

Що таке AWS Kinesis?
Kinesis - це платформа, яка допомагає збирати, обробляти та аналізувати потокові дані в Amazon Web Services. Потокові дані - це велика кількість даних, породжених з різних джерел, таких як соціальні медіа, датчики IoT, прогноз погоди, охорона здоров'я тощо. Вони використовуються для створення програм на основі потреб користувача. Деякі з поширених додатків включають прогностичну аналітику у великих даних, машинне навчання тощо. У цій темі ми дізнаємось про AWS Kinesis.
AWS Kinesis Services
Перш ніж перейти до служб, давайте спочатку розберемося з деякими термінологіями, які використовуються в Kinesis.
Термінологія
| Термін | Визначення |
| Запис даних | Блок даних, що зберігається в потоці даних Kinesis. Він складається з блоку даних, послідовного номера та ключа розділу |
| Осколок | Набір послідовності записів даних. Кількість осколків можна збільшити або зменшити, якщо швидкість передачі даних буде збільшена. |
| Період утримання | Період часу, протягом якого можна отримати доступ до даних після їх додавання до потоку.
Період утримання за замовчуванням: 24 години |
| Виробник | Він передає записи даних у Kinesis Stream |
| Споживач | Він отримує записи від Kinesis Stream та обробляє їх. |
Kinesis надає 3 основні послуги. Вони є:
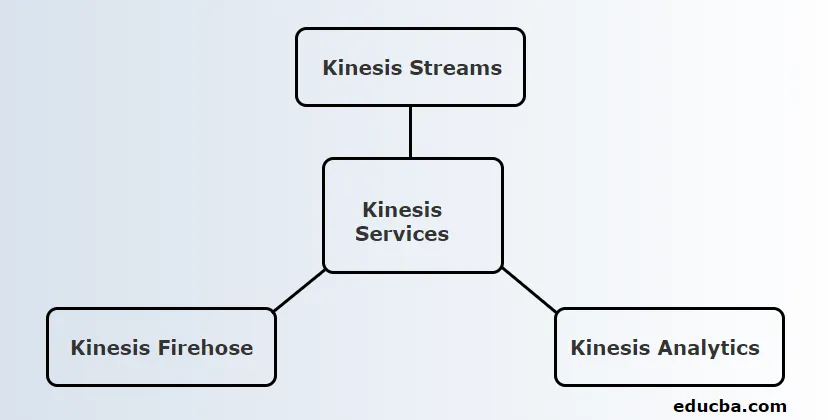
1. Кінезисні потоки
Потік Kinesis складається з набору послідовностей записів даних, відомих як Шарди. Ці Шарди мають фіксовану потужність, яка може забезпечити максимальну швидкість читання 2 Мб / секунду та швидкість запису 1 Мб / секунду. Максимальна потужність потоку - це сума потужності кожного осколка.
Робота з Kinesis:
- Дані, отримані IoT та іншими джерелами, відомими як «Виробники», передаються в потоки Kinesis для зберігання в Шардах.
- Ці дані будуть доступні в Shard не більше 24 годин.
- Якщо його потрібно зберігати більше, ніж цей час за замовчуванням, користувач може збільшити до 7 днів зберігання.
- Як тільки дані надійдуть до Шардів, екземпляри EC2 можуть приймати ці дані для різних цілей.
- Випади EC2, які отримують дані, називаються споживачами.
- Після обробки даних він надходить до однієї з веб-служб Amazon, таких як Simple Storage Service (S3), DynamoDB, Redshift тощо.
2. Kinesis Firehose
Kinesis Firehose корисний для переміщення даних у веб-сервіси Amazon, такі як Redshift, простого сервісу зберігання даних, Elastic Search тощо. Це частина потокової платформи, яка не управляє жодними ресурсами. Виробники даних налаштовані таким чином, що дані мають бути надіслані Kinesis Firehose і він автоматично надсилає їх до відповідного пункту призначення.
Робота з Kinesis Firehose:
- Як вже згадувалося в роботі AWS Kinesis Streams, Kinesis Firehose також отримує дані від таких виробників, як мобільні телефони, ноутбуки, EC2 тощо. Але для цього не потрібно брати дані в осколки або збільшувати періоди зберігання, як Kinesis Streams. Це тому, що Kinesis Firehose робить це автоматично.
- Далі дані аналізуються автоматично і передаються в службу простого зберігання
- Оскільки немає періоду зберігання, дані потрібно аналізувати або надсилати в будь-яке сховище, залежно від потреби користувача.
