
Різниця між HBase та Cassandra
HBase - це база даних, яка використовує розподілену файлову систему Hadoop для свого зберігання. HBase є важливою частиною HDFS і працює на вершині кластера Hadoop. HBase не є традиційною реляційною базою даних, вона вимагає різного підходу до моделювання даних. Кассандра працює над моделлю реплікації даних, тому в разі відсутності будь-якого вузла втрати даних не буде. Кассандра - це розподілена база даних, що означає, що клієнт може отримати доступ до даних з будь-якого кластера та з будь-якого вузла
1.1) Кассандра:
Його розпочав Facebook, оскільки він завжди відповідає вимогам програми. Кассандра була створена у 2005 році та стала доступною для публіки у 2008 році. Кассандра була розроблена для таких програм, як завжди, таких як соціальні мережі, як Facebook та Twitter.
Кассандра працює над архітектурою, що постійно працює, і має модель вузла Active-Active, так що немає SPoF (Єдиної точки відмови). CQL (мова запитів Cassandra) - мова запиту Cassandra, але має синтаксис такий же, як SQL. Він підтримує всі основні ОС, такі як Linux, Unix, OSX та Windows.
Завжди:
Cassandra - це база даних з моделлю розподілу, і всі вузли однакові в кластері. Дані реплікуються на налаштованих вузлах, тому у випадку відмови деяких немає. вузлів не призведе до втрати даних.
(Завжди на моделі)
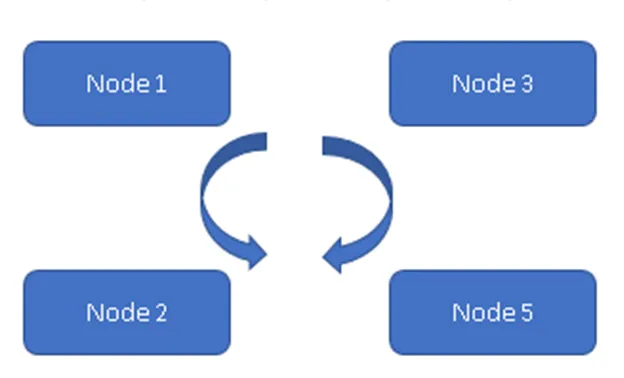
На малюнку 1 всі чотири вузли синхронізуються один з одним та реплікують дані в кластері. Усі працюють над активною-активною моделлю, тому в разі будь-якої несправності вузла не призведе до втрати даних. Клієнт може прочитати дані з решти доступних Вузолів / Вузлів.
1.2) HBase:
HBase - це база даних на базі NoSQL і призначена для обробки запитів у великих таблицях, що мають мільярди рядків з мільйонами стовпців і проходять через кластер товарного / нормального обладнання. Він надає вам можливості запиту в режимі реального часу зі швидкістю " сховища ключа / вартості " .
HBase фактично базується / працює на чотиривимірній моделі даних.
- Ідентифікатор рядка / ключ рядка
- Сім'я колони.
- Пари ключ-значення.
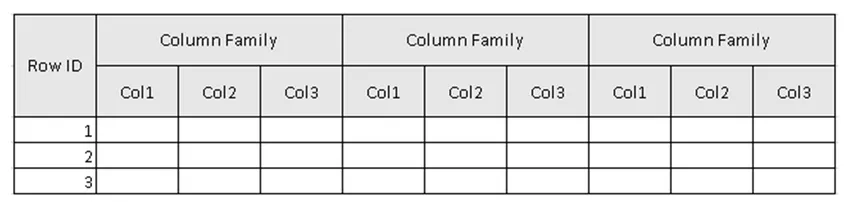
(Малюнок 2, Прикладна схема таблиці в HBase.)
