
Вступ у зміцнення навчання
Підсилення навчання - це тип машинного навчання, а отже, воно також є частиною Штучного інтелекту, коли застосовується до систем, системи виконують кроки та навчаються на основі результатів кроків, щоб отримати складну мету, яка встановлена для досягнення системи.
Зрозуміти, що навчається зміцненню
Спробуємо під час навчання підкріплення вивчити за допомогою 2 простих випадків використання:
Справа №1
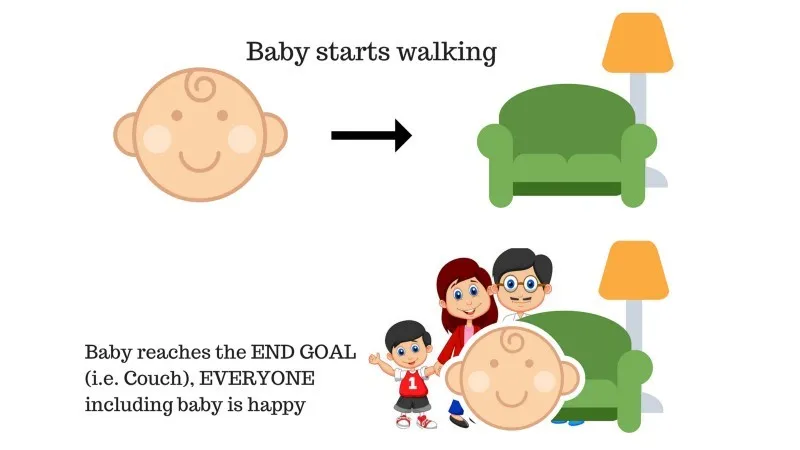
У сім’ї є дитина, і вона тільки почала ходити, і всі дуже раді цьому. Одного разу батьки намагаються поставити мету, давайте дитині дістатися до дивана, і подивимося, чи здатна дитина це зробити.
Результат 1 випадку: дитина успішно дістається до диванчика, і тому всі в сім'ї дуже раді бачити це. Обраний шлях тепер приносить позитивну винагороду.
Бали: нагорода + (+ n) → позитивна нагорода.
Джерело: https://images.app.goo.gl/pGCXJ1N1bzLAer126
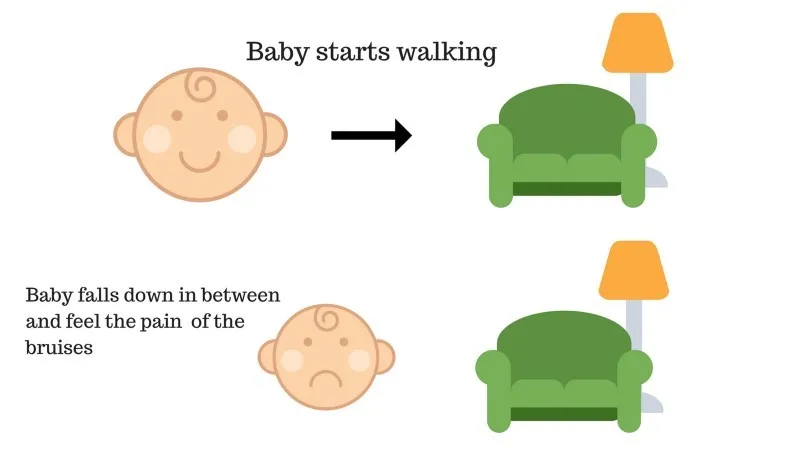
Справа №2
Дитина не змогла піднятися на диван, і дитина впала. Боляче! Що може бути причиною? На шляху до дивана можуть виникнути перешкоди, і дитина потрапила на перешкоди.
Результат випадку 2: Дитина потрапляє до якихось перешкод, і вона плаче! О, це було погано, вона дізналася, щоб наступного разу не потрапити в пастку перешкод. Обраний шлях тепер отримує негативну винагороду.
Бали: нагороди + (-n) → негативна нагорода.
Джерело: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Зараз ми бачили випадки 1 і 2, в яких навчальне підкріплення в принципі робить те саме, за винятком того, що воно не є людиною, а натомість виконується обчислювально.
