
Вступ до вуличної архітектури
Архітектура вуликів побудована поверх екосистеми Hadoop. Часто вулик має взаємодію з Hadoop. Apache Hive справляється як із системою баз даних SQL домену, так і з зменшенням Map. Програми для вуликів можна писати різними мовами, такими як Java, python. Архітектура вуликів показує, як писати мову запиту вулика та як взаємодія між програмістом здійснюється за допомогою інтерфейсу командного рядка. Мова запитів вуликів виконує завдання перетворення всіх завдань кластеру Hadoop через зменшення карт. Як ми всі знали, Hadoop обробляє великі дані в розподіленому середовищі та формує рамки з відкритим кодом. За допомогою вулика він може легко керувати та виконувати запит, а також хороший прихильник виконувати такі функції, як інкапсуляція, спеціальні запити. Ця стаття надає короткий вступ до архітектури вуликів, яка знаходиться на шарі Hadoop для виконання узагальнення великих даних.
Архітектура вуликів з його компонентами
Вулик відіграє головну роль в аналізі даних та інтеграції бізнес-аналітики, і він підтримує формати файлів, такі як текстовий файл, файл rc. Hive використовує розподілену систему для обробки та виконання запитів, а зберігання врешті-решт робиться на диску та, нарешті, обробляється за допомогою фреймворка-скорочення. Він вирішує проблему оптимізації, виявлену в режимі зменшення карти та вулика для виконання пакетних завдань, які чітко пояснені в робочому процесі. Тут мета-магазин зберігає інформацію схеми. Рамка під назвою Apache Tez розроблена для виконання запитів у реальному часі.
Основні компоненти вулика наведені нижче:
- Клієнти вуликів
- Послуги з вуликів
- Зберігання вуликів (мета зберігання)
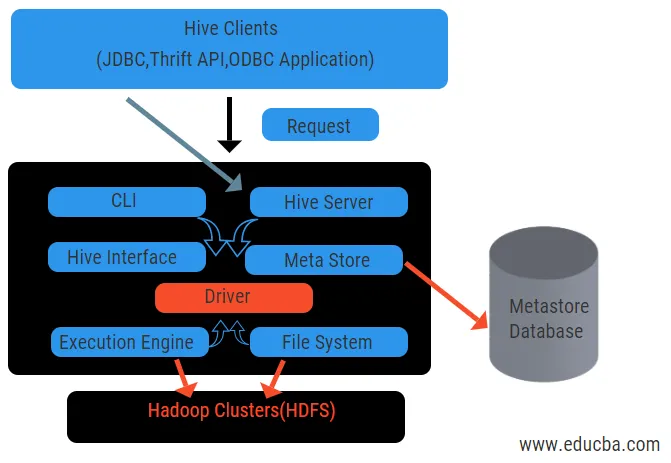
Наведена вище схема показує архітектуру вулика та його складових елементів.
Клієнти вуликів:
Вони включають додаток Thrift для виконання простих команд вулика, які доступні для python, ruby, C ++ та драйверів. Ці клієнтські додатки виграють для виконання запитів у вулику. У вулику є три типи категоризації клієнтів: ощадні клієнти, клієнти JDBC та ODBC.
Послуги з вуликів:
Для обробки всіх запитів у вулику є різні сервіси. Всі функції легко визначаються користувачем у вулику. Давайте розглянемо всі ці служби коротко:
- Інтерфейс командного рядка ( інтерфейс користувача): він дозволяє взаємодія між користувачем та вуликом, оболонка за замовчуванням. Він забезпечує графічний інтерфейс для виконання командного рядка вулика та огляду вулика. Ми також можемо використовувати веб-інтерфейси (HWI) для подання запитів та взаємодій із веб-браузером.
- Драйвер вулика: Він отримує запити з різних джерел та клієнтів, як ощадливий сервер, а також зберігає та вибирає на драйвері ODBC та JDBC, які автоматично підключаються до вулика. Цей компонент робить семантичний аналіз на перегляді таблиць з метасторії, які аналізують запит. Драйвер бере допомогу компілятора і виконує такі функції, як аналізатор, Планувальник, Виконання завдань MapReduce та оптимізатор.
- Компілятор: Розбір і семантичний процес запиту виконується компілятором. Він перетворює запит у абстрактне синтаксичне дерево і знову повертається у DAG для сумісності. Оптимізатор, у свою чергу, розбиває наявні завдання. Завдання виконавця - виконувати завдання та контролювати графік виконання завдань.
