

Різниця між великими даними та Apache Hadoop
Все є в Інтернеті. В Інтернеті багато даних. Тому все - Big Data. Чи знаєте ви, що 2, 5 байта даних Quintillion створюються щодня і накопичуються як великі дані? Наші щоденні заходи, такі як коментування, подобається, публікації тощо у соціальних мережах, таких як Facebook, LinkedIn, Twitter та Instagram, додаються як великі дані. Передбачається, що до 2020 року буде створено майже 1, 7 мегабайт даних щосекунди для кожної людини на землі. Ви можете собі уявити і розглянути, скільки даних генерується, припускаючи кожну людину на землі. Сьогодні ми пов’язані та ділимося своїм життям в Інтернеті. Більшість з нас підключені до Інтернету. Ми живемо в розумному будинку та використовуємо розумні транспортні засоби, і всі вони підключені до наших смартфонів. Ви коли-небудь уявляєте, як ці пристрої стають розумними? Я хотів би дати вам дуже просту відповідь, це через аналіз дуже великого обсягу даних, тобто Big Data. Протягом п'яти років у світі з’явиться понад 50 мільярдів смарт-підключених пристроїв, усі розроблені для збору, аналізу та обміну даними, щоб зробити наше життя більш комфортним.
Далі наведено Введення великих даних проти Apache Hadoop
Представляємо великі дані терміна
Що таке великі дані? Який розмір даних вважається великим і називатиметься великими даними? У нас є багато відносних припущень щодо терміна Big Data. Можливо, що кількість даних, що говорять, 50 терабайт, може розглядатися як великі дані для запуску, але це може бути не великими даними для таких компаній, як Google і Facebook. Це тому, що у них є інфраструктура для зберігання та обробки такої кількості даних. Я б хотів визначити термін Big Data як:
- Big Data - це обсяг даних, що виходить за межі можливостей технології зберігати, керувати та обробляти ефективніше.
- Big Data - це дані, масштаб, різноманітність та складність потребують нової архітектури, прийомів, алгоритмів та аналітики для управління ними та отримання з неї цінності та прихованих знань.
- Великі дані - це об'ємні та високошвидкісні та різноманітні інформаційні активи, які вимагають економічно ефективних, інноваційних форм обробки інформації, що дозволяють розширити огляд, прийняття рішень та автоматизацію процесів.
- Big Data стосується технологій та ініціатив, які включають занадто різноманітні, швидкозмінні або масові дані для звичайних технологій, навичок та інфраструктури, щоб ефективно їх вирішувати. За різними словами, об'єм, швидкість чи різноманітність даних занадто великі.
3 V великих даних
- Об'єм: Обсяг означає кількість / кількість, на яку створюються дані, як щогодини, транзакції клієнтів Wal-Mart надають компанії близько 2, 5 петабайтів даних.
- Швидкість: швидкість означає швидкість, з якою дані рухаються, як користувачі Facebook надсилають в середньому 31, 25 мільйона повідомлень і щодня щодня переглядають 2, 77 мільйона відео щохвилини через Інтернет.
- Різноманітність: різноманітність стосується різних форматів даних, які створюються як структуровані, напівструктуровані та неструктуровані дані. Як і надсилання електронних листів із вкладенням у Gmail - це неструктуровані дані, а публікація будь-яких коментарів із деякими зовнішніми посиланнями також називається неструктурованими даними. Обмін зображеннями, аудіокліпами, відеокліпами - це неструктурована форма даних.
Зберігання та обробка цього величезного обсягу, швидкості та різноманітності даних є великою проблемою. Нам потрібно думати про інші технології, крім RDBMS для Big Data. Це тому, що RDBMS здатний зберігати та обробляти лише структуровані дані. Тож тут на допомогу приходить Apache Hadoop.