На малюнку 2 Таблиця - це колекція сімейства стовпців, а сім'я стовпців - колекція стовпців. Стовпці - це сукупність пар Ключові значення
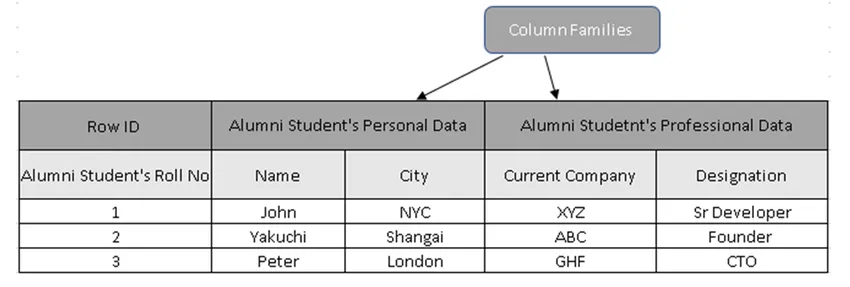
(Малюнок 3, Прикладна таблиця в HBase)
На малюнку 3 сімейства стовпців - це збір даних студентів випускників, а ідентифікатори рядків (рядкові ключі) містять список студента
Фактично, рядові ключі зберігають унікальне значення щодо даних сімейства стовпців. Використовуючи ключ рядка, можна витягнути всі деталі, причини, чому орієнтовані на стовпці бази даних набагато швидше, ніж традиційні бази даних.
Apache HBase можна використовувати для випадкового доступу для читання / запису, і це забезпечує підтримку відмов. Він також підтримує реплікацію та роботу над моделлю бази даних розподілу.
Порівняння порівняння між HBase та Cassandra (Інфографіка)
Нижче представлена найкраща різниця між HBase проти Кассандри
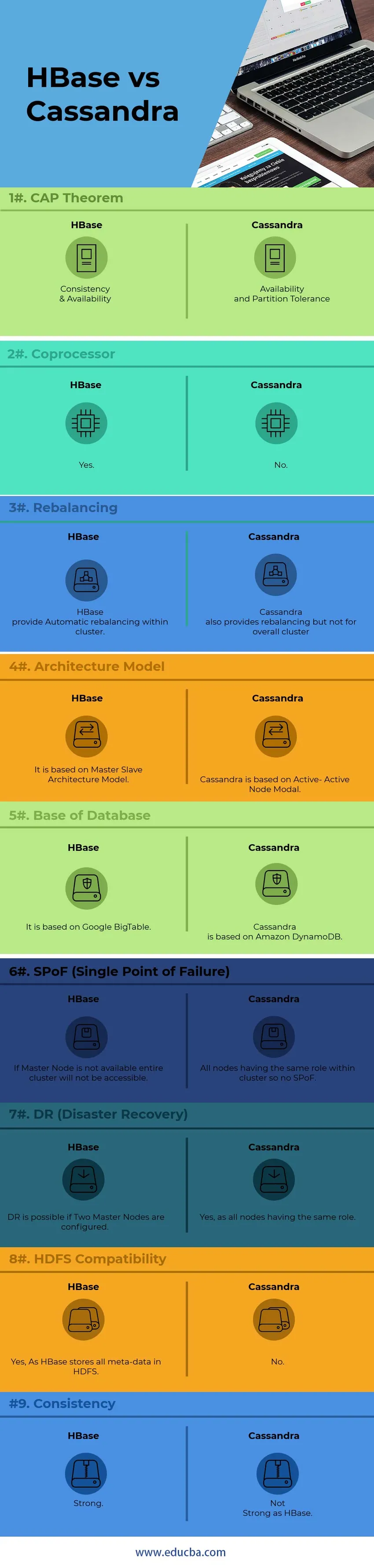 Основні відмінності між HBase та Cassandra
Основні відмінності між HBase та Cassandra
Нижче наведено списки пунктів, опишіть ключові відмінності між HBase та Cassandra:
1) Для внутрішнього зв'язку з вузлом, Кассандра використовує протокол GOSSIP, тоді як HBase базується на Zookeeper. Послуги протоколу GOSSIP інтегровані з Cassandra з іншого боку Zookeeper - це абсолютно окреме розповсюдження.
2) У архітектурі Кассандри всі вузли працюють як Активний вузол, тоді як архітектор HBase слід за моделлю Master-Slave Node. У моделі Active-Active Node немає SPoF (Одинична точка відмови). У HBase, якщо вузол Master спуститься, весь кластер не буде доступний.
3) Підтримка HBase Модель пошуку бінарних дерев, в той час як Cassandra не підтримує модель B-Tree Без B-Tree, ви не можете шукати Сімейство стовпців користувачів для всіх, хто має річницю в квітні, тоді як ви можете шукати всіх, хто живе в Пекіні Річниця у квітні.
4) HBase, підтримка C, C ++, Java, Python, сценарій мови Scala, тоді як Cassandra також підтримує JavaScript і Ruby.
