

Різниця між Apache Nifi іApache Spark
До тривалого часу, коли була важка робота, яку потрібно було завершити, люди покладалися на коней, щоб тягнути важкі вантажі, підтримувати швидкість або що-небудь інше між ними. Однак не всі коні підходили до кожного завдання. Те саме стосується сьогодні технологій. З появою нових технологій, що впроваджуються щодня, стає надзвичайно важливим знати їх реальне застосування. Дві такі технології - Apache Nifi та Apache Spark, і ми будемо вивчати їх у цій посаді.
Apache Spark - це кластерно-обчислювальна програма з відкритим кодом, яка має на меті створити інтерфейс для програмування всього набору кластерів із неявною відмовою від помилок та паралелізмом даних. Він використовує RDD (Resilient розподілених наборів даних) і обробляє дані у вигляді дискретизованих потоків, які надалі використовуються в аналітичних цілях.
Apache Nifi (це коротка форма NiagaraFiles) - ще один програмний проект, який спрямований на автоматизацію потоку даних між програмними системами. Дизайн базується на потоковій моделі програмування, яка забезпечує функції, що включають в себе роботу з можливістю кластерів. Це проста у користуванні, надійна та потужна система для обробки та поширення даних. Він підтримує масштабовані спрямовані графіки для маршрутизації даних, системного посередництва та логіки перетворення. Давайте обговоримо порівняння обох тем.
Порівняння між собою між Apache Nifi і Apache Spark (Інфографіка)
Нижче представлено 9 кращих порівнянь між Apache Nifi і Apache Spark
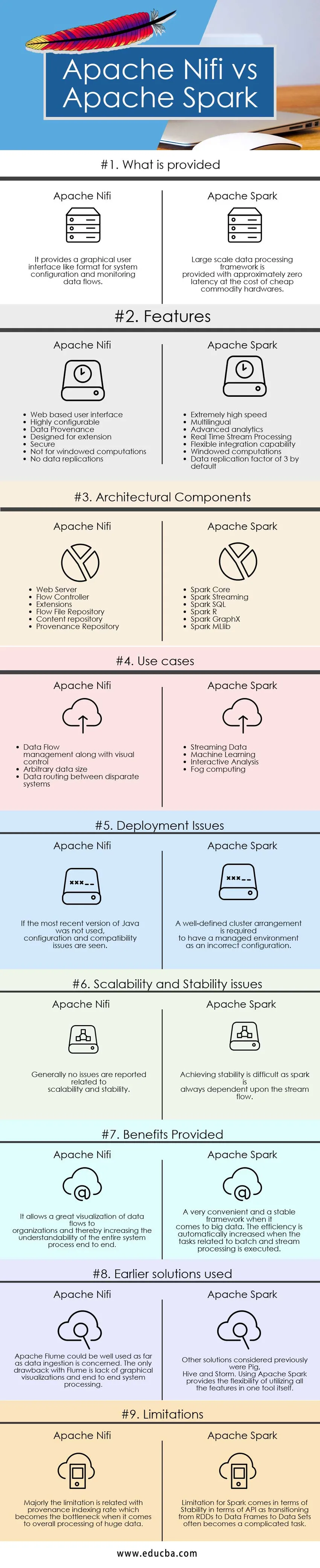
Основні відмінності між Apache Nifi і Apache Spark
Відмінності між Apache Nifi та Apache Spark пояснюються в пунктах, представлених нижче:
- Apache Nifi - це засіб прийому даних, який використовується для забезпечення простої у використанні, потужної та надійної системи, завдяки чому обробка та розподіл даних по ресурсам стає легкою, тоді як Apache Spark - надзвичайно швидка кластерна обчислювальна технологія, розроблена для швидшого обчислення ефективно використовувати інтерактивні запити, в управлінні пам’яттю та обробці потоків.
- Apache Nifi працює в автономному режимі і в кластерному режимі, тоді як Apache Spark добре працює в локальному або автономному режимах, Mesos, Пряжі та інших видах великих кластерних режимів даних.
