

Вступ до хешування в СУБД
Коли ми говоримо про величезну структуру баз даних та їх складність, пошук усіх індексів стає дуже неефективним, а досягнення бажаних даних стає дуже невиразним і складним. Використовуючи техніку хешування, можна досягти цих станів, і можна призначити прямий покажчик, щоб знати точне та пряме розташування на диску для конкретного запису без використання складної структури індексу. Дані у випадку техніки хешування зберігаються у вигляді блоків даних, адреса яких генерується за допомогою функції, зазвичай відомої як хеш-функція. Місце у пам'яті, де зберігаються та зберігаються записи, називається блоками даних або пакетом даних.
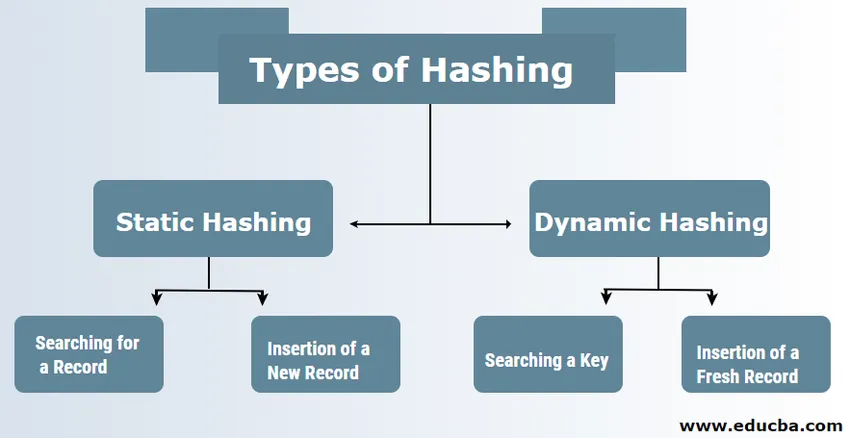
Типи хешування в СУБД
Зазвичай у СУБД є два типи методів хешування:
1. Статичний хешинг
2. Динамічний хешинг
1) Статичний хешинг
У разі статичного хешування набір даних формується і адреса відра однакова. Це означає, що якщо ми спробуємо генерувати адресу для USER_ID = 113, використовуючи модуль 5 хешування функції, то він завжди надає нам результуючу як 3 з однаковою адресою відра. У цьому випадку не буде змінено адресу наданого відра. Тому кількість відра залишається постійною протягом усієї операції.
Експлуатація статичного типу хешування
а. Пошук запису: Якщо для запису потрібно знайти, то саме таку ж функцію хешування використовується для отримання адреси та шляху відрізка даних із збереженням даних.
б. Вставлення нової записи: Якщо в таблицю поміщено новий і свіжий запис, то для нового запису генерується адреса, заснована на хеширующем ключі, тим самим зберігаючи запис у цьому місці.
- Видалення запису: для того, щоб запис був видалений, спочатку потрібно отримати цей запис, який можна видалити. Після того, як це завдання виконано, записи потрібно видалити для цієї адреси пам'яті.
- Оновлення запису: Щоб оновити запис, ми спочатку шукаємо запис, використовуючи хеш-функцію, і як тільки це буде зроблено, тоді, як можна сказати, наш запис даних знаходиться в оновленому стані. Для того, щоб ми вставили свіжий запис у файл, а адреса, яка генерується за допомогою хеш-функції, і пакет даних не порожній або якщо дані вже є у вказаній адресі. Таку ситуацію, яка особливо виникає у випадку статичного хешування, можна краще назвати переповненням відра, і тому існують деякі способи подолання цієї проблеми, такі як:
(i) Відкриття хешування: Якщо функція хешування генерує адресу, для якої дані можна побачити вже в збереженому стані, у цьому випадку наступний рівень відра автоматично отримає розподіл. Цей механізм можна назвати лінійною методикою зондування.
Наприклад, якщо R3 - свіжа адреса, яку потрібно поставити, функція на основі хеша генерує адресу як число 102 для адреси R3. Згенерована адреса знаходиться в повному стані, і тому система призначена для пошуку нового пакета даних, який становить 113, і присвоєння R3 цьому групі даних.
(ii) Закритий хешинг: Коли відра повністю заповнені, нове відро виділяється для конкретного результату хешу, який пов’язується відразу після того, як виконано раніше, і тому цей метод називається технікою ланцюга переповнення.
Наприклад, R3 - свіжа адреса, яку потрібно ввести в нову таблицю, функція хешування використовується для генерування адреси як числа 110 до неї. Це відро, у свою чергу, заповнене, тому не може отримувати нові дані, тому свіже відро ставиться в кінці після 100.
2) Динамічний хешинг
Цей вид хеш-методу може бути використаний для вирішення основних проблем статичного хешування, як таких, як переповнення відра, оскільки відра даних можуть зростати і зменшуватися з розміром, це більш оптимізований простір, і тому його називають розширюваним хеш-метод. У цьому методі хешування стає динамічним, що означає, що активність вставки або видалення дозволена, не створюючи низьку продуктивність.
а. Пошук ключа: Обчисліть хеш-адресу потрібного ключа та перевірте кількість бітів, які використовуються у випадку каталогу, який відомий як i. Тоді ті, які є найменш значущими I бітами, беруться з каталогу, що дає уявлення про індекс з каталогу. Використовуючи це значення індексу, увійдіть у каталог, щоб знайти адресу відра для пошуку наявних записів.
б. Вставлення свіжого запису: Спочатку від вас вимагається дотримуватись точно такої самої процедури пошуку, яку потрібно закінчити десь у відрі. Знайдіть простір у цьому відрі, а потім помістіть записи всередину нього. Якщо це створене відро є повним і повним, то відро розбивається і записи перерозподіляються.
Наприклад, останні два біти цифр 2 і 4 - 00. Отже, вони будуть переходити у відро B0 і так далі відповідно до функції модуля. Ключ 9 має адресу 10001, яка повинна бути присутнім у першому відрі, але вона розщепиться і перейде до нового відра B1, і це триває, поки всі відра та ключі не будуть динамічно хешировані. Хеш-функція використовується таким чином, коли хеш-функція використовується для вибору стовпця та його значення для генерації адреси. Максимально, коли хеш-функція використовує первинний ключ, який, в свою чергу, використовується для генерування адрес блоку даних. Це проста математична функція, де первинний ключ також може розглядатися як адреса блоку даних, тобто кожен рядок з такою ж адресою, що і первинний ключ, буде зберігатися у блоці даних.
Рекомендовані статті
Це посібник із хеширования в СУБД. Тут ми обговорюємо введення та різні типи хешування в СУБД, що включає статичне хешування та динамічне хешуваннявання разом із прикладами. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Моделі даних у СУБД
- Переваги СУБД
- Інструмент інтеграції даних
- Що таке RDBMS?