- Якщо дані потрібно надіслати до Redshift, її потрібно спочатку перенести в службу простого зберігання і потрібно скопіювати звідти Redshift.
- Але, у випадку еластичного пошуку, дані можуть безпосередньо надходити в нього, як у службі простого зберігання.
3. Kinesis Analytics
Kinesis Firehose дозволяє запускати SQL запити в даних, які є в Kinesis Firehose. Використовуючи ці запити SQL, дані можна зберігати в Redshift, Simple Storage Service, ElasticSearch тощо.
AWS Kinesis Architecture
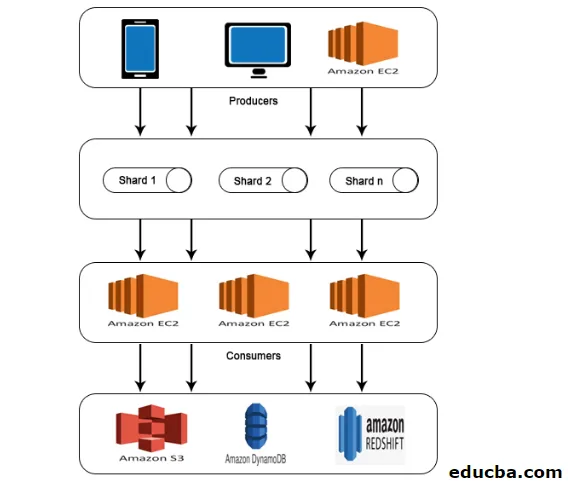
AWS Kinesis Architecture складається з
- Виробники
- Осколки
- Споживачі
- Зберігання
Подібно до роботи, поясненої в AWS Kinesis Data Stream, дані виробників подаються в Shards, де дані обробляються та аналізуються. Потім аналізовані дані переміщуються до екземплярів EC2 для виконання певних програм. Нарешті, дані зберігатимуться в будь-якій з веб-служб Amazon, таких як S3, Redshift тощо.
Як користуватися AWS kinesis?
Для роботи з AWS Kinesis потрібно зробити наступні два кроки.
1. Встановіть інтерфейс командного рядка AWS (CLI).
Встановлення інтерфейсу командного рядка відрізняється для різних операційних систем. Отже, встановіть CLI на основі вашої операційної системи.
Для користувачів Linux використовуйте команду sudo pip install AWS CLI
Переконайтеся, що у вас пітон версії 2.6.5 або новішої. Після завантаження налаштуйте його за допомогою команди настройки AWS. Потім буде запропоновано наступні деталі, як показано нижче.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Для користувачів Windows завантажте відповідний інсталятор MSI та запустіть його.
2. Виконайте операції Kinesis, використовуючи CLI
Зверніть увагу, що потоки даних Kinesis недоступні для вільного рівня AWS. Отже, створені потоки Kinesis стягуватимуться.
Тепер давайте подивимося деякі операції кінезу в CLI.
- Створити потік
Створіть потік KStream за допомогою Shard count 2 за допомогою наступної команди.
aws kinesis create-stream --stream-name KStream --shard-count 2
Перевірте, чи створив потік.
aws kinesis describe-stream --stream-name KStream
Якщо він створений, з'явиться результат, подібний до наступного прикладу.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Покласти запис
Тепер запис даних можна вставити за допомогою команди put-record. Тут запис, що містить тест даних, вставляється в потік.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Якщо вставка буде успішною, результат буде показаний, як показано нижче.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Отримати запис
По-перше, користувачеві необхідно отримати ітератор осколка, який представляє положення потоку для осколка.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Потім запустіть команду за допомогою отриманого ітератора осколка.
aws kinesis get-records --shard-iterator ###########
Вийде вибірковий вибір, як показано нижче.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Прибирати
Щоб уникнути стягнення, створений потік можна видалити за допомогою команди нижче.
aws kinesis delete-stream --stream-name KStream
Висновок
AWS Kinesis - це платформа, яка збирає, обробляє та аналізує потокові дані для декількох додатків, таких як машинне навчання, прогнозована аналітика тощо. Потокові дані можуть мати будь-який формат, наприклад аудіо, відео, сенсорні дані тощо.
Рекомендовані статті
Це посібник з AWS Kinesis. Тут ми обговорюємо, як користуватися AWS Kinesis, а також її сервісом з роботою та архітектурою. Ви також можете переглянути наступну статтю, щоб дізнатися більше -
- AWS Архітектура
- Що таке AWS Lambda?
- Технології великих даних
- Архів архітектури даних
- Послуги зберігання AWS
- Посібник для конкурентів AWS з особливостями