

Вступ до алгоритму AdaBoost
Алгоритм AdaBoost можна використовувати для підвищення продуктивності будь-якого алгоритму машинного навчання. Машинне навчання стало потужним інструментом, який дозволяє робити прогнози на основі великої кількості даних. Останнім часом він настільки набув популярності, що застосування машинного навчання можна знайти у повсякденній діяльності. Поширений приклад - отримання пропозицій щодо товарів під час покупок в Інтернеті на основі минулих предметів, придбаних замовником. Машинне навчання, яке часто називають прогнозним аналізом або прогнозним моделюванням, можна визначити як здатність комп'ютерів навчатися, не будуючи явно запрограмованих програм. Він використовує запрограмовані алгоритми для аналізу вхідних даних для прогнозування виходу у прийнятному діапазоні.
Що таке алгоритм AdaBoost?
У машинному навчанні стимулювання виникало з питання про те, чи можна набір слабких класифікаторів перетворити на сильний класифікатор. Слабкий учень або класифікатор - це той, хто краще, ніж випадкові здогадки, і це буде надійним при перенапруженні, як у великому наборі слабких класифікаторів, кожен слабкий класифікатор - кращий, ніж випадковий. Як слабкий класифікатор зазвичай використовується простий поріг для однієї функції. Якщо функція перевищує поріг, ніж було передбачено, вона належить до позитивного, інакше належить до негативного.
AdaBoost розшифровується як «Адаптивне підсилення», яке перетворює слабких учнів чи прогнозів на сильних прогнозів для вирішення проблем класифікації.
Для класифікації остаточне рівняння можна поставити так: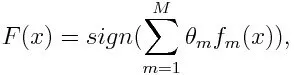
Тут f m позначає m- й слабкий класифікатор, а m позначає його відповідну вагу.
Як працює алгоритм AdaBoost?
AdaBoost можна використовувати для підвищення продуктивності алгоритмів машинного навчання. Він використовується найкраще із слабкими учнями, і ці моделі досягають високої точності вище випадкового шансу на проблему класифікації. Загальні алгоритми, що використовуються з AdaBoost, - це дерева рішень першого рівня. Слабкий учень - це класифікатор або предиктор, який з точки зору точності виконує відносно погані показники. Крім того, можна зрозуміти, що слабких учнів просто обчислити, і багато примірників алгоритмів поєднуються, щоб створити сильний класифікатор шляхом підвищення.
Якщо ми беремо набір даних, що містить n кількість точок, і розглянемо нижче
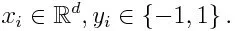
-1 являє собою негативний клас, а 1 означають позитивний. Він ініціалізується як нижче, вага для кожної точки даних:
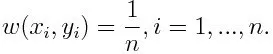
Якщо розглядати ітерацію від 1 до M для m, отримаємо вираз нижче:
По-перше, ми повинні вибрати слабкий класифікатор з найнижчою зваженою помилкою класифікації, встановивши слабкі класифікатори до набору даних.
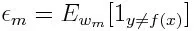
Потім обчислюємо вагу для m- го слабкого класифікатора, як показано нижче:
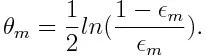
Вага позитивна для будь-якого класифікатора з точністю вище 50%. Вага стає більшим, якщо класифікатор є більш точним і він стає негативним, якщо класифікатор має точність менше 50%. Передбачення можна поєднати, перевернувши знак. Інвертуючи знак передбачення, класифікатор з 40% точністю може бути перетворений на 60% точність. Тож класифікатор сприяє остаточному прогнозуванню, навіть якщо він виконує гірше, ніж випадкові здогадки. Однак остаточний прогноз не внесе жодного внеску або отримає інформацію від класифікатора з точно 50% точністю. Експоненціальний доданок у чисельнику завжди більший за 1 для помилково віднесеного від класифікатора позитивного зваженого. Після ітерації випадки неправильної класифікації оновлюються з більшою вагою. Негативно зважені класифікатори поводяться однаково. Але є різниця, що після перевернення знака; правильні класифікації спочатку перетворювали б на неправильну класифікацію. Остаточний прогноз можна обчислити, враховуючи кожен класифікатор, а потім виконавши суму їх зваженого прогнозу.
Оновлення ваги для кожної точки даних, як показано нижче:
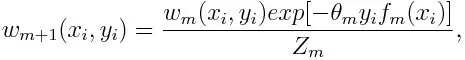
Z m тут коефіцієнт нормалізації. Це гарантує, що сума загальної ваги всіх екземплярів стає рівною 1.
Для чого використовується алгоритм AdaBoost?
AdaBoost може використовуватися для виявлення обличчя, оскільки, здається, це стандартний алгоритм розпізнавання облич у зображеннях. Він використовує каскад відхилення, що складається з багатьох шарів класифікаторів. Коли вікно виявлення не розпізнається на жодному шарі як обличчя, воно відхиляється. Перший класифікатор у вікні відкидає негативне вікно, зводячи обчислювальні витрати до мінімуму. Хоча AdaBoost поєднує слабкі класифікатори, принципи AdaBoost також використовуються для пошуку найкращих функцій для використання в кожному шарі каскаду.
Плюси і мінуси алгоритму AdaBoost
Однією з багатьох переваг алгоритму AdaBoost є те, що він швидко, просто і легко програмується. Крім того, він має гнучкість поєднуватись з будь-яким алгоритмом машинного навчання, і немає необхідності налаштовувати параметри, крім T. Він поширюється на проблеми навчання поза бінарною класифікацією, і він є універсальним, оскільки його можна використовувати з текстом або числовим числом дані.
AdaBoost також має мало недоліків, таких як емпіричні дані та особливо вразливі до рівномірного шуму. Занадто слабкий рівень класифікаторів може призвести до низької маржі та надмірного розміщення.
Приклад алгоритму AdaBoost
Ми можемо розглянути приклад прийому студентів до університету, де або приймуть, або відмовлять. Тут кількісні та якісні дані можна знайти з різних аспектів. Наприклад, результат прийому, який може бути так / ні, може бути кількісним, тоді як будь-яка інша сфера, як навички чи захоплення студентів, може бути якісною. Ми можемо легко створити правильну класифікацію навчальних даних за кращого шансу для таких умов, як, наприклад, якщо студент хороший у певному предметі, тоді він / він допускається. Але важко знайти високоточний прогноз, і тоді слабкі учні вступають у картину.
Висновок
AdaBoost допомагає у виборі навчального набору для кожного нового класифікатора, який навчається за результатами попереднього класифікатора. Також при поєднанні результатів; він визначає, яку вагу слід надати запропонованій відповіді кожного класифікатора. Він поєднує слабких учнів, щоб створити сильну для виправлення помилок класифікації, що також є першим успішним алгоритмом підвищення типових проблем класифікації.
Рекомендовані статті
Це було керівництвом до алгоритму AdaBoost. Тут ми обговорили з прикладом концепцію, використання, роботу, плюси та мінуси. Ви також можете ознайомитися з іншими запропонованими нами статтями, щоб дізнатися більше -
- Алгоритм наївного Байєса
- Питання для інтерв'ю з маркетингу соціальних медіа
- Стратегії побудови посилань
- Платформа маркетингу соціальних медіа