

Вступ у архітектуру Hadoop
Hadoop Architecture - це структура з відкритим кодом, яка допомагає легко обробляти великі набори даних. Це допомагає створювати додатки, які обробляють величезні дані з більшою швидкістю. Він використовує поняття розподілених обчислень, де дані поширюються по різних вузлах кластеру. Програми, побудовані за допомогою Hadoop, використовують товарні комп’ютери. Ці комп'ютери доступні легко на ринку за дешевими цінами. Цей результат - це більша обчислювальна потужність з низькою вартістю. Усі дані, наявні в Hadoop, розміщені на HDFS замість локальної файлової системи. HDFS - це розподілена файлова система Hadoop. Ця модель заснована на локальності даних, де обчислювальна логіка надсилається до вузлів, наявних у кластері, який містить дані. Ця логіка - це не що інше, як логіка, яка компілює програму.
Hadoop Архітектура
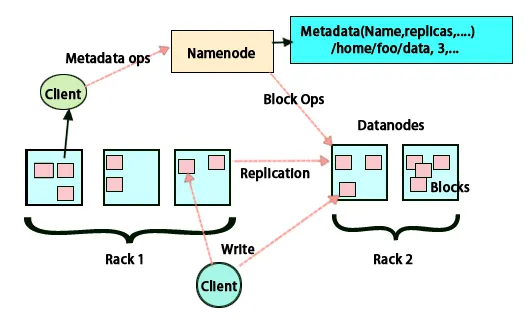
Основна ідея цієї архітектури полягає в тому, що все зберігання та обробка здійснюється в два етапи та двома способами. Перший крок - це обробка, яка виконується програмуванням зменшення карт, а другим кроком є збереження даних, що виконуються на HDFS. Він має головну-підлеглий архітектуру для зберігання та обробки даних. Головний вузол для зберігання даних в Hadoop - це вузол імені. Існує також головний вузол, який виконує роботу з моніторингу та паралельної обробки даних, використовуючи Hadoop Map Reduce. Раби - це інші машини кластеру Hadoop, які допомагають зберігати дані, а також виконують складні обчислення. Кожному підлеглому вузлу призначено трекер завдань, а вузол даних має інструмент відстеження завдань, який допомагає виконувати процеси та ефективно їх синхронізувати. Цей тип системи можна налаштувати як у хмарі, так і в приміщенні. Вузол Name - це єдина точка відмови, коли він не працює в режимі підвищеної доступності. В архітектурі Hadoop також передбачено підтримання вузла очікування від імені для захисту системи від збоїв. Раніше існували вторинні вузли імен, які виконували функцію резервного копіювання, коли основний вузол імені був відключений.
FSimage та редагування журналу
FSimage та Edit Log забезпечують стійкість метаданих файлової системи не відставати від усієї інформації та вузла імен, зберігаючи метадані у двох файлах. Ці файли - це FSimage та журнал редагування. Завдання FSimage - зберігати повний знімок файлової системи в даний момент часу. Зміни, які постійно вносяться в систему, потрібно вести облік. Ці додаткові зміни, як перейменування або додавання деталей до файлу, зберігаються в журналі редагування. Рамка забезпечує кращий варіант, а не створення кожного разу нового FSimage, кращий варіант - можливість зберігати дані під час нового файлу для FSimage. FSimage створює новий знімок щоразу, коли вносяться зміни Якщо вузол Name не вдається, він може відновити його попередній стан. Вузол вторинного імені також може оновлювати свою копію щоразу, коли в FSimage є зміни та редагувати журнали. Таким чином, це гарантує, що навіть незважаючи на те, що вузол імені не працює, при наявності вторинного вузла імен не буде втрати даних. Вузол імені не вимагає, щоб ці зображення повинні бути перезавантажені на вторинний вузол імені.