5) HBase має одну особливість, яку називають копроцесорами, тоді як у Cassandra немає такої особливості, як зараз. Копроцесори забезпечують бібліотеку та середовище виконання для виконання коду користувача на сервері регіону HBase та головних процесах.
6) HBase призначений для підтримки сховища даних, тоді як Cassandra буде ідеально підходить для програм, які постійно працюють, таких як Інтернет та мобільні додатки.
7) мова запитів HBase - це власна мова, яку потрібно вивчити, тоді як Cassandra використовує власну розроблену CQL (мову запиту Cassandra), що є SQL-подібною мовою
8) Керувати Кассандрою набагато простіше, ніж HBase. У Кассандрі потрібно запустити єдиний Java-процес на кожен вузол, тоді як для HBase необхідні повністю функціонуючі HDFS, кілька процесів HBase та система Zookeeper.
9) HBase закінчує завершення контрольних сум і автоматичне відновлення балансу, тоді як Cassandra не підтримує збалансування кластеру в цілому.
10) Спираючись на « теорему CAP», Кассандра працює над моделлю AP, тоді як HBase - це модель CP.
Теорема CAP
Ця теорема використовується для розподілених систем. C означає узгодженість, а означає, що доступність & P - толерантність розділів. Теорема CAP пояснюється нижче:
C (узгодженість): послідовність означає, що якщо хтось записав значення в базу даних, інші можуть негайно прочитати те саме значення.
A (Доступність) : Наявність означає, що деякі вузли недоступні у вашому кластері (Вузли пішли / не живуть у кластері через якусь проблему) не вплинуть на весь кластер і розподілена система / База даних будуть доступні для доступу до даних. Кластер буде доступний для всіх видів завдань.
P (Толерантність розділів): Толерантність розділів означає, якщо один Центр даних все ще знижується, що не повинно впливати на дані, представлені на вузлах, і всі дані повинні бути доступними в будь-який час. Значить, Толерантність до розділів дозволяє краще реплікувати дані в інший Центр обробки даних, а також у середовищі кластера.
Таблиця порівняння HBase проти Кассандри
| Очки | HBase | Кассандра |
| Теорема CAP | Послідовність та доступність | Доступність та переносимість розділів |
| Копроцесор | Так | Ні |
| Збалансування | HBase забезпечує автоматичне відновлення балансу в межах кластеру. | Кассандра також забезпечує збалансування, але не для загального кластеру |
| Модель архітектури | Він заснований на моделі архітектури Master-Slave | Кассандра заснована на активно-активних модальних вузлах |
| База даних | Він заснований на Google BigTable | Кассандра базується на Amazon DynamoDB |
| SPoF (Єдина точка відмови) | Якщо Master Node недоступний, весь кластер не буде доступний | Усі вузли, що мають однакову роль у кластері, не мають SPoF |
| DR (відновлення після катастроф) | DR можливий, якщо налаштовані два головних вузли. | Так, як і всі вузли, що мають однакову роль |
| Сумісність з HDFS | Так, оскільки HBase зберігає всі метадані у форматі HDFS | Ні |
| Послідовність | Сильний | Не сильний як HBase |
Висновок - HBase проти Кассандри
Facebook та інша сторона в соціальних мережах віддають перевагу HBase (раніше обидва використовували Кассандру, див. Пост у Facebook), оскільки їх доступність інший сектор банківського домену шукає безпеку для кожної фінансової операції, щоб вони обрали Кассандру через HBase.
Кассандра Основні характеристики включають високу доступність, мінімальне адміністрування та відсутність SPoF (єдиної точки відмови) з іншого боку HBase корисна для швидшого читання та запису даних з лінійною масштабованістю.
Такі компанії, як Verizon, Bloomberg, Bank of America та багато іншого, використовують HBase, а Cassandra використовується великими сайтами соціальних мереж, такими як Twitter, Facebook тощо.
Ми не можемо зробити висновок, який із них найкращий, і HBase, і Кассандра мають свої переваги та недоліки. Фактичні показники як баз даних HBase, так і кассандри можна побачити у виробничих умовах.
Рекомендовані статті:
Це було керівництвом щодо HBase проти Кассандри, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Hadoop vs Apache Spark - цікаві речі, які потрібно знати
- Як зламати інтерв'ю розробника Hadoop?
- Топ-5 великих тенденцій даних
- 5 викликів аналітики великих даних