- Execution Engine: Усі запити обробляються механізмом виконання. Плани етапів DAG виконуються двигуном і допомагають керувати залежностями між доступними етапами та виконувати їх на правильному компоненті.
- Metastore: Він виступає в якості центрального сховища для зберігання всієї структурованої інформації метаданих, також є важливою частиною для вулика, оскільки він містить інформацію, як таблиці та деталі розділів та зберігання файлів HDFS. Іншими словами, ми скажемо, що метасторія працює як простір імен для таблиць. Metastore вважається окремою базою даних, якою поділяються й інші компоненти. У Metastore є дві частини, що називаються сервісом та резервним зберіганням.
Модель даних вулика структурована у розділи, відра, таблиці. Все це можна відфільтрувати, мати ключі розділів та оцінити запит. Запит на вулик працює на базі Hadoop, а не на традиційній базі даних. Сервер вуликів - це інтерфейс між віддаленими запитами клієнта до вулика. Двигун виконання повністю вбудований у сервер вуликів. Ви можете знайти застосування вуликів у машинному навчанні, бізнес-аналітиці в процесі виявлення.
Робочий потік вулика:
Вулик працює у двох типах режимів: інтерактивному та неінтерактивному режимі. Колишній режим дозволяє всім командам вулика переходити безпосередньо до корпусу вулика, тоді як пізніший тип виконує код у консольному режимі. Дані поділяються на розділи, які надалі розбиваються на відра. Плани виконання засновані на агрегації та перекосу даних. Додатковою перевагою використання вулика є те, що він легко обробляє велику кількість інформації та має більше користувальницьких інтерфейсів.
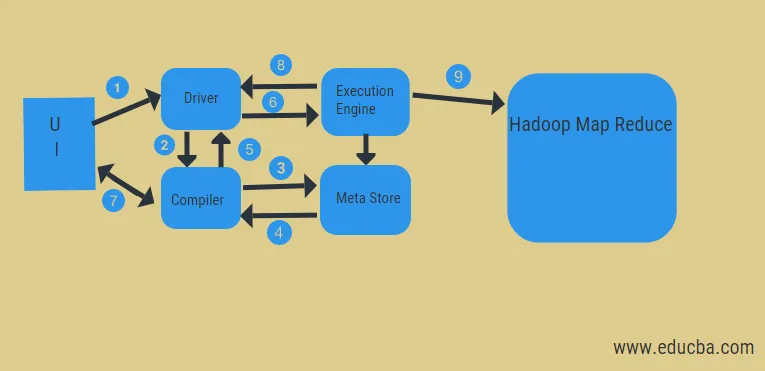
З наведеної діаграми ми можемо побачити потік даних у вулику за допомогою системи Hadoop.
Етапи включають:
- виконати Запит з інтерфейсу користувача
- отримати план із етапів DAG завдань драйвера
- отримати запит метаданих із магазину мета
- відправити метадані від компілятора
- відправлення плану назад водієві
- Виконати план у двигуні виконання
- отримання результатів для відповідного запиту користувача
- надсилання результатів двосторонньо
- виконання процесорів обробки двигунів у HDFS із зменшенням карти та отримання результатів із вузлів даних, створених трекером завдань. він виступає сполучною ланкою між вуликом та Hadoop.
Завдання двигуна виконання - спілкуватися з вузлами, щоб отримати інформацію, що зберігається в таблиці. Тут для доступу до таблиці виконуються SQL-операції, такі як create, drop, alter.
Висновок:
Ми пройшли архітектуру Hive та їх робочий потік, вулик в основному виконує петабайтний об'єм даних, отже, це пакет даних для зберігання даних на платформі Hadoop. Оскільки вулик є хорошим вибором для обробки великого обсягу даних, він допомагає в підготовці даних за допомогою посібника інтерфейсу SQL для вирішення питань MapReduce. Вулик Apache - це інструмент ETL для обробки структурованих даних. Знання функціонування архітектури вуликів допомагає корпоративним людям зрозуміти принцип роботи вулика і добре починає програмування вуликів.
Рекомендовані статті:
Це було керівництвом архітектури вуликів. Тут ми обговорюємо архітектуру вуликів, різні компоненти та робочий процес вулика. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Hadoop Архітектура
- Використання Ruby
- Що таке C ++
- Що таке база даних MySQL
- Замовлення вуликів за