
Вступ до файлів CS CSV
Файли CSV широко використовуються для зберігання інформації в табличному форматі, кожен рядок - запис даних. Для того, щоб читати, записувати чи маніпулювати даними на R, ми повинні мати в наявності деякі дані. Дані можна знайти в Інтернеті або їх можна зібрати з різних джерел, таких як опитування. За допомогою R можна читати, записувати та редагувати дані, що зберігаються у зовнішньому середовищі. R може читати та записувати дані з різних форматів, таких як XML, CSV та excel. У цій статті ми побачимо, як R можна використовувати для читання, запису та виконання різних операцій над файлами CSV.
Створення CSV-файлу в R
У цьому розділі ми побачимо, як кадр даних можна створити та експортувати у файл CSV у Р. По-перше, ми створимо кадр даних, який складається зі змінних службовців та відповідної зарплати.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
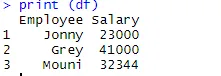
> print (df)
Після створення фрейму даних настав час використовувати функцію експорту R, щоб створити файл CSV в R. Для експорту кадру даних у CSV ми можемо використовувати наведений нижче код.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
У наведеному вище рядку коду ми надали каталог маршрутів для нашої слави даних та зберігаємо кадр даних у форматі CSV. У наведеному вище випадку файл CSV було збережено на моєму персональному робочому столі. Цей конкретний файл буде використаний у нашому підручнику для виконання декількох операцій.
Читання файлів CSV в R
Під час виконання аналітики за допомогою R, у багатьох випадках нам потрібно прочитати дані з файлу CSV. R дуже надійний під час читання файлів CSV. У наведеному вище прикладі ми створили файл, який ми будемо використовувати для читання за допомогою команди read.csv. Нижче наводиться приклад зробити це в Р.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Наведена вище команда читає файл Employee.csv, який доступний на робочому столі, і відображає його в R studio. Команда заголовка означає, що заголовок доступний для набору даних, а команда sep означає, що дані розділені комами.
Запишіть файли CSV в R
Запис у файл CSV - це одна з найкорисніших функцій, доступна в R для аналітика даних. Це можна використовувати для запису відредагованого файлу CSV у новий файл CSV для аналізу даних. Команда Write.csv використовується для запису файлу в CSV.
У наведеному нижче коді df у кадрі даних, в якому доступні наші дані, додаток використовується, щоб вказати, що новий файл створюється замість додавання чи перезапису у старому файлі. Додавання помилкових припускає створення нового файлу CSV. Sep представляє поле, розділене комою.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV-операції
Операції CSV необхідні для перевірки даних після їх завантаження в систему. R має кілька вбудованих функцій для перевірки та перевірки даних. Ці операції надають повну інформацію щодо набору даних.
Однією з найбільш часто використовуваних команд є підсумок.
> summary(df)
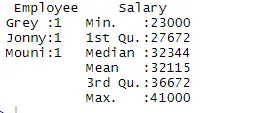
Команда підсумків надає нам статистику, орієнтовану на колонки. Числова змінна описується статистичним способом, який включає статистичні результати, такі як середнє значення, min, медіана та max. У наведеному вище прикладі дві змінні, що є «Співробітник» та «Заробітна плата», відокремлюються, і нам показана статистика для числової змінної, яка є Заробітною платою.
Команда View () використовується для відкриття набору даних на іншій вкладці та перевірки її вручну.
> View(df)

Функція Str надасть користувачам більш детальну інформацію про стовпчик набору даних. У наведеному нижче прикладі ми бачимо, що змінна Employee має Фактор як тип даних, а змінна Заробітна плата має int (integer) як тип даних.
> str(df)

У багатьох випадках нам потрібно буде побачити загальну кількість рядків, доступних у випадку великого набору даних, для якого ми можемо використовувати команду nrow (). Дивіться приклад нижче.
> # to show the total number of rows in the dataset
> nrow(df)

Аналогічним чином для відображення загальної кількості стовпців ми можемо використовувати команду ncol ()
> ncol(df)

R дозволяє відобразити потрібну кількість рядків за допомогою команди нижче. Коли їх n кількість рядків доступні в наборі даних, ми можемо вказати діапазон рядків, що відображаються.
> # to display first 2 rows of the data
> df(1:2, )

Операція даних виконується на великому наборі даних. Для ілюстрації я завантажив з Інтернету набір даних з відкритим кодом NI поштового індексу.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
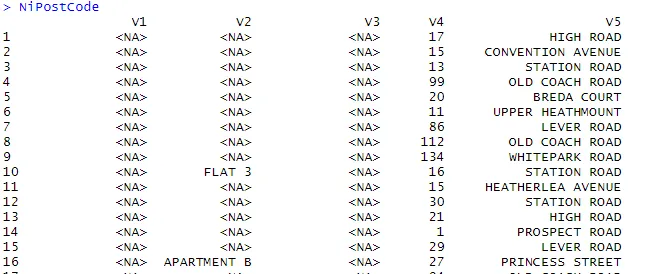
У вищенаведеному наборі даних ми бачимо, що імена заголовків відсутні, і є багато нульових значень. Набір даних потрібно очистити, щоб бути готовим до аналізу. На наступному кроці заголовки будуть відповідно назвами.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Тепер давайте підрахуємо кількість відсутніх значень у кадрі даних, а потім видалимо їх відповідно.
> # count of all missing values
> table(is.na (NiPostCode))

З наведеної вище команди ми бачимо, що загальна кількість пробілів або NA у фреймі даних близька до 5445148. Видалення всіх нульових значень призведе до втрати величезної кількості даних, тому розумно видаляти стовпці, де більше половини 50% даних відсутні.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Висновок
У цьому підручнику ми бачили, як файли CSV можна створювати, читати та додавати за допомогою операцій у Р. Ми дізналися, як створити новий набір даних у R, а потім імпортувати його у формат CSV. Далі ми побачили кілька операцій, таких як перейменування заголовка та підрахунок кількості рядків та стовпців.
Рекомендовані статті
Це посібник з файлів R CSV. Тут ми обговорюємо створення, читання та запис файлу CSV в R за допомогою CSV Operations. Ви також можете переглянути наступну статтю, щоб дізнатися більше -
- JSON - CSV
- Процес обміну даними
- Кар'єра в аналітиці даних
- Excel проти CSV