
Різниця між Hadoop і Redshift
Hadoop - це програма з відкритим кодом, розроблена Apache Software Foundation з її основними перевагами масштабованості, надійності та розподілених обчислень. Обробка даних, зберігання, доступ, безпека - це кілька типів функцій, доступних в екосистемі Hadoop. HDFS має високу пропускну здатність, що означає можливість обробляти велику кількість даних з можливістю паралельної обробки. Redshift - це хмарний веб-сервіс, розроблений підрозділом веб-служб Amazon в Amazon.com Inc., з існуючих послуг, що надаються Amazon. Він використовується для проектування масштабного сховища даних у хмарі. Redshift - це послуга сховища даних у масштабі петабайт, яка повністю керується та економічно ефективно працювати на великих наборах даних.
Докладно вивчимо детальніше про Hadoop та Redshift:
Hadoop HDFS має високу здатність до відмовок і був розроблений для роботи на апаратних системах з низькими витратами. Hadoop може обробляти мінімальний розмір файлів TeraBytes до GigaBytes у межах своєї системи. HDFS - це архітектура головного управління, що складається з вузлів імен та вузлів даних, де вузол імен містить метадані, а вузол даних містить реальні дані, що підлягають обробці або експлуатації.
RedShift використовує різні методи завантаження даних, такі як звітність BI (Business Intelligence), аналітичні інструменти та обмін даними. Redshift надає консоль для створення та керування кластерами Amazon Redshift. Основним компонентом Redshift Data Warehouse є кластер.
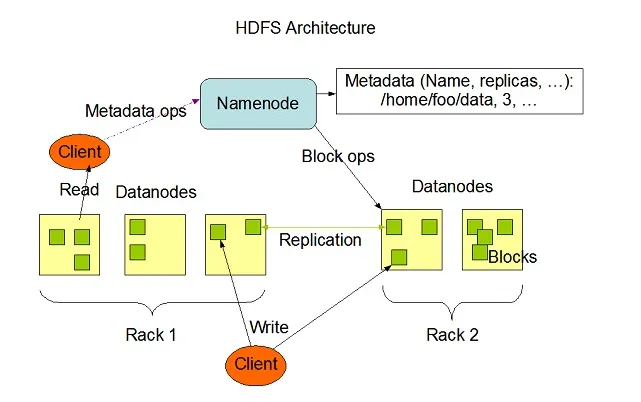
Джерело зображення: Apache.org
Архітектура RedShift:
 Джерело зображення: Amazon.com
Джерело зображення: Amazon.com
Порівняння «голова до голови» між Hadoop проти Redshift (Інфографіка):
Нижче представлено 10 кращих порівнянь між Hadoop та Redshift

Основні відмінності між Hadoop і Redshift:
Нижче наведено ключові відмінності між Hadoop проти Redshift як наступні
1. Архітектура Hadoop HDFS (розподіленої файлової системи Hadoop) має вузли імен та вузли даних, тоді як Redshift має лідерний вузол та вузли обчислень, де вузли обчислень будуть розподілені як фрагменти.
2. Hadoop надає інтерфейс командного рядка для взаємодії з файловою системою, тоді як RedShift має консоль управління для взаємодії з послугами зберігання Amazon, такими як S3, DynamoDB тощо,
3. Операції з базою даних повинні бути налаштовані розробниками. У Redshift автоматизує операції з базою даних шляхом аналізу планів виконання.
4.Hadoop має декілька сторонніх інструментів, які легко інтегруються, тоді як Redshift підтримує лише ті продукти, розроблені Amazon у своїй хмарі.
5.З точки зору архітектурного дизайну Hadoop мережа, зберігання, безпека та продуктивність вважаються первинними елементами, тоді як у Redshift ці елементи можна легко та гнучко налаштувати за допомогою консолі управління хмарою Amazon.
6.Hadoop - це архітектура файлової системи, що базується на інтерфейсах прикладного програмування Java (API), тоді як Redshift базується на реляційній моделі управління базами даних (RDBMS).
7.Hadoop може мати інтеграцію з різними постачальниками, і Redshift не має підтримки в цьому випадку, коли Amazon є їхнім єдиним постачальником. Що робити, якщо користувач незадоволений послугою? У цьому випадку Hadoop є перевагою.
8. Більшість існуючих компаній все ще використовують Hadoop, тоді як нові клієнти вибирають RedShift.
9.Зважаючи на ефективність, Hadoop завжди не вистачає, а Redshift завжди перемагає у випадку виконання запитів на великих обсягах даних.
10.Hadoop використовує модель програмування Map Reduce для запуску завдань. Amazon Redshift використовує Amazo's Elastic Map Reduce.
