

Вступ до запитань та відповідей щодо інтерв'ю RDBMS
Тож якщо ви готуєтесь до співбесіди в RDBMS. Я впевнений, що ви хочете дізнатись найпоширеніші запитання та відповіді про RDBMS 2019, які допоможуть вам легко зрушити інтерв'ю RDBMS. Нижче наведено перелік найкращих питань та інтерв'ю для RDBMS, які допоможуть вам допомогти.
Отже, ми схильні додавати найпопулярніші запитання щодо інтерв'ю RDBMS на 2019 рік, які задаються переважно в інтерв'ю
1.Які різні особливості RDBMS?
Відповідь:
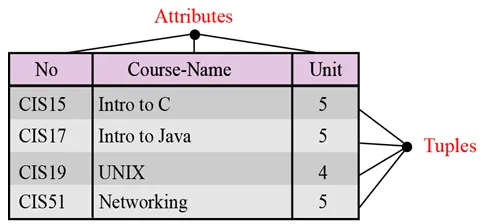
Ім'я. Кожне відношення у реляційній базі даних повинно мати ім'я, яке є унікальним серед усіх інших відносин.
Атрибути. Кожен стовпець у відношенні називається атрибутом.
Кортежі. Кожен рядок у відношенні називається кортежем. Кортеж визначає набір значень атрибутів.
2.Поясніть модель ER?
Відповідь:
Модель ER - це модель відносин особи. Модель ER базується на реальному світі, який складається з сутностей та об'єктів відносин. Суб'єкти ілюструються в базі даних набором атрибутів.
3. Визначте об'єктно-орієнтовану модель?
Відповідь:
Об’єктно-орієнтована модель базується на колекціях об’єктів. Об'єкт вміщує значення, які зберігаються в екземплярі змінних всередині об'єкта. Об'єкти, що мають ідентичний тип значень і абсолютно однакові методи, об'єднуються в класи.
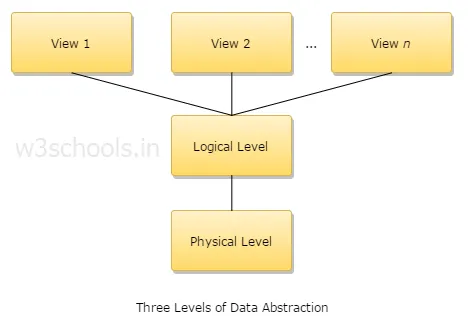
4. Поясніть три рівні абстрагування даних?
Відповідь:
1. Фізичний рівень: Це найнижчий рівень абстракції і він описує, як зберігаються дані.
2. Логічний рівень: Наступний рівень абстрагування є логічним, він описує, який тип даних зберігається в базі даних і який взаємозв'язок між цими даними.
3. Рівень перегляду: найвищий рівень абстракції, і він описує єдину всю базу даних.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Чим відрізняються 12 правил Кодда для реляційних баз даних?
Відповідь:
12 правил Кодда - це набір з тринадцяти правил (пронумерованих від нуля до дванадцяти), запропонованих Едгаром Ф. Коддом.
Правила Кодда:
Правило 0: Система повинна кваліфікуватися як реляційна, як база даних, а також як система управління.
Правило 1: Правило інформації: Кожна інформація в базі даних повинна бути представлена однозначно, в основному значення імен в позиціях стовпців в іншому рядку таблиці.
Правило 2: Правило гарантованого доступу: Усі дані повинні бути інгресивними. Це говорить про те, що кожне скалярне значення в базі даних повинно бути правильно / логічно адресованим.
Правило 3: Систематична обробка нульових значень: СУБД повинна дозволяти кожному кортежу залишатися нульовим.
Правило 4: Активний онлайн-каталог (структура бази даних), заснований на реляційній моделі: Система повинна підтримувати онлайн, реляційну структуру тощо, яка є інгресивною для дозволених користувачів шляхом їх регулярного запиту.
Правило 5: Вичерпний підмову даних: Система повинна допомагати як мінімум однією реляційною мовою, яка:
1. Має лінійний синтаксис
2. Що може використовуватися як в інтерактивному, так і в рамках прикладних програм,
3. Він підтримує операції з визначення даних (DDL), операції з маніпулювання даними (DML), обмеження безпеки та цілісності, а також операції управління транзакціями (початок, фіксація та відкат).
Правило 6: Правило оновлення подання: Усі погляди, які теоретично покращуються, повинні бути оновлені системою.
