

Питання та відповіді щодо глибокого вивчення інтерв'ю
Сьогодні «Глибоке навчання» розглядається як одна з найбільш швидко зростаючих технологій з величезною можливістю розробити додаток, який певний час вважався жорстким. Розпізнавання мовлення, розпізнавання зображень, знаходження шаблонів у наборі даних, класифікація об'єктів на фотографіях, генерування тексту персонажів, самостійне керування автомобілями та багато іншого - лише декілька прикладів, коли глибоке навчання показало свою важливість.
Таким чином, ви нарешті знайшли роботу своєї мрії в Deep Learning, але цікавитесь, як зламати інтерв'ю Deep Learning та що може бути імовірним питанням інтерв'ю для глибокого навчання. Кожне інтерв'ю різне, а сфера роботи теж різна. Маючи це на увазі, ми розробили найпоширеніші запитання та відповіді щодо глибокого вивчення інтерв'ю, які допоможуть вам досягти успіху в інтерв'ю.
Нижче наведено кілька питань щодо інтерв'ю з глибоким навчанням, які часто задаються в інтерв'ю, а також допоможуть перевірити свої рівні:
Частина 1 - Питання для інтерв'ю з глибоким вивченням (основні)
Ця перша частина охоплює основні запитання та відповіді щодо глибокого вивчення інтерв'ю
1. Що таке глибоке навчання?
Відповідь:
Область машинного навчання, яка зосереджена на глибоких штучних нейронних мережах, які надихнуті мізком. Олексій Григорович Івахненко опублікував першу генеральну працюючу мережу Deep Learning. Сьогодні вона має своє застосування у різних сферах, таких як комп’ютерний зір, розпізнавання мовлення, обробка природних мов.
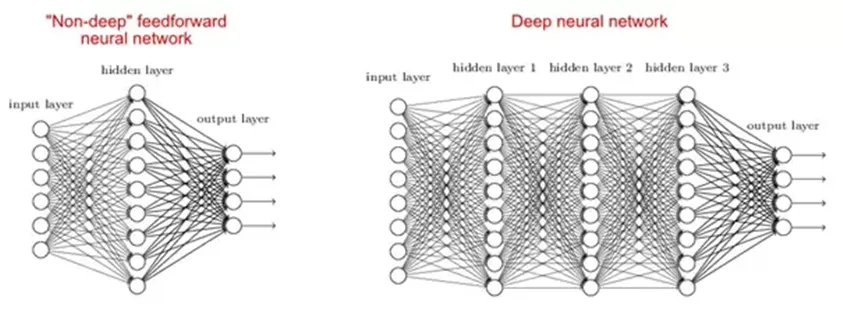
2. Чому глибокі мережі краще, ніж дрібні?
Відповідь:
Існують дослідження, які говорять про те, що як дрібні, так і глибокі мережі можуть підходити під будь-яку функцію, але оскільки глибокі мережі мають кілька прихованих шарів, часто різних типів, тому вони здатні будувати або вилучати кращі функції, ніж дрібні моделі з меншими параметрами.
3. Що таке функція витрат?
Відповідь:
Функція витрат - це міра точності нейронної мережі щодо даного навчального зразка та очікуваного виходу. Це єдине значення, невекторне, оскільки дає продуктивність нейронної мережі в цілому. Він може бути обчислений нижче функції середньої помилки середнього квадрату: -
MSE = 1n∑i = 0n (Y i – Yi) 2
Де Y і бажане значення Y - це те, що ми хочемо мінімізувати.
Перейдемо до наступних питань глибокого вивчення інтерв'ю.
4. Що таке градієнтний спуск?
Відповідь:
Спуск градієнта - це в основному алгоритм оптимізації, який використовується для вивчення значення параметрів, що мінімізує функцію витрат. Це ітеративний алгоритм, який рухається в напрямку найкрутішого спуску, визначеного від'ємником градієнта. Ми обчислюємо градієнтне зменшення функції вартості для заданого параметра та оновлюємо параметр за нижченаведеною формулою: -
Θ: = Θ – αd∂ΘJ (Θ)
Де Θ - вектор параметра, α - швидкість навчання, J (Θ) - функція витрат.
5. Що таке зворотна розмноження?
Відповідь:
Зворотне розповсюдження - це алгоритм навчання, який використовується для багатошарової нейронної мережі. У цьому методі ми переміщуємо помилку з кінця мережі на всі ваги всередині мережі, тим самим дозволяючи ефективно обчислювати градієнт. Його можна розділити на кілька етапів так:
Попередження розповсюдження навчальних даних з метою отримання результатів.
HenТоді з використанням цільового значення та похідної помилки вихідного значення можна обчислити відносно активації виходу.
