
Різниця між вуликом та HBase
Apache Hive та HBase - це технології великих даних на базі Hadoop. Вони обидва використовували для запиту даних. Вулик і HBase працюють на вершині Hadoop, і вони відрізняються своєю функціональністю. Hive - це SQL-діалект на основі скорочення карт, тоді як HBase підтримує лише MapReduce. HBase зберігає дані у вигляді пар сімейства ключів / значень або стовпців, тоді як Hive не зберігає дані.
Відмінність між головами між Hive проти HBase (Інфографіка)
Нижче наведено 8 найкращих відмінностей між Hive проти HBase
Основні відмінності між Hive проти HBase
- Hbase є сумісною кислотою, тоді як вулик - ні.
- Hive підтримує критерії розділення та фільтрування на основі формату дати, тоді як HBase підтримує автоматизований розподіл.
- Hive не підтримує заяви про оновлення, тоді як HBase їх підтримує.
- Hbase швидше порівняно з Hive у отриманні даних.
- Вулик використовується для обробки структурованих даних, тоді як HBase, оскільки це без схеми, може обробляти будь-який тип даних.
- Hbase є високо (горизонтально) масштабованим порівняно з вуликом.
- Hive аналізує дані на HDFS за підтримки SQL Queries, а потім вони перетворюють їх у карту та зменшують завдання, тоді як у Hbase, оскільки потокове передавання в режимі реального часу, вона безпосередньо виконує свої операції над базою даних шляхом розподілу на таблиці та сімейства стовпців.
- при надходженні запитів у вулик даних використовує оболонку, відому як оболонка Hive, щоб видавати команди, тоді як HBase, оскільки це база даних, ми будемо використовувати команду для обробки даних у HBase.
- Для переходу до корпусу вулика ми будемо використовувати командний вулик. Після цього це буде здаватися вуликом>. У HBase ми просто даємо як Use HBase.
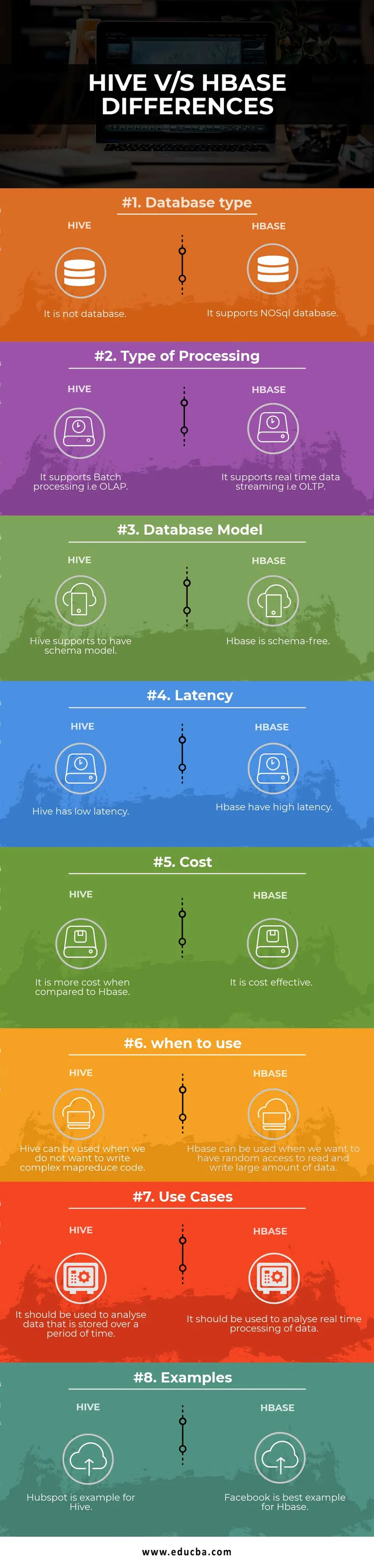
Таблиця порівняння вулика проти HBase
| Основа для порівняння | Вулик | База |
| Тип бази даних | Це не база даних | Він підтримує базу даних NoSQL |
| Тип обробки | Він підтримує пакетну обробку, тобто OLAP | Він підтримує потокове передавання даних у режимі реального часу, тобто OLTP |
| Модель бази даних | Вулик підтримує, щоб мати схему моделі | Hbase не містить схеми |
| Затримка | Вулик має низьку затримку | Hbase має високу затримку |
| Вартість | Це дорожче порівняно з HBase | Це економічно вигідно |
| коли використовувати | Вулик можна використовувати, коли ми не хочемо писати складний код MapReduce | HBase можна використовувати, коли ми хочемо мати випадковий доступ для читання та запису великої кількості даних |
| Використовуйте випадки | Його слід використовувати для аналізу даних, які зберігаються протягом певного періоду часу | Його слід використовувати для аналізу обробки даних у режимі реального часу. |
| Приклади | Hubspot - приклад для вулика | Facebook - найкращий приклад для Hbase |
Відмінності в кодуванні між Hive проти HBase
Давайте тепер обговоримо основні відмінності між Hive та HBase у кодуванні.
