

Різниця між Apache Hive та Apache HBase -
Історія Apache Hive починається в 2007 році, коли не програміст Java повинен боротися, використовуючи Hadoop MapReduce. Дослідники та розробники передбачили, що завтра настає епоха великих даних. Вже накопичувались різні формати даних, такі як структуровані, напівструктуровані та неструктуровані. Навіть Facebook боровся з більшим обсягом обробки даних. Дослідники у Facebook представили Apache Hive для обробки даних на кластері Hadoop. Facebook був першою компанією, яка створила Apache Hive.
Історія Apache HBase починається в 2006 році, коли Powerset, заснований в Сан-Франциско, намагався створити пошукову систему з природних мов для Інтернету. HBase - це реалізація Bigtable від Google. Ми коли-небудь усвідомлювали, чому виникла потреба придумати ще одну архітектуру пам’яті? Система управління реляційними базами даних існує з початку 1970-х. Існує багато випадків використання, для яких реляційні бази даних чудово мають сенс, але для деяких конкретних проблем реляційна модель не дуже добре підходить.
Дозвольте мені пояснити про Apache Hive та Apache HBase більш детально.
Відмінності між Apache Hive та Apache HBase
Apache Hive - це проект з відкритим кодом Apache, побудований на вершині Hadoop для запитів, узагальнення та аналізу великих наборів даних за допомогою інтерфейсу, подібного SQL. Apache Hive пропонує мову, схожу на SQL, називається HiveQL, яка прозоро перетворює запити в MapReduce для виконання на великих наборах даних, що зберігаються в розподіленій файловій системі Hadoop (HDFS). Apache Hive - це кластерний компонент Hadoop, який зазвичай розгортається аналітиками даних. Вулик Apache використовується для пакетної обробки великих робіт ETL. Apache Hive також підтримує пакетні запити SQL на дуже великих наборах даних. Apache Hive збільшує гнучкість дизайну схеми, а також серіалізацію та десеріалізацію даних. Apache Hive не підтримує обробку онлайн-транзакцій (OLTP), оскільки вулик не підтримує запити в режимі реального часу та оновлення на рівні рядків.
Apache HBase - це база даних NoSQL з відкритим кодом, яка забезпечує доступ у режимі реального часу, для читання та запису до великих наборів даних. NoSQL - це нереляційна база даних. Apache HBase - це база даних, що орієнтована на стовпці, яка працює над файловою системою розподілених файлів Hadoop (HDFS). Отже, HBase приносить переваги NoSQL Hadoop. Apache HBase забезпечує можливості випадкового доступу до даних, присутніх у HDFS. Він використовує стійкість до відмов, яку забезпечує HDFS. Користувач може зберігати дані у HDFS безпосередньо або через HBase.
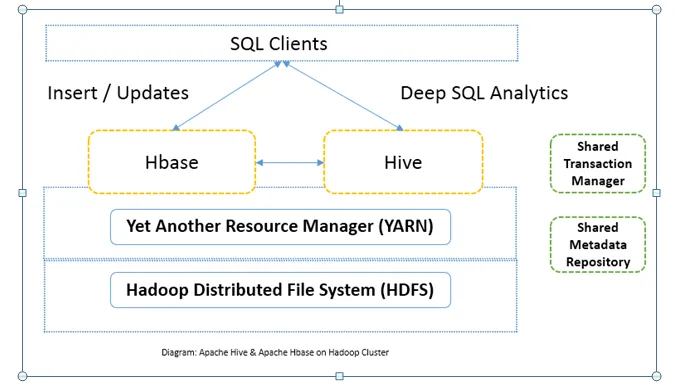
Порівняння порівняння між Apache Hive і Apache HBase (Інфографіка)
Нижче представлено 12 кращих різниць між Apache Hive та Apache HBase

Основні відмінності - Apache Hive проти Apache HBase
Нижче наведено списки пунктів, опишіть ключові відмінності між Apache Hive та Apache HBase:
- Apache HBase - це база даних, тоді як Apache Hive - двигун бази даних.
- Apache Hive використовується в основному для пакетної обробки (OLAP), тоді як Apache HBase використовується в основному для транзакційної обробки (OLTP).
- Apache Hive виконує більшість запитів SQL, тоді як Apache HBase не дозволяє безпосередньо запити SQL.
- Apache Hive не підтримує операції рівня запису, такі як оновлення, вставлення та видалення, в той час як Apache HBase підтримує операції рівня запису, такі як оновлення, вставлення та видалення.
- Apache Hive працює поверх MapReduce, тоді як Apache HBase працює поверх файлової системи розподіленої Hadoop (HDFS).