Представляємо термін Apache Hadoop
Apache Hadoop - це програмне забезпечення з відкритим кодом для зберігання даних та запуску програм на кластерах товарного обладнання. Apache Hadoop - це програмне забезпечення, яке дозволяє розподіляти обробку великих наборів даних по кластерах комп'ютерів за допомогою простих моделей програмування. Він призначений для масштабування від одного сервера до тисяч машин, кожен з яких пропонує локальні обчислення та сховища. Apache Hadoop є основою для зберігання та обробки великих даних. Apache Hadoop здатний зберігати та обробляти всі формати даних, як-от структуровані, напівструктуровані та неструктуровані дані. Apache Hadoop є відкритим кодом та товарним обладнанням, що принесло революцію в ІТ-індустрію. Він легко доступний для всіх рівнів компаній. Їм не потрібно більше вкладати кошти для створення кластеру Hadoop та на різну інфраструктуру. Тож докладно розберемося в корисній різниці між Big Data та Apache Hadoop у цій публікації.
Рамки Apache Hadoop
Рамка Apache Hadoop ділиться на дві частини:
- Розподілена файлова система Hadoop (HDFS): Цей шар відповідає за зберігання даних.
- MapReduce: Цей шар відповідає за обробку даних про кластер Hadoop.
Hadoop Framework поділяється на головну та рабовласницьку архітектуру. Шар імені розподіленої файлової системи Hadoop (HDFS) Node - це головний компонент, тоді як вузол даних - Slave компонент, тоді як у шарі MapReduce Job Tracker є головним компонентом, а трекер задач - slave компонентом. Нижче наводиться схема рамки Apache Hadoop.
Чому Apache Hadoop важливий?
- Можливість швидко зберігати та обробляти величезну кількість будь-якого типу даних
- Обчислювальна потужність: розподілена обчислювальна модель Hadoop швидко обробляє великі дані. Чим більше обчислювальних вузлів ви використовуєте, тим більше потужність обробки.
- Толерантність до помилок: обробка даних та додатків захищена від збою обладнання. Якщо вузол опускається, завдання автоматично переспрямовуються на інші вузли, щоб переконатися, що розподілені обчислення не виходять з ладу. Кілька копій усіх даних зберігаються автоматично.
- Гнучкість: Ви можете зберігати стільки даних, скільки хочете, і вирішувати, як їх використовувати пізніше. Це включає неструктуровані дані, такі як текст, зображення та відео.
- Низька вартість: рамка з відкритим кодом безкоштовна і використовує товарне обладнання для зберігання великої кількості даних.