| Основа для порівняння | Вулик | База |
| Для створення бази даних | СТВОРИТИ ДАТАБАЗУ (ЯКЩО НЕ МАЄТЬСЯ) БАЗА-ІМЕНА | Оскільки Hbase - це база даних, нам не потрібно створювати певну базу даних |
| Щоб скинути базу даних | ДАРАБАЗА ДРОБУВАННЯ (ЯКЩО ВИНАЄТЬСЯ) БАНКА-ІМЕНА (ОБМЕЖЕННЯ ТА КАСКАД); | НС |
| Створення таблиці | СТВОРИТИ (ВРЕМЕННО АБО ВНУТРІШНУ) ТАБЛИЦЮ (ЯКЩО НЕ ІСНУЄ) ТАБЛИЦЯ ((ім'я даних-стовпця_типу (коментар стовпця-коментар), ….)) (коментар таблиці_ коментар) (формат рядка ROW FORMAT) (зберігається у форматі файлу) | СТВОРИТИ '', '' |
| Змінити таблицю | ПІДГОТОВИТИ ІМЕНЮ ТАБЛИЦІ ПІДГОТОВКА ДО НОВОГО імені
НАЗАД ТАБЛИЦЯ назва DROP (COLUMN) назва стовпця НАЗАД НАЗАД ТАБЛИЦІ ДОДАТИ КОЛІН (col-spec (, col-spec ..)) ALTER TABLE ім'я ЗМІНИТЕ Ім'я стовпця new-name new-type НАЗАД НАЗАД ТАБЛИЦИ ЗАМІНІТЬ КОЛИНИ (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Відключення таблиці | НС | вимкнути "TABLE-NAME" ->, щоб відключити вказане ім'я таблиці
ones_all 'r *' ->, щоб вимкнути всі таблиці, які відповідають регулярному виразу |
| Увімкнення таблиці | НС | увімкнути "TABLE-NAME" |
| Щоб скинути таблицю | ПІДТРИМАТИ ТАБЛИЦЮ, ЯКЩО ВИНАГАЄТЬСЯ назва таблиці | Якщо ми хочемо скинути таблицю, то спочатку нам потрібно її відключити
відключити "ім'я таблиці" drop 'ім'я таблиці' Аналогічно, ми можемо використовувати enable_all та drop_all для видалення таблиць, які відповідають заданому регулярному виразу. |
| Перелік баз даних | показувати бази даних; | НС |
| Щоб перерахувати таблиці в базі даних | показати таблиці; | список |
| Описати схему таблиці | описати назву таблиці; | опишіть "ім'я таблиці" |
Інтеграція вулика проти HBase
- Встановити та налаштувати вулик.
- Встановлення та налаштування HBase.
- Для інтеграції і вулика, і HBase ми використовуємо СКЛАДОВІ РУЧКИ в вулику.
- Обробники зберігання - це комбінація SERDE, InputFormat, OutputFormat, яка приймає будь-яку зовнішню сутність як таблицю в Hive.
- Таким чином, ця функція допомагає користувачеві видавати запити SQL, будь то таблиця в Hadoop або в базі даних NOSQL, таких як HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Зараз ми розглянемо один приклад з'єднання вулика з HBase за допомогою HiveStorageHandler:
- Спочатку нам потрібно створити таблицю Hbase за допомогою команди.
створити "Студент", "персональна інформація", "інформація про відділ"
-> Особисті дані та інформація про відділ створюють дві різні групи стовпців у таблиці Студент.
- Нам потрібно вставити деякі дані в таблицю Student. Наприклад, як зазначено нижче.
поставити 'студент', 'sid01', 'personalinfo: ім'я', 'Ram'
поставити 'студент', 'sid01', 'personalinfo: mailid', ' '
поставити 'студент', 'sid01', 'deptinfo: deptname', 'Java'
поставити 'Студент', 'sid01', 'deptinfo: joinyear', '1994'
-> Так само ми можемо створити дані для sid02, sid03…
- Тепер нам потрібно створити таблицю Hive, що вказує на таблицю HBase.
- Для кожного стовпця в Hbase ми створимо одну конкретну таблицю для цього стовпця в вулику. У цьому випадку ми створимо 2 таблиці в вулику
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Аналогічно, нам потрібно створити таблицю детальних відомостей про відділ інформації у вулику.
- Тепер ми можемо записувати SQL-запит у вулик, як було зазначено нижче.
select * from student_hbase;
Таким чином ми можемо інтегрувати Hive з HBase.
Висновок - вулик проти HBase
Як обговорювалося, вони обидва є різними технологіями, які надають різні функціональні можливості, коли Hive працює за допомогою мови SQL, і це також можна назвати, як HQL і HBase використовують пари ключових значень для аналізу даних. Вулик і HBase працюють краще, якщо вони поєднуються, оскільки у вулика низька затримка і може обробляти величезну кількість даних, але не може підтримувати сучасні дані, а HBase не підтримує аналіз даних, але підтримує оновлення на рівні рядків на великій кількості даних.
Рекомендована стаття
Це було керівництвом щодо вулика проти HBase, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Apache Pig vs Apache Hive - 12 найкращих корисних відмінностей
- Дізнайтеся про 7 найкращих відмінностей між Hadoop проти HBase
- Топ-12 порівнянь Apache Hive - Apache HBase (Інфографіка)
- Хадоп проти вулика - з’ясуйте найкращі відмінності