Apache Hive запитує файли, визначаючи віртуальну таблицю та виконуючи зверху HQL-запити. Це процес, коли файли практично підключені до такої структури, як структура, і користувач може виконувати мову запитів Hive (HQL) і ці запити перетворюються в MapReduce Job від Hive. Користувачеві не потрібно писати завдання MapReduce, HQL запити внутрішньо перетворюються в jar-файли, і ці jar файли будуть реалізовані на наборах даних.
Перебуваючи в Apache HBase, таблиці розбиваються на регіони і обслуговуються регіональними серверами. Далі регіони вертикально розділені сімействами стовпців на магазини, а магазини зберігаються як файли у форматі HDFS.
Коли користуватися Apache Hive:
- Вимоги до зберігання даних
- Аналітичні запити
- Аналіз даних, які знайомі з SQL
Коли використовувати Apache HBase:
- Швидка та інтерактивна обробка даних
- Запити в режимі реального часу
- Швидкий пошук
- Обробка на стороні сервера
- Випадковий доступ для читання / запису до великих даних
- Масштабованість програми
Apache Hive можна використовувати для обчислення тенденцій та журналів веб-сайту електронної комерції для певної тривалості, регіону чи часового поясу. Він може використовуватися для обробки пакетних запитів над історичними даними, тоді як Apache HBase може використовуватися Facebook або LinkedIn для обміну повідомленнями та в режимі реального часу. Його також можна використовувати для підрахунку лайків.
Таблиця порівняння Apache Hive vs Apache HBase
Я обговорюю основні артефакти і розрізняю Apache Hive та Apache HBase.
| Apache вулик | Apache HBase | |
| Обробка даних | Apache вулик використовується для
пакетна обробка, тобто Інтернет-аналітична обробка (OLAP) | Apache HBase використовується для транзакційної обробки, тобто Інтернет-транзакційної обробки (OLTP) |
| Швидкість обробки | Apache Hive має більш високу затримку через виконання завдання MapReduce у фоновому режимі | Apache HBase працює на запити в режимі реального часу і набагато швидше, ніж Apache Hive |
| Сумісність з Hadoop | Вулик Apache працює на вершині MapReduce | Apache HBase працює поверх HDFS |
| Визначення | Apache Hive є відкритим кодом і схожий на SQL, що використовується для аналітичних запитів | Apache HBase - це база даних NoSQL з відкритим кодом, що використовується для запитів у режимі реального часу |
| Спільні метадані | Дані, створені в Apache Hive, автоматично видно Apache HBase | Дані, створені в Apache HBase, автоматично помітні в Apache Hive |
| Схема | Apeche вулик підтримує схему для вставки даних у таблиці | Apache HBase - база даних без схем. |
| Оновити функцію | Функція оновлення є складною в Apache Hive | Користувач може дуже легко оновлювати дані в Apache HBase |
| Операції | Операції в вулику Apache не виконуються в режимі реального часу | Операції в Apache HBase проводяться в режимі реального часу |
| Типи даних | Apache Hive призначений для структурованих та напівструктурованих даних | Apache HBase призначений для неструктурованих даних. |
| Рівень узгодженості | Вулик Apache підтримує консистенцію | Apache HBase підтримує негайну консистенцію |
| Методи розділення | Apache Hive підтримує функції Sharding | Apache HBase також підтримує функції Sharding |
| Зберігання даних | Дата зберігається в вулику Metastore, перегородках та відрах у вулику Apache | Дані зберігаються у стовпцях та рядках таблиць у Apache HBase |
Висновок - Apache Hive проти Apache HBase
Зазвичай Apache Hive vs Apache HBase використовується разом в одному кластері. Обидва можуть бути використані разом для підвищення потужності процесора. Оскільки вулик покращує аналітичні сторони HDFS, тоді як HBase покращує транзакції в режимі реального часу. Користувач може використовувати Hive як інструмент ETL для пакетних вставок з даними в HBase, а потім виконувати запити, які можуть додатково з'єднувати дані, присутні в таблицях HBase, з даними, які вже є на HDFS. Дані можна прочитати і записати з Apache Hive в HBase і знову. Інтерфейс між Apache Hive та Apache HBase досі дозріває. Попереду ще багато. Але я можу сказати, що обидва Apache Hive проти Apache HBase роблять кластер Hadoop більш надійним та потужним.
Схожі статті:
Це керівництво щодо Apache Hive проти Apache HBase, їх значення, порівняння між головами, ключові відмінності, таблиця порівняння та висновок. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Топ-5 великих тенденцій даних
- 5 викликів аналітики великих даних
- Як зламати інтерв'ю розробника Hadoop?
- 5 викликів аналітики великих даних