11.Hadoop використовує модель програмування Map Reduce для запуску завдань. Amazon Redshift використовує Amazo's Elastic Map Reduce.
12.Hadoop бажано запускати пакетні завдання щодня, що стає дешевшим, тоді як Redshift виходить дешевшим у випадку технології онлайн-аналітичної обробки (OLAP), яка існує за багатьма інструментами Business Intelligence.
13.Hadoop у 10 разів повільніше, ніж Redshift, у запущених запитах аналогічно Hadoop в 10 разів дорожче, ніж Redshift, що призводить до того, що Hadoop буде як мінімум обраний перед Redshift.
14. І в плані завантаження даних Hadoop відстає від Redshift, якщо система займає години для завантаження даних із сховища у свою систему обробки файлів.
15.Hadoop може використовуватися для недорогих сховищ, архівації даних, озер даних, зберігання даних та аналізу даних, тоді як Redshift знаходиться під можливостями сховища даних, що обмежує багатоцільове використання.
16. Платформа Hadoop забезпечує підтримку різних зовнішніх постачальників та власних проектів Apache, таких як Storm, Spark, Kafka, Solr тощо, а з іншого боку Redshift має обмежену підтримку інтеграції зі своїми єдиними продуктами Amazon
Таблиця порівняння Hadoop проти Redshift
| ОСНОВА ДЛЯ
ПОРІВНЯЙТЕ | HADOOP | КРАСНИЙ РОЗДІЛ |
| Доступність | Рамка з відкритим кодом від Apache Projects | Цінні послуги, що надаються Amazon |
| Впровадження | Забезпечується постачальниками Hortonworks та Cloudera тощо, | Розроблений та наданий Amazon |
| Продуктивність | Завдання Hadoop MapReduce повільніше | Redshift працює швидше, ніж кластер Hadoop |
| Масштабованість | Обмеження масштабованості | Легко змінювати / зменшувати розмір відповідно до вимог |
| Ціноутворення | Витрати 200 доларів на місяць для запуску запитів | Ціна залежить від регіону сервера і дешевша, ніж Hadoop
Напр .: $ 20 / місяць |
| Швидкість | Швидше, але повільніше порівняно з Redshift | У 10 разів швидше, ніж у Hadoop |
| Швидкість запиту | Для запуску даних 1, 2 ТБ потрібно 1491 секунди | 155 секунд для запуску даних 1, 2 ТБ |
| Інтеграція даних | Гнучка з локальною файловою системою та будь-якою базою даних | Можна завантажувати дані лише з Amazon S3 або DynamoDB |
| Формат даних | Всі формати даних підтримуються | Суворий у форматах даних, таких як формати файлів CSV |
| Простота використання | Складніші та складніші для управління адміністративною діяльністю | Автоматизоване управління резервними копіями та сховищами даних |
Висновок - Hadoop проти Redshift
Остаточне твердження про висновок великого переможця в цьому порівнянні - Redshift, який виграє з точки зору простоти в експлуатації, технічному обслуговуванні та продуктивності, тоді як Hadoop не вистачає з точки зору масштабності продуктивності та вартості послуг з єдиною вигодою від простої інтеграції із сторонніми інструментами та продукти. Redshift останнім часом розвивається з величезним зростанням та прийняттям багатьма клієнтами та клієнтами завдяки високій доступності та меншій вартості операцій порівняно з Hadoop робить її все більш популярною. Але до цих пір більшість існуючих компаній Fortune 1000 використовували платформи Hadoop у своїх архітектурах для управління даними про клієнтів.
У більшості випадків RedShift був найкращим вибором для розгляду в ділових цілях будь-яким клієнтом або клієнтом, щоб обробляти великі та конфіденційні дані будь-яких фінансових установ або публічну інформацію з більшою цілісністю та безпекою даних.
Крім цього Hadoop має свої переваги, оскільки це проект з відкритим кодом, і він був доступний протягом багатьох років, а також викликає заміну існуючих систем як процес, що пов'язаний з витратами. Продукт слід остаточно вибирати виходячи з вимог та гнучкості, а не на ціноутворення чи популярність, виходячи з потреб бізнесу.
Рекомендована стаття:
Це було керівництвом щодо Hadoop vs Redshift, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Хадоп проти вулика - з’ясуйте найкращі відмінності
- HADOOP vs RDBMS | Знай 12 корисних відмінностей
- Apache Hadoop vs Apache Spark | Топ-10 порівнянь, які ти повинен знати!
- Big Data vs Science Data - чим вони відрізняються?
- Путівник по Hadoop vs Spark
- Топ-4 постачальників хмарних хостингів із можливостями