
Огляд алгоритмів нейронної мережі
- Давайте спочатку дізнаємося, що означає нейронна мережа? Нейронні мережі надихаються біологічними нейронними мережами в мозку або, можна сказати, нервовою системою. Це викликало велике хвилювання, і дослідження все ще тривають у цій підмножині машинного навчання в промисловості.
- Основною обчислювальною одиницею нейронної мережі є нейрон або вузол. Він отримує значення від інших нейронів і обчислює вихід. Кожен вузол / нейрон асоціюється з вагою (w). Ця вага надається відповідно до відносної важливості конкретного нейрона або вузла.
- Отже, якщо ми візьмемо f як функцію вузла, то функція вузла f забезпечить вихід, як показано нижче: -
Вихід нейрона (Y) = f (w1.X1 + w2.X2 + b)
- Там, де w1 і w2 - вага, X1 і X2 є числовими входами, тоді як b - зміщення.
- Вищенаведена функція f - нелінійна функція, яка також називається функцією активації. Його основна мета полягає в запровадженні нелінійності, оскільки майже всі дані реального світу є нелінійними, і ми хочемо, щоб нейрони вивчили ці уявлення.
Різні алгоритми нейронної мережі
Давайте тепер розглянемо чотири різні алгоритми нейронної мережі.
1. Спуск градієнта
Це один з найпопулярніших алгоритмів оптимізації в галузі машинного навчання. Він використовується під час навчання моделі машинного навчання. Простими словами, він в основному використовується для пошуку значень коефіцієнтів, які просто максимально знижують функцію витрат. Спочатку ми починаємо з визначення деяких значень параметрів, а потім, використовуючи обчислення, починаємо ітераційно регулювати значення, щоб втрачена функція знижується.
Тепер давайте перейдемо до частини, що таке градієнт ?. Таким чином, градієнт означає, що на багато разів результат будь-якої функції зміниться, якщо ми зменшимо вхід на невелику кількість, або іншими словами, ми можемо викликати його до схилу. Якщо схил крутий, модель навчиться швидше, аналогічно модель перестає вчитися, коли нахил дорівнює нулю. Це тому, що це алгоритм мінімізації, який мінімізує заданий алгоритм.
Нижче формула знаходження наступної позиції показана у випадку спуску градієнта.
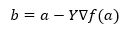
Де b - наступна позиція
a - поточне положення, гамма - функція очікування.
Отже, як ви бачите, градієнтний спуск - це дуже звукова техніка, але є багато областей, де спуск градієнта працює неправильно. Нижче наведено деякі з них:
- Якщо алгоритм не виконаний належним чином, ми можемо зіткнутися з чимось на зразок проблеми зниклого градієнта. Вони виникають, коли градієнт занадто малий або занадто великий.
- Проблеми виникають, коли розташування даних створює проблему оптимізації, що не є опуклою. Градієнт гідний працює лише з проблемами, які є опуклою оптимізованою проблемою.
- Одним з дуже важливих факторів, на який слід звернути увагу при застосуванні цього алгоритму, є ресурси. Якщо у нас менше пам'яті, призначеної для програми, нам слід уникати алгоритму спуску градієнта.
2. Метод Ньютона
Це алгоритм оптимізації другого порядку. Його називають другим порядком, оскільки він використовує матрицю Гессі. Отже, матриця Гессена - це не що інше, як квадратна матриця часткових похідних другого порядку скалярної функції. В алгоритмі оптимізації методу Ньютона застосовується до першої похідної подвійної диференційованої функції f, щоб вона змогла знайти коріння / стаціонарні пункти. Тепер перейдемо до етапів, необхідних для оптимізації методом Ньютона.
Він спочатку оцінює індекс збитків. Потім він перевіряє, чи критерії зупинки істинні чи помилкові. Якщо помилково, то він обчислює напрям тренувань Ньютона і швидкість тренувань, а потім покращує параметри або вагу нейрона і знову той же цикл триває. Отже, тепер ви можете сказати, що потрібно менше кроків порівняно зі спуском градієнта, щоб отримати мінімум значення функції. Хоча це потребує менших кроків порівняно з алгоритмом спуску градієнта, він все ще не використовується широко, оскільки точний розрахунок гессіана та його зворотна обчислювальна обчислювальна дуже дорого.
3. Кон'югатний градієнт
Це метод, який можна розглядати як щось середнє між схилом градієнта та методом Ньютона. Основна відмінність полягає в тому, що вона прискорює повільну конвергенцію, яку ми, як правило, асоціюємо з градієнтним спуском. Ще одним важливим фактом є те, що він може використовуватися як для лінійних, так і для нелінійних систем, і це ітеративний алгоритм.
Його розробили Магнус Гестенес і Едуард Стіфель. Як вже було сказано вище, що він виробляє швидше конвергенцію, ніж спуск градієнта. Причина, яку це вдається зробити, полягає в тому, що в алгоритмі Conjugate Gradient пошук проводиться разом із спряженими напрямками, завдяки яким він конвергується швидше, ніж алгоритми спуску градієнта. Важливим моментом, який слід зазначити, є те, що γ називається параметром спряженого.
Навчальний напрям періодично скидається на мінус градієнта. Цей метод є більш ефективним, ніж градієнтний спуск при навчанні нейронної мережі, оскільки йому не потрібна матриця Гессі, що збільшує обчислювальне навантаження, а також сходиться швидше, ніж градієнтне спускання. Доцільно використовувати у великих нейронних мережах.
4. Метод Квазі-Ньютона
Це альтернативний підхід до методу Ньютона, оскільки нам відомо, що метод Ньютона обчислювально дорогий. Цей метод вирішує ці недоліки в такій мірі, що замість обчислення матриці Гессіа та потім обчислення зворотного безпосередньо цей метод створює наближення до зворотного Гессіана при кожній ітерації цього алгоритму.
Тепер це наближення обчислюється, використовуючи інформацію з першої похідної функції втрат. Таким чином, ми можемо сказати, що це, мабуть, найбільш підходящий метод для роботи з великими мережами, оскільки це економить час на обчислення, а також це набагато швидше, ніж спуск градієнта або метод спряженого градієнта.
Висновок
Перш ніж ми закінчимо цю статтю, порівняємо обчислювальну швидкість та пам'ять для вищезазначених алгоритмів. Відповідно до вимог пам’яті, градієнтне спускання вимагає найменшого обсягу пам’яті, а також воно найбільш повільне. Навпаки, метод Ньютона вимагає більшої обчислювальної потужності. Отже, беручи до уваги все це, метод Квазі-Ньютона найкраще підходить.
Рекомендовані статті
Це був посібник з алгоритмів нейронної мережі. Тут ми також обговорюємо огляд алгоритму нейронної мережі разом з чотирма різними алгоритмами відповідно. Ви також можете ознайомитися з іншими запропонованими нами статтями, щоб дізнатися більше -
- Машинне навчання проти нейронної мережі
- Рамки машинного навчання
- Нейронні мережі проти глибокого навчання
- K- означає алгоритм кластеризації
- Керівництво по класифікації нейронної мережі