Правило 7: Вставлення, оновлення та видалення високого рівня: Система повинна підтримувати оператори вставлення, оновлення та видалення.
Правило 8: Незалежність фізичних даних: Змінення фізичного рівня (як зберігаються дані, використовуючи масиви чи пов'язані списки тощо) не повинно вимагати змін програми.
Правило 9: Незалежність логічних даних: Змінення логічного рівня (таблиці, стовпці, рядки тощо) не повинно вимагати змін програми.
Правило 10: Незалежність цілісності: обмеження цілісності повинні бути визначені індивідуально з прикладних програм і збережені в каталозі.
Правило 11: Незалежність розповсюдження: Розподіл частин бази даних в різних місцях не повинен бути видимим користувачам бази даних.
Правило 12: Правило непідключення: Якщо система забезпечує інтерфейс низького рівня (тобто записи), цей інтерфейс не можна використовувати для підриву системи.
6.Що таке нормалізація? і чим пояснюються різні форми нормалізації.
Відповідь:
Нормалізація бази даних - це процес організації даних для мінімізації надмірності даних. Що в свою чергу забезпечує узгодженість даних. Існує багато проблем, пов’язаних із надмірністю даних, такі як витрата простору на диску, невідповідність даних, запити DML (мова маніпуляції даними) стають повільними. Існують різні форми нормалізації: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Дані в кожному стовпчику повинні бути атомним числом, кратними значеннями, розділеними комою. Таблиця не містить повторюваних груп стовпців. Ідентифікація кожного запису унікально за допомогою первинного ключа.
2. 2NF: - Таблиця повинна відповідати всім умовам 1NF та переміщувати зайві дані до окремої таблиці. Більше того, він створює зв'язок між цими таблицями за допомогою зовнішніх ключів.
3. 3NF: - для таблиці 3NF повинні відповідати всі умови 1NF та 2NF. 3NF не містить атрибутів, які частково залежать від первинного ключа.
7. Визначте первинний ключ, зовнішній ключ, кандидатський ключ, супер ключ?
Відповідь:
Первинний ключ: первинний ключ - це ключ, який не дозволяє повторювати значення та нульові значення. Первинний ключ можна визначити на рівні стовпця або таблиці. Допускається лише один первинний ключ на кожну таблицю.
Зовнішній ключ: зовнішній ключ допускає значення, присутні тільки у посиланому стовпці. Це дозволяє повторювати або нульові значення. Його можна визначити як рівень стовпця або рівень таблиці. Він може посилатися на стовпчик унікального / первинного ключа.
Ключ кандидата: Ключ кандидата - це мінімум супер ключ, немає належної підгрупи атрибутів ключа кандидата, може бути супер ключовим.
Супер ключ: Супер ключ - це набір атрибутів схеми відношення, від яких частково залежать усі атрибути схеми. Немає двох рядків не може мати однакове значення атрибутів супер ключа.
8.Що таке інший тип індексів?
Відповідь:
Індекси:
Кластерний індекс: - це індекс, при якому дані фізично зберігаються на диску. Тому до таблиці бази даних можна створити лише один кластерний індекс.
Некластеризований індекс: - Він не визначає фізичні дані, але визначає логічне впорядкування. Зазвичай для цього створюють B-дерево або дерево B +.
9.Які переваги RDBMS?
Відповідь:
• Контроль надмірності.
• Цілісність може бути примушена.
• Невідповідності можна уникнути.
• Дані можна обмінюватися.
• Стандарт може бути застосований.
10.Назвіть деякі підсистеми RDBMS?
Відповідь:
Введення-виведення, Безпека, Обробка мови, Управління зберіганням, Ведення журналів та відновлення, Контроль розподілу, Контроль транзакцій, Управління пам'яттю.
11.Що таке менеджер буфера?
Відповідь:
Buffer Manager вдається зібрати дані з дискового сховища в основну пам'ять і вирішити, які дані будуть в кеш-пам'яті для швидшої обробки.
Рекомендована стаття
Це посібник для Списку питань та інтерв'ю для RDBMS, щоб кандидат міг легко розбити ці запитання щодо інтерв'ю RDBMS. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Найважливіші запитання щодо інтерв'ю щодо даних
- 13 дивовижних питань тестування баз запитань та відповідей
- Топ 10 Питання та відповіді щодо інтерв'ю дизайну
- 5 корисних запитань та відповідей щодо інтерфейсу SSIS