

Вступ до Apache Flume
Apache Flume - це система поглинання даних, яка записує дані на основі подій у розподілену файлову систему Hadoop. Відомий факт, що Hadoop обробляє великі дані, виникає питання, як дані, що генеруються з різних веб-серверів, передаються у файлову систему Hadoop? Відповідь - Apache Flume. Flume розроблений для прийому даних Hadoop, що базуються на подіях, з великим обсягом.
Розглянемо сценарій, коли кількість веб-серверів генерує файли журналів, і ці файли журналів потрібно передавати до файлової системи Hadoop. Flume збирає ці файли як події та передає їх Hadoop. Хоча Flume використовується для передачі до Hadoop, немає жорсткого правила, згідно з яким пунктом призначення повинен бути Hadoop. Flume здатний писати в інші рамки, такі як Hbase або Solr.
Flume Architecture
Загалом архітектура Apache Flume складається з таких компонентів:
- Джерело флюму
- Flume Channel
- Мухоморка
- Flume Agent
- Flume Event
Давайте коротко розглянемо кожен компонент Flume
1. Джерело диму
Джерело потоку присутнє в таких генераторах даних, як Face Book або Twitter. Джерело збирає дані з генератора і передає ці дані на канал Flume у вигляді подій Flume. Flume підтримує різні типи джерел, таких як Avro Flume Source - підключається до порту Avro та приймає події від зовнішнього клієнта Avro, Thrift Flume Source - підключається до порту Thrift та отримує події із зовнішніх потоків клієнтів Thrift, Spooling Source Source та Kafka Flume Source.
2. Підвісний канал
Проміжний магазин, який буферизує події, що надсилаються Flume Source, поки вони не будуть спожиті Sink, називається Flume Channel. Канал виступає проміжним мостом між Джерелом та Раковиною. Механічні канали мають транзакційний характер.
Flume забезпечує підтримку файлового каналу та каналу пам'яті. Файловий канал має довговічний характер, що означає, що коли дані будуть записані на канал, вони не втрачаються, хоча якщо агент перезапуститься. У пам'яті події каналу зберігаються в пам'яті, тому він не є довговічним, але дуже швидким.
3. Раковина
Раковина присутня в сховищах даних, таких як HDFS, HBase. Раковина Flume споживає події з каналу та зберігає їх у магазинах призначення, таких як HDFS. Не існує правила, згідно з яким мийка повинна доставляти події в Store, натомість ми можемо налаштувати її таким чином, щоб мийка могла доставляти події іншому агенту. Flume підтримує різні мийки, такі як раковина HDFS, раковина вулика, ощадливість, мийка Avro.
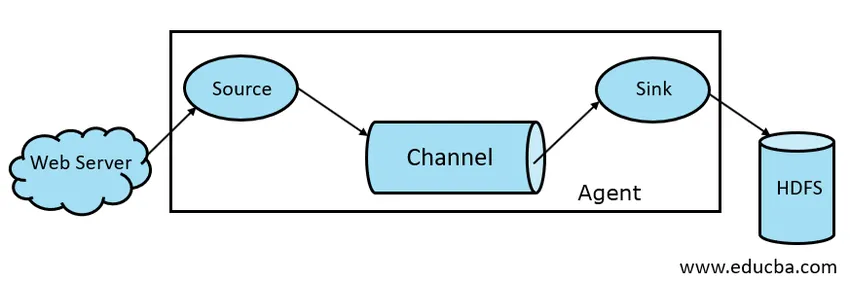
Рис. 1.1 Основна архітектура димоходу
4. Агент з флюмом
Агент Flume - це тривалий процес Java, який працює на поєднанні Source - Channel - Sink. Флюм може мати більше одного агента. Ми можемо розглядати Flume як сукупність пов'язаних агентів Flume, які розповсюджуються в природі.
5. Flume Event
Подія - одиниця даних, що передаються у Flume . Загальне представлення об'єкта даних у Flume називається подій. Подія складається з корисного набору байтового масиву з необов'язковими заголовками.
Робота Flume
Агент Flume - це процес Java, який складається з джерела - каналу - раковини в найпростішому вигляді. Джерело збирає дані з генератора даних у формі подій та передає їх на канал. Джерело може доставляти в декілька каналів відповідно до вимог. Вивільнення вентиляторів - це процес, коли одне джерело запише на кілька каналів, щоб вони могли доставляти декілька раковин.
Подія - це основна одиниця даних, що передаються у Flume. Канал зберігає дані до тих пір, поки Sink не почне їх поглинання. Sink збирає дані з каналу та доставляє їх у централізоване сховище даних, як HDFS, або Sink може пересилати ці події до іншого агента Flume відповідно до вимог.
Flume підтримує транзакції. Щоб досягти надійності, Flume використовує окремі транзакції від джерела до каналу та від каналу до раковини. Якщо події не доставлені, транзакція відкочується назад і пізніше буде повторно передана.
Для того, щоб зрозуміти роботу Flume, скористаємося прикладом конфігурації Flume, де джерелом є спіл-каталог, а раковиною - Hdfs. У цьому прикладі агент Flume знаходиться в найпростішій формі, тобто єдиній топології протоколу каналу джерела, яка налаштована за допомогою файлу властивостей Java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
У наведеному вище прикладі конфігурації агент - це база, за допомогою якої ми визначаємо інші властивості. source1 і sink1 та channel1 - це назви джерела, раковини та каналу відповідно, а їхні типи та місця також згадуються відповідно.
Переваги Apache Flume
- Флюм є масштабованим, надійним та стійким до відмов. Ці властивості детально розглядаються нижче
- Масштабованість - Флюм можна масштабувати горизонтально, тобто ми можемо додати нові вузли відповідно до нашої вимоги
- Надійно - Apache Flume має підтримку транзакцій і забезпечує відсутність втрачених даних у процесі передачі даних. Він має різні транзакції від джерела до каналу та від каналу до джерела.
- Flume налаштовується та надає підтримку різних джерел та мийок, таких як Kafka, Avro, каталог котушок, ощадливість тощо
- У Flume, одне джерело може передавати дані в кілька каналів, і ці канали, в свою чергу, передаватимуть дані в кілька раковин, таким чином, одне джерело може передавати дані в кілька раковин. Цей механізм називається вентилятором. Flume також підтримує Fan Fan.
- Flume забезпечує стабільний потік передачі даних, тобто якщо швидкість читання даних збільшується, а також швидкість запису даних також збільшується.
- Хоча Flume зазвичай записує дані в централізоване сховище, наприклад HDFS або Hbase, ми можемо налаштувати Flume відповідно до наших вимог, щоб Sink міг записувати дані в інший агент. Це показує гнучкість Flume
- Apache Flume є відкритим джерелом у природі.
Висновок
У цій статті Flume детально обговорюються компоненти Flume та робота Flume. Flume - це гнучка, надійна і масштабована платформа для передачі даних до централізованого магазину, наприклад HDFS. Його здатність інтегруватися з різними програмами, такими як Kafka, Hdfs, Thrift, робить її життєздатним варіантом для прийому даних.
Рекомендовані статті
Це було керівництво Apache Flume. Тут ми обговорюємо архітектуру, роботу та переваги Apache Flume. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Що таке Apache Flink?
- Різниця між Apache Kafka і Flume
- Велика архітектура даних
- Інструменти Hadoop
- Дізнайтеся про різні події JavaScript