- Особливості Apache Nifi включає гарантовану доставку даних, ефективну буферизацію даних, пріоритетну чергу чергування, поточний QoS, забезпечення даних, відновлення буфера рулону, візуальне командування та управління, шаблони потоків, безпеку, паралельні потокові можливості, тоді як функції апаш іскри включають блискавичну швидкість можливість швидкої обробки, багатомовна, обчислення в пам'яті, ефективне використання товарних апаратних систем, розширена аналітика, ефективна інтеграція.
- Apache Nifi дозволяє покращити читабельність та загальне розуміння системи, надаючи можливості візуалізації та функції перетягування. Потоком даних можна легко керувати та керувати за допомогою звичайних методів та процесів, тоді як у випадку Apache Spark для перегляду таких видів візуалізації потрібна система управління кластерами, як Ambari. Apache Spark сам по собі не забезпечує можливості візуалізації і хороший лише в частині програмування. Це на сьогоднішній день дуже зручна і стабільна система для обробки величезної кількості даних.
- Обмеження Apache Nifi пов'язане з тим, у чому його перевага. Єдина функція перетягування забезпечує обмеження неможливості масштабування та забезпечення надійності, коли йдеться про інтеграцію його з іншими компонентами та інструментами, тоді як у випадку Apache Spark первинне обмеження відбувається разом із використанням широкого товарного обладнання та управління ними. стає часом нудною справою. Інше обмежене повідомлення повідомляється про його потокові можливості, пов’язані з дискретизованим потоком і вікном або пакетним потоком, де перетворення RDD в кадр даних та набори даних забезпечує час нестабільності.
Таблиця порівняння Apache Nifi vs Apache Spark
| Основи порівняння | Apache Nifi | Apache Spark |
| Що передбачено | Він надає графічний інтерфейс користувача, як формат для конфігурації системи та моніторингу потоків даних. | Масштабна система обробки даних забезпечується приблизно нульовою затримкою за рахунок дешевого товарного обладнання. |
| Особливості |
|
|
| Архітектурні компоненти |
|
|
| Використовуйте випадки |
|
|
| Питання розгортання | Якщо не використовувалася остання версія Java, видно проблеми конфігурації та сумісності | Для того, щоб керувати середовищем як неправильну конфігурацію, необхідно чітко визначене розташування кластерів |
| Питання масштабності та стабільності | Як правило, не повідомляється про проблеми, що стосуються масштабованості та стабільності | Досягти стабільності складно, оскільки іскра завжди залежить від потоку потоку. |
| Переваги надані | Це дозволяє велику візуалізацію потоків даних до організацій і тим самим збільшує зрозумілість цілого системного процесу в кінці | Дуже зручна і стабільна рамка, що стосується великих даних. Ефективність автоматично підвищується при виконанні завдань, пов'язаних з обробкою пакетної та потокової передач. |
| Раніше використовувались розчини | Apache Flume може бути добре використаний, що стосується прийому даних. Єдиним недоліком Flume є відсутність графічних візуалізацій та системної обробки системи | Іншими розгляданими рішеннями були «Свиня», «Вулик» та «Шторм». Використання Apache Spark забезпечує гнучкість використання всіх функцій в одному інструменті. |
| Обмеження | Переважно обмеження пов'язане зі швидкістю індексації походження, яка стає вузьким місцем, коли мова йде про загальну обробку величезних даних | Обмеження для Spark виникає з точки зору стабільності з точки зору API, оскільки перехід від RDD до фреймів даних до наборів даних часто стає складним завданням. |
Висновок - Apache Nifi vs Apache Spark
На закінчення посади можна сказати, що Apache Spark - важкий коник, тоді як Apache Nifi - спритний скакун. У обох є свої переваги та обмеження, які слід використовувати у відповідних областях. Вам потрібно визначити правильний інструмент для вашого бізнесу. Слідкуйте за нашим блогом, щоб отримати більше статей, пов’язаних із новішими технологіями великих даних.
Рекомендована стаття
Це було керівництвом щодо Apache Nifi vs Apache Spark, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Apache Hadoop vs Apache Spark | Топ-10 порівнянь, які ти повинен знати!
- Apache Storm vs Apache Spark - дізнайтеся 15 корисних відмінностей
- 7 важливих речей про Apache Spark (Керівництво)
- Найкращі 15 речей, які потрібно знати про MapReduce vs Spark