
Різниця між BFS VS DFS
Пошук у першу ширину (BFS) та Перший глибинний пошук (DFS) - два важливі алгоритми, які використовуються для пошуку. Перший пошук по ширині починає пошук з першого вузла, а потім переміщується через рівні, що наближаються до кореневого вузла, тоді як алгоритм «Поглиблений перший пошук» починається з першого вузла, а потім завершує шлях до кінцевого вузла відповідного шляху. Обидва алгоритми проходять через кожен вузол під час пошуку. Для двох алгоритмів написано різні коди для виконання процесу проходження. Вони також розглядаються як важливі алгоритми пошуку в Штучному інтелекті.
У цій темі ми збираємось дізнатись про BFS VS DFS.
Як працюють BFS та DFS?
Нижче пояснено приклади роботи обох алгоритмів. Будь ласка, зверніться до них для кращого розуміння використовуваного підходу.
Приклад пошуку першої ширини
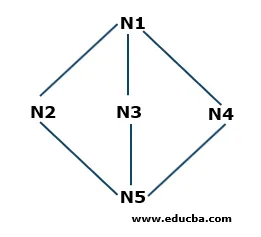
- Крок 1: N1 - кореневий вузол, тому він почнеться звідси. N1 з'єднаний з трьома вузлами N2, N3 і N4. Всі три вузли ще не відвідували. Отже, ми починаємо з N2 і зберігаємо його в черзі. Отже, черга з іменем Q містить лише N2.
Q: N2
- Крок 2: Наступним вузлом, який підключений до N1, є N3. Оскільки ми перейшли чи відвідали вузол, ми збережемо його у черзі. Отже, оновлена черга є
Q: N3, N2
- Крок 3: Наступним вузлом, який підключений до кореневого вузла, є N4. Ми збережемо його в черзі.
Q: N4, N3, N2
- Крок 4: Усі вузли, які підключені до N1, зберігаються у черзі. Тепер ми видаляємо N2 з черги за принципом First in First Out (FIFO) і знаходимо вузли, підключені до N2, тобто N5. N5 не відвідується один раз, тому ми збережемо його в черзі.
Q: N5, N4, N3
- Крок 5: Усі вершини відвідуються, тому ми продовжуємо видаляти вузли з черги, поки вони не порожні.
Приклад першого глибинного пошуку
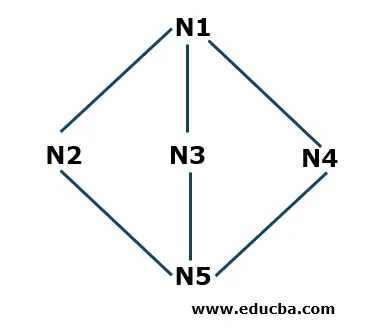
- Крок 1: Ми почнемо з N1 як вихідний вузол і збережемо його в стеку S. N1 з'єднаний з трьома сусідніми вузлами N2, N3 і N4. Починаючи з N2 (можна починати в алфавітному чи цифровому порядку), ми поставимо це в стек.
S: N2 (вгорі), N1
- Крок 2: Тепер сусідніми вузлами N2 є N1 і N5. Оскільки N1 вже присутній у стеку, це означає, що він відвідується, тому ми візьмемо N5 і помістимо його в стек S.
S: N5 (вгорі), N2, N1
- Крок 3: Тепер сусідніми вузлами N5 є N3 і N4. Ми почнемо N3 і покладемо його в стек.
S: N3 (вгорі), N5, N2, N1
Тепер N3 підключений до N5 і N1, які вже є в стеку, що означає, що вони відвідуються, тому ми видалимо N3 зі стека відповідно до принципу Last in First Out (LIFO).
S: N5 (вгорі), N2, N1
- Крок 4: Тепер ми поставимо останній вузол, який ми не натрапили на весь прохід по N4, і поставимо його в стек.
S: N4 (вгорі), N5, N2, N1
- Крок 5: Тепер ми не залишилися поза будь-якими іншими вузлами, тому ми перевіримо в стеці, чи є якісь вузли, підключені до відповідних вузлів, присутніх у ньому, які не відвідуються. Якщо всі підключені вузли відвідані, ми видалимо вузли, наявні в стеку. Наприклад, N4 не має з'єднувальних вузлів, які ми не перевіряли, тому ми видалимо його зі стека. Аналогічно ми можемо перевірити інші вузли. Алгоритм зупиняється, коли стек порожній.
Порівняння «голова до голови» між BFS VS DFS (Інфографіка)
Нижче наведено найкращі 6 відмінностей між BFS VS DFS
Ключові відмінності між BFS та DFS
Давайте обговоримо деякі основні ключові відмінності між BFS та DFS
- Перший пошук по ширині (BFS) починається від кореневого вузла і відвідує всі відповідні вузли, приєднані до нього, тоді як DFS починається від кореневого вузла і завершує повний шлях, приєднаний до вузла.
- BFS дотримується підходу черги, тоді як DFS дотримується підходу Stack.
- Підхід, використовуваний у BFS, є оптимальним, тоді як процес, що використовується в DFS, не є оптимальним.
- Якщо наша мета - знайти найкоротший шлях, ніж BFS є кращим перед DFS.
Таблиця порівняння BFS та DFS
Давайте обговоримо найкраще порівняння між BFS та DFS
| BFS | ДФС |
| Повна форма BFS - це пошук в першу чергу. | Повна форма DFS - це глибокий перший пошук |
| BFS призначений для знаходження найкоротшої відстані, і він починається від першого або кореневого вузла і переміщується по всіх його вузлах, приєднаним до відповідних вузлів. Ви можете отримати чітке уявлення про його робочий механізм, переглянувши приклад нижче. | DFS дотримується підходу, заснованого на глибині, і він завершує повний шлях через усі вузли, приєднані до відповідного вузла. Ви можете отримати чітке уявлення про його робочий механізм, переглянувши приклад нижче. |
| Це робиться за принципом черги, який є підходом First In First Out (FIFO). | Це робиться за принципом Stack, що є підходом Last In First Out (LIFO). |
| Вузли, які проходять не один раз, видаляються з черги. | Відвідані вузли вставляються в стек і пізніше, якщо немає більше вузлів, які слід відвідати, вони видаляються. |
| Він порівняно повільніше, ніж глибинний перший пошук. | Це швидше, ніж алгоритм пошуку на широті. |
| Розподіл пам'яті більше, ніж алгоритм глибинного першого пошуку. | Розподіл пам’яті порівняно менше, ніж алгоритм пошуку за шириною першого |
Висновок
Існує багато застосунків, де вищезазначені алгоритми використовуються як машинне навчання або для пошуку рішень, пов'язаних із штучним інтелектом тощо. Вони в основному використовуються в графіках, щоб знайти, чи є двостороннім чи ні, для виявлення підключених циклів або компонентів. Вони також розглядаються як важливі алгоритми пошуку шляху або знаходження найкоротшої відстані. Залежно від вимог бізнесу, ми можемо використовувати два алгоритми. Однак пошук в першу чергу - вважається оптимальним способом, а не алгоритмом «Перший глибинний пошук».
Рекомендовані статті
Це посібник з BFS VS DFS. Тут ми обговорюємо ключові відмінності BFS VS DFS за допомогою інфографіки та таблиці порівняння. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Алгоритм BFS
- TeraData проти Oracle
- Великі дані проти сховища даних
- Великі дані проти Apache Hadoop: 4 найкращі порівняння, які ви повинні навчитися