Використання армування поетапно
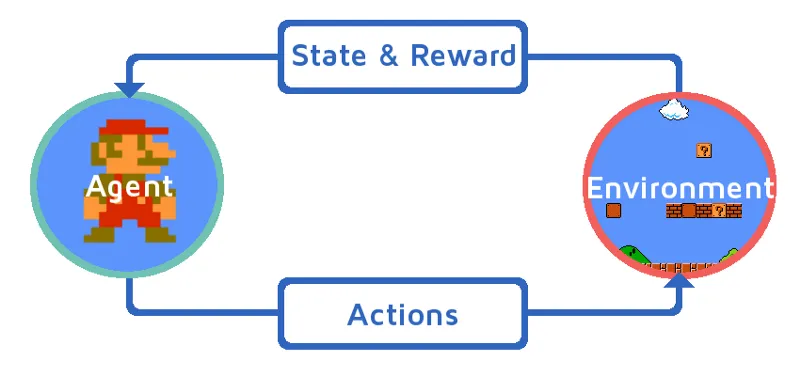
Давайте розберемося з навчанням підкріплення, поетапно запроваджуючи Арматурний агент. У цьому прикладі наш навчальний агент підкріплення - Маріо, який навчиться грати самостійно:
Джерело: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Поточний стан ігрового середовища Mario є S_0. Тому що гра ще не почалася, а Маріо на своєму місці.
- Далі гра починається і Маріо рухається, Маріо, тобто агент RL приймає і діє, скажімо, A_0.
- Тепер стан ігрового середовища перетворився на S_1.
- Крім того, агенту RL, тобто Маріо, тепер присвоюється позитивний бал R_1, ймовірно, тому, що Маріо все ще живий і жодної небезпеки не виникало.
Тепер вищезгаданий цикл буде продовжувати працювати, поки Маріо остаточно не помер, або Маріо не досягне місця призначення. Ця модель буде постійно виводити дію, винагороду та стан.
Нагороди за максимізацію
Метою посиленого навчання є максимізація винагороди за рахунок врахування деяких інших факторів, таких як знижка на винагороду; ми коротко пояснимо, що розуміється під знижкою за допомогою ілюстрації.
Сукупна формула дисконтованих винагород така:
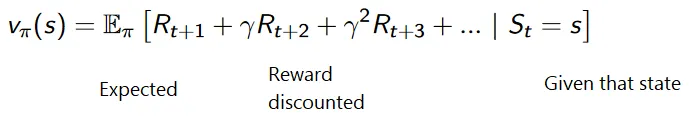
Дисконтні винагороди
Давайте зрозуміємо це на прикладі:
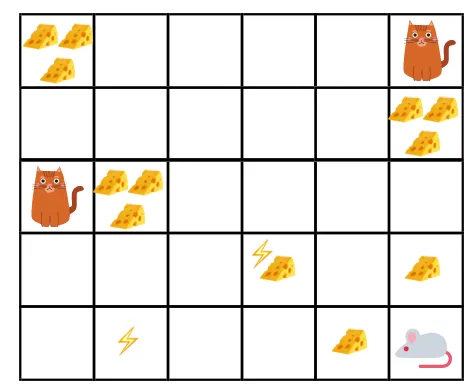
- На даній фігурі мета полягає в тому, що миша в грі повинна з'їсти стільки сиру, перш ніж їсти кішку або не зазнати електрошоку.
- Тепер ми можемо припустити, що чим ближче ми до кота чи електричної пастки, тим більше ймовірності ми допускаємо до того, що миша буде з'їдена чи шокована.
- Це означає, що навіть якщо у нас повний сир біля блоку ураження електричним струмом або біля кота, тим ризикованіше їхати туди, краще їсти сир, який знаходиться поруч, щоб уникнути будь-якого ризику.
- Тож навіть у нас є один «блок1» сиру, який повний і знаходиться далеко від котячого та електричного струму, а інший - «блок2», який також повний, але знаходиться поруч з котом або електричним струмом, пізніший сирний блок, тобто "block2", буде знижений у винагороді, ніж попередній.
Джерело: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Джерело: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Види підсилення навчання
Нижче наведено два типи навчання з підсиленням з їх перевагами та недоліками:
1. Позитивний
Коли сила і частота поведінки збільшуються через виникнення якоїсь конкретної поведінки, вона відома як Позитивне зміцнення навчання.
Переваги: продуктивність максимізована, і зміни залишаються на довший час.
Недоліки: Результати можна зменшити, якщо у нас занадто багато підкріплення.
2. Негативний
Це посилення поведінки, здебільшого через негативний термін зникає.
Переваги: поведінка посилюється.
Недоліки: лише мінімальна поведінка моделі може бути досягнута за допомогою негативного підкріплення навчання.
Де слід використовувати навчання для посилення?
