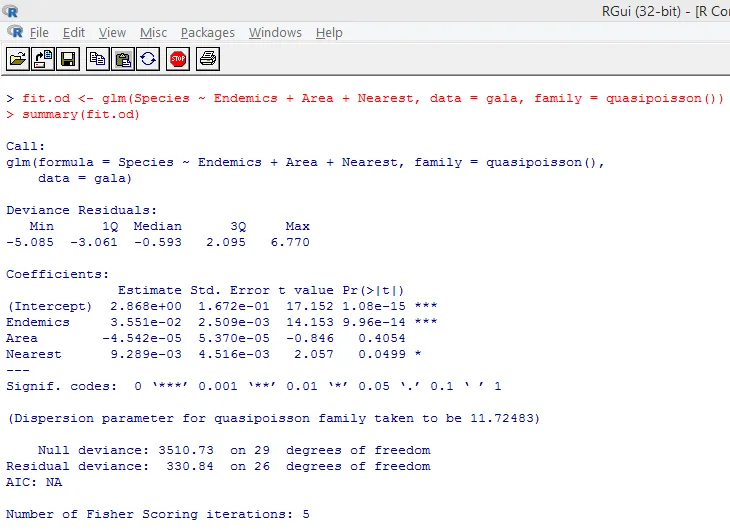
Уважно вивчивши наведений вище результат, ми можемо побачити, що оцінки параметрів у квазі-пуассонівському підході ідентичні тим, які виробляються підходом Пуассона, хоча стандартні помилки відрізняються для обох підходів. Більше того, у цьому випадку для Площі значення р перевищує 0, 05, що пояснюється більшою стандартною помилкою.
Важливість регресії Пуассона
- Регресія Пуассона в R корисна для правильних прогнозів дискретної / лічильної змінної.
- Це допомагає нам виявити ті пояснювальні змінні, які мають статистично значущий вплив на змінну відповідей.
- Регресія Пуассона в R найкраще підходить для подій "рідкісного" характеру, оскільки вони мають тенденцію слідувати розповсюдженню Пуассона, ніж проти звичайних подій, які зазвичай ідуть за нормальним розподілом.
- Він підходить для застосування у випадках, коли змінною відповіді є мале ціле число.
- Він має широке застосування, оскільки прогнозування дискретних змінних є вирішальним у багатьох ситуаціях. У медицині його можна використовувати для прогнозування впливу препарату на здоров'я. Він широко використовується в аналізі виживання, як загибель біологічних організмів, збій механічних систем тощо.
Висновок
Регресія Пуассона заснована на концепції розподілу Пуассона. Це ще одна категорія, що належить до набору методів регресії, що поєднує в собі властивості як лінійних, так і логістичних регресій. Однак, на відміну від логістичної регресії, яка генерує лише бінарний вихід, використовується для прогнозування дискретної змінної.
Рекомендовані статті
Це посібник з регресії Пуассона в Р. Тут ми обговорюємо вступ Реалізація Пуассонової регресії та важливість регресії Пуассона. Ви також можете ознайомитися з іншими запропонованими нами статтями, щоб дізнатися більше -
- GLM в R
- Генератор випадкових чисел в R
- Формула регресії
- Логістична регресія в R
- Лінійна регресія проти логістичної регресії | Основні відмінності