- Масштабованість: Ви можете легко розробити свою систему для обробки більшої кількості даних, просто додавши вузли. Потрібно небагато адміністрації
Порівняння «голова до голови» між великими даними та Apache Hadoop (Інфографіка)
Нижче наведено найкращі 4 порівняння між великими даними та Apache Hadoop
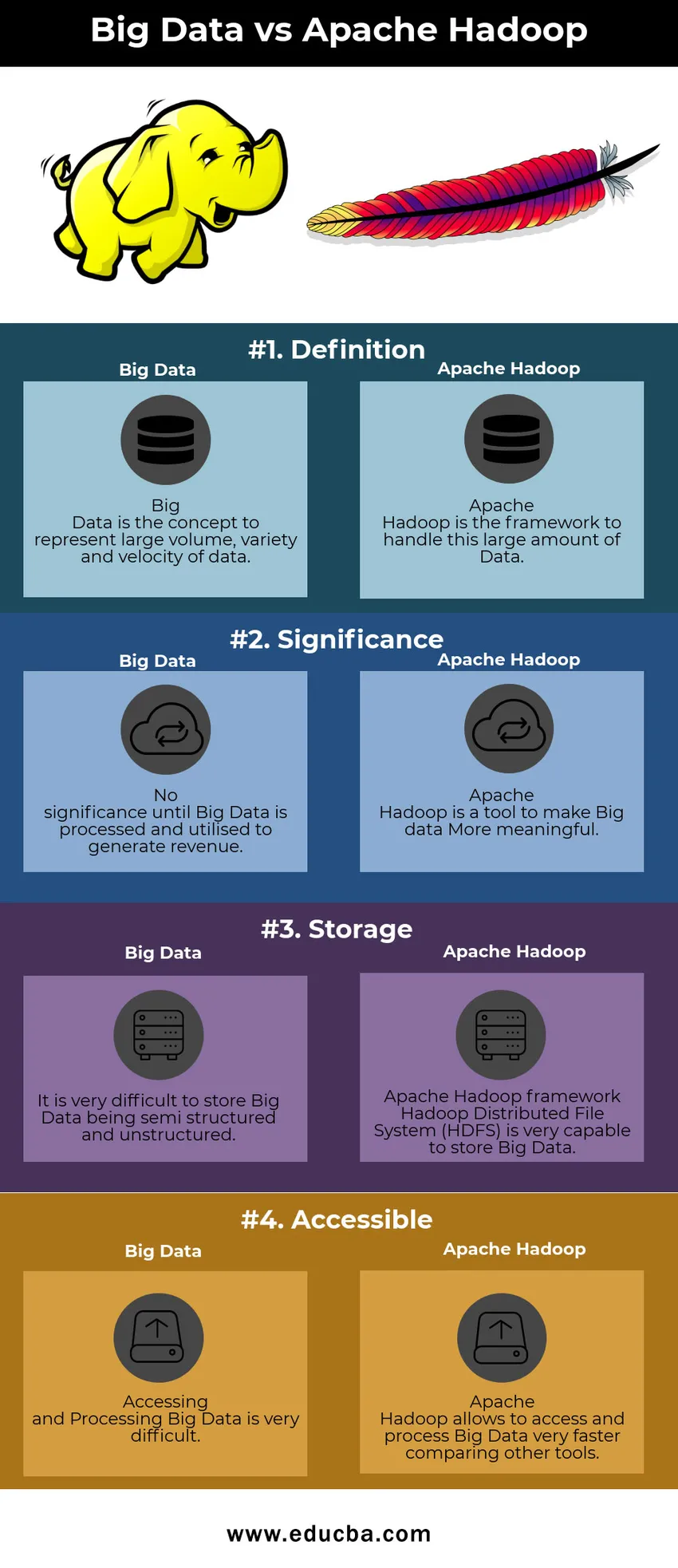
Таблиця порівняння великих даних проти Apache Hadoop
Я обговорюю основні артефакти та розрізняю великі дані проти Apache Hadoop
| Великі дані | Apache Hadoop | |
| Визначення | Big Data - це концепція, яка представляє великий об'єм, різноманітність та швидкість передачі даних | Apache Hadoop є основою для обробки цього великого обсягу даних |
| Значущість | Немає значення, поки великі дані не обробляються і не використовуються для отримання доходу | Apache Hadoop - це інструмент, щоб зробити великі дані більш значущими |
| Зберігання | Дуже важко зберігати Big Data як напівструктуровані та неструктуровані | Рамка Apache Hadoop з розподіленою файловою системою Hadoop (HDFS) дуже здатна зберігати великі дані |
| Доступний | Доступ та обробка великих даних дуже важкий | Apache Hadoop дозволяє отримати доступ та обробляти Big Data дуже швидко порівняно з іншими інструментами |
Висновок - Big Data vs Apache Hadoop
Ви не можете порівняти Big Data та Apache Hadoop. Це тому, що великі дані - це проблема, тоді як Apache Hadoop - це рішення. Оскільки кількість даних зростає експоненціально у всіх секторах, тому зберігати та обробляти дані з єдиної системи дуже важко. Тому для обробки цієї великої кількості даних нам потрібна розподілена обробка та зберігання даних. Тому Apache Hadoop вирішує зберігати та обробляти дуже велику кількість даних. Нарешті, я піду підсумок, що Big Data - це велика кількість складних даних, тоді як Apache Hadoop - це механізм зберігання та обробки великих даних дуже ефективно та безперебійно.
Рекомендована стаття
Це було керівництвом щодо Big Data vs Apache Hadoop, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ця стаття складається з усієї корисної різниці між Big Data та Apache Hadoop. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Big Data vs Science Data - чим вони відрізняються?
- Топ-5 великих тенденцій даних, які компаніям доведеться освоїти
- Hadoop vs Apache Spark - цікаві речі, які потрібно знати
- Apache Hadoop vs Apache Spark | Топ-10 порівнянь, які ти повинен знати!