HenЗараз ми повернемо розповсюдження для обчислення похідної помилки щодо активації виводу на попередньому і продовжимо це для всіх прихованих шарів.
Використовуючи раніше обчислені похідні для виведення та всіх прихованих шарів, ми обчислюємо похідні помилок щодо ваг.
Then А потім ми оновлюємо ваги.
6. Поясніть наступні три варіанти градієнтного спуску: партійний, стохастичний та міні-партійний?
Відповідь:
Стохастичний спуск градієнта : Тут ми використовуємо лише єдиний приклад навчання для обчислення параметрів градієнта та оновлення.
Пакетний градієнт спуск : Тут ми обчислюємо градієнт для всього набору даних та виконуємо оновлення на кожній ітерації.
Міні-пакетний градієнт спуск : Це один з найпопулярніших алгоритмів оптимізації. Це варіант стохастичного градієнтного спуску і тут замість єдиного навчального прикладу використовується міні-серія зразків.
Частина 2 - Питання для інтерв'ю глибокого навчання (розширено)
Давайте тепер ознайомимось із розширеними питаннями інтерв'ю для глибокого навчання.
7. Які переваги міні-партійного градієнтного спуску?
Відповідь:
Нижче наведено переваги мініатюрного градієнтного спуску
• Це більш ефективно в порівнянні зі стохастичним градієнтом.
• Узагальнення шляхом знаходження плоских мінімумів.
• Міні-партії дозволяють допомогти наблизити градієнт всього навчального набору, що допомагає нам уникнути місцевих мінімумів.
8. Що таке нормалізація даних і навіщо вона нам потрібна?
Відповідь:
Нормалізація даних використовується під час розмноження. Основним мотивом нормалізації даних є зменшення або усунення надмірності даних. Тут ми масштабуємо значення, щоб підходити до певного діапазону для досягнення кращої конвергенції.
Перейдемо до наступних питань глибокого вивчення інтерв'ю.
9. Що таке ініціалізація ваги в нейронних мережах?
Відповідь:
Ініціалізація ваги - один з дуже важливих кроків. Неправильна ініціалізація ваги може перешкодити навчанню мережі, але хороша ініціалізація ваги допомагає швидшій конвергенції та покращенню загальної помилки. Biases можуть бути ініціалізовані до нуля. Правило встановлення ваг - бути близьким до нуля, не будучи занадто малим.
10. Що таке автокодер?
Відповідь:
Автоенкодер - це автономний алгоритм машинного навчання, який використовує принцип зворотного розповсюдження, де цільові значення встановлюються рівними введеним введенням. Всередині нього є прихований шар, який описує код, який використовується для представлення вводу.
Деякі основні факти щодо автокодера:
• Це непідтримуваний алгоритм ML, подібний до аналізу основних компонентів
• Це мінімізує ту саму цільову функцію, що і аналіз основних компонентів
• Це нейромережа
• Цільовим виходом нейронної мережі є її вхід
11. Чи правильно підключатись із виходу рівня 4 до входу рівня 2?
Відповідь:
Так, це можна зробити, враховуючи, що вихід рівня 4 відбувається з попереднього етапу часу, як у RNN. Крім того, ми повинні припустити, що попередня вхідна партія іноді співвідноситься з поточною партією.
Перейдемо до наступних питань глибокого вивчення інтерв'ю.
12. Що таке машина Больцмана?
Відповідь:
Машина Больцмана використовується для оптимізації рішення проблеми. Робота машини Boltzmann полягає в оптимізації ваг і кількості для даної проблеми.
Деякі важливі моменти щодо машини Больцмана -
• Він використовує структуру, що повторюється.
• Він складається з стохастичних нейронів, які складаються з одного з двох можливих станів, або 1, або 0.
• Нейрони в цьому знаходяться або в адаптаційному (вільному стані), або затисненому (замороженому) стані.
• Якщо ми застосуємо імітований відпал на дискретних мережах Хопфілда, то це стане машиною Больцмана.
13. Яка роль функції активації?
Відповідь:
Функція активації використовується для введення нелінійності в нейронну мережу, допомагаючи їй вивчити більш складні функції. Без якого нейронна мережа змогла б вивчити лише лінійну функцію, яка є лінійною комбінацією вхідних даних.
Рекомендовані статті
Це було керівництвом щодо списку питань та відповідей щодо глибокого вивчення інтерв'ю, щоб кандидат міг легко розірвати ці питання щодо глибокого вивчення інтерв'ю. Ви також можете переглянути наступні статті, щоб дізнатися більше
- Дізнайтеся топ-10 найкорисніших запитань щодо інтерв'ю HBase
- Корисні запитання та відповіді щодо інтерв'ю машинного навчання
- Топ-5 найцінніших запитань щодо інтерв'ю щодо даних
- Важливі запитання та відповіді щодо інтерв'ю Ruby