Реплікація даних
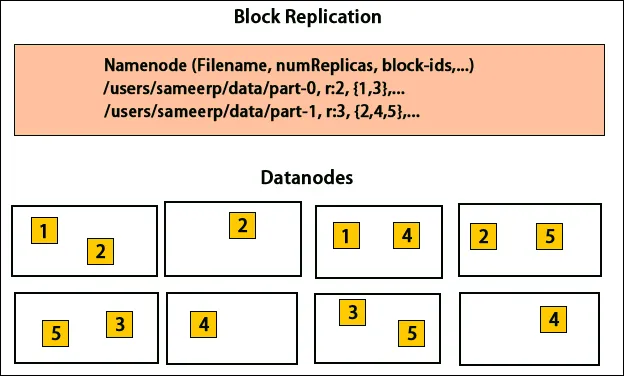
HDFS призначений для швидкої обробки даних та надання надійних даних. Він зберігає дані на машинах та у великих кластерах. Усі файли зберігаються в серії блоків. Ці блоки копіюються для відмовостійкості. Розмір блоку та коефіцієнт реплікації можуть визначати користувачі та налаштовуватись відповідно до вимог користувача. За замовчуванням коефіцієнт реплікації дорівнює 3. Коефіцієнт реплікації можна вказати під час створення файлу і його можна змінити пізніше. Усі рішення щодо цих реплік приймаються вузлом імені. Вузол імен продовжує надсилати серцебиття та блокувати звіт через рівні проміжки часу для всіх вузлів даних кластера. Прийом серцебиття означає, що вузол даних працює належним чином. Звіт про блок вказує перелік усіх блоків, присутніх у вузлі даних.
Розміщення реплік
Розміщення реплік є дуже важливим завданням Hadoop для надійності та продуктивності. Всі різні блоки даних розміщуються на різних стелажах. Реалізація розміщення реплік може здійснюватися відповідно до надійності, доступності та використання пропускної здатності мережі. Кластер комп'ютерів може бути розповсюджений на різних стелажах. На одній стійці можна розмістити не більше двох вузлів. Третю репліку слід розмістити на іншій стійці для забезпечення більшої достовірності даних. Два вузли на стійці спілкуються через різні комутатори. Вузол імені має ідентифікатор стійки для кожного вузла даних. Але розміщення всіх вузлів на різних стійках запобігає втраті будь-яких даних і дозволяє використовувати смугу пропускання з декількох стійок. Це також зменшує трафік між рейками та покращує продуктивність. Також шанс виходу з ладу стійки дуже менший порівняно з можливістю виходу з ладу вузла. Це зменшує сукупну пропускну здатність мережі, коли дані зчитуються з двох унікальних стелажів, а не з трьох.
Зменшити карту
Зменшення карт використовується для обробки даних, що зберігаються на HDFS. Він записує розподілені дані в розподілені додатки, що забезпечує ефективну обробку великої кількості даних. Вони переробляються на великих кластерах і вимагають товару, який є надійним і стійким до несправностей. Ядром зменшення карт можуть бути три операції, такі як картографування, збір пар і переміщення отриманих даних.
Висновок - архітектура Hadoop
Hadoop - це система з відкритим кодом, яка допомагає у відмовостійкій системі. Він може зберігати велику кількість даних і допомагає зберігати достовірні дані. Дві частини зберігання даних у HDFS та їх обробка через зменшення карт допомагають правильно та ефективно працювати. Вона має архітектуру, яка допомагає керувати всіма блоками даних, а також має найновішу копію, зберігаючи її у FSimage та редагуючи журнали. Коефіцієнт реплікації також допомагає копіювати дані та отримувати їх назад, коли виникає збій. HDFS також переміщує вилучені файли до каталогу сміття для оптимального використання місця.
Рекомендовані статті
Це був путівник архітектури Hadoop. Тут ми обговорили архітектуру, зменшення карти, розміщення реплік, реплікацію даних. Ви також можете ознайомитися з іншими запропонованими нами статтями, щоб дізнатися більше -
- Стати розробником Hadoop
- Вступ до Android
- Що таке Tableau? | Огляд
- Що таке MapReduce в Hadoop?