Те, що можна зробити за допомогою навчального / прикладного підкріплення. Нижче наведені сфери, де в наші дні застосовується зміцнення навчання:
- Охорона здоров'я
- Освіта
- Ігри
- Комп'ютерне бачення
- Бізнес Менеджмент
- Робототехніка
- Фінанси
- NLP (Обробка натуральної мови)
- Перевезення
- Енергія
Кар'єра в навчанні зміцнення
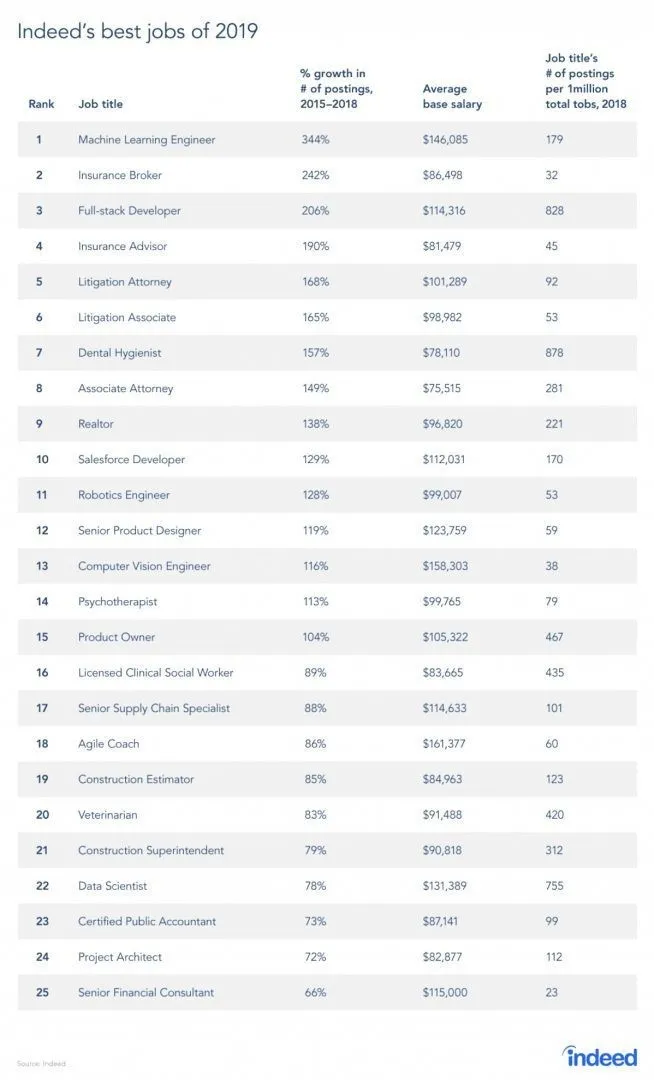
Насправді є звіт із сайту роботи, оскільки RL - це галузь машинного навчання, згідно з доповіддю, Машинне навчання - найкраща робота 2019 року. Нижче наведено короткий звіт звіту. Відповідно до сучасних тенденцій, інженери машинного навчання надходять із колосальною середньою заробітною платою в розмірі 146 085 доларів та зі зростанням 344 відсотків.
Джерело: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Навички для посилення навчання
Нижче наведено навички, необхідні для навчання підкріплення:
1. Основні навички
- Ймовірність
- Статистика
- Моделювання даних
2. Навички програмування
- Основи програмування та інформатики
- Дизайн програмного забезпечення
- Здатний застосовувати бібліотеки та алгоритми машинного навчання
3. Мови програмування машинного навчання
- Пітон
- R
- Хоча є й інші мови, де можуть бути спроектовані моделі машинного навчання, такі як Java, C / C ++, але Python та R - найбільш популярні мови.
Висновок
У цій статті ми почали з короткого вступу про підсилення навчання, а потім ми глибоко занурилися в роботу RL та різних факторів, які беруть участь у роботі моделей RL. Тоді ми навели кілька реальних прикладів, щоб зрозуміти ще краще тему. На кінець цієї статті слід добре розуміти роботу навчання з підсиленням.
Рекомендовані статті
Це посібник із питань Що таке зміцнення? Тут ми обговорюємо функцію та різні фактори, що беруть участь у розробці моделей навчання для посилення, із прикладами. Ви також можете ознайомитись з іншими нашими пов’язаними статтями, щоб дізнатися більше -
- Види алгоритмів машинного навчання
- Вступ до штучного інтелекту
- Інструменти штучного інтелекту
- Платформа IoT
- Топ 6 Мов машинного навчання