

Вступ до іскрових команд
Apache Spark - це основа, побудована на вершині Hadoop для швидких обчислень. Він розширює концепцію MapReduce в сценарії, заснованому на кластері, для ефективного виконання завдання. Іскрова команда написана на Scala.
Hadoop може бути використаний Spark такими способами (див. Нижче):
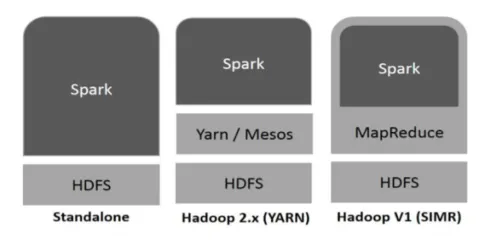
Фіг.1
https://www.tutorialspoint.com/
- Автономне: Іскра прямо розгорнута на вершині Hadoop. Іскрові завдання працюють паралельно на Hadoop та Spark.
- Hadoop Пряжа: Іскра працює на пряжі без необхідності попередньої установки.
- Іскра в MapReduce (SIMR): Іскра в MapReduce використовується для запуску іскрових завдань, крім самостійного розгортання. За допомогою SIMR можна запустити Spark і використовувати її оболонку без адміністративного доступу.
Компоненти іскри:
- Apache Spark Core
- Іскровий SQL
- Іскрова стрічка
- MLib
- GraphX
Еластичні розподілені набори даних (RDD) розглядаються як основна структура даних команд Spark. RDD має незмінний характер і є лише для читання. Всі види обчислень в іскрових командах здійснюються за допомогою перетворень та дій на RDD.
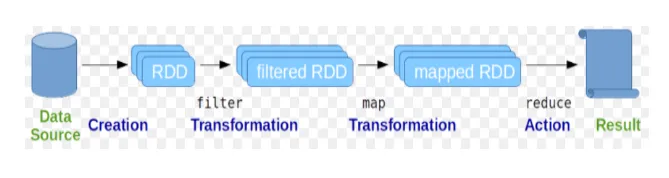
Фіг.2
Зображення Google
Іскрова оболонка забезпечує середовище для взаємодії користувачів з її функціональними можливостями. Команди іскри мають багато різних команд, які можна використовувати для обробки даних на інтерактивній оболонці.
Основні іскрові команди
Давайте розглянемо деякі основні команди Spark, які наведені нижче: -
-
Щоб запустити оболонку Іскри:

Фіг.3
-
Читання файлу з локальної системи:

Тут "sc" - це іскровий контекст. Зважаючи на те, що "data.txt" знаходиться в домашньому каталозі, він читається так, ще потрібно вказати повний шлях.
-
Створіть RDD шляхом паралелізації

NewData зараз RDD.
-
Підрахунок елементів у RDD

-
Збирати
Ця функція повертає весь вміст RDD програмі драйвера. Це корисно для налагодження на різних етапах програми написання.
-
Прочитайте перші 3 пункти з RDD

-
Збережіть вихідні / оброблені дані у текстовий файл

Тут папка "вихід" - це поточний шлях.
Проміжні іскрові команди
1. Фільтр на RDD
Давайте створимо новий RDD для елементів, що містять "так".

Фільтр трансформації потрібно викликати в існуючому RDD для фільтрації на слові "так", що створить новий RDD з новим списком елементів.
2. Робота ланцюга

Тут перетворення фільтрів і підрахунок дії діяли разом. Це називається ланцюговою операцією.
3. Прочитайте перший пункт із RDD

4. Порахуйте розділи RDD
Як ми знаємо, RDD складається з декількох розділів, виникає необхідність рахувати "no". перегородок. Оскільки це допомагає в налаштуванні та усуненні несправностей під час роботи з командами Spark.

За замовчуванням мінімум немає. pf розділ 2.
5. приєднатися
Ця функція поєднує дві таблиці (елемент таблиці - парний спосіб) на основі загального ключа. У парному RDD перший елемент - це ключ, а другий - значення.
6. Кешуйте файл
Кешування - це техніка оптимізації. Кешування RDD означає, що RDD залишиться в пам'яті, і всі майбутні обчислення будуть виконані на цих RDD в пам'яті. Це економить час читання диска та покращує продуктивність. Словом, це скорочує час доступу до даних.

Однак дані не будуть кешовані, якщо ви працюєте над функцією. Це можна довести, відвідавши веб-сторінку:
http: // localhost: 4040 / зберігання
RDD буде кешовано, як тільки дія буде виконана. Наприклад:

Ще одна функція, яка працює аналогічно кешу (), є persist (). Персист надає користувачам можливість аргументувати дані, які можуть допомогти кешувати дані в пам'яті, диску або в неробочій пам'яті. Персистувати без жодних аргументів працює так само, як кеш ().
Розширені команди для іскрення
Давайте розглянемо деякі вдосконалені команди Spark, які наведені нижче: -
-
Трансляція змінної
Змінна широкомовної передачі допомагає програмісту читати єдину змінну, кешовану на кожній машині кластера, а не доставку копії цієї змінної із завданнями. Це допомагає зменшити витрати на комунікацію.
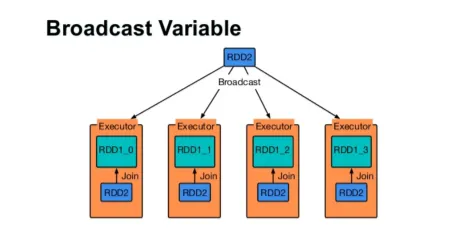
Фіг.4
Google Image
Коротше кажучи, є три основні риси змінної трансляції:
- Незмінний
- Вписується в пам'ять
- Поширений по кластері
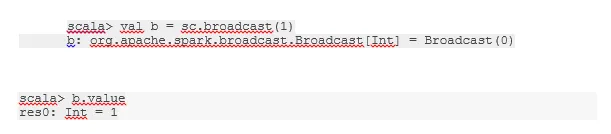
-
Акумулятори
Акумулятори - це змінні, які додаються до пов'язаних операцій. Існує багато застосувань для акумуляторів, таких як лічильники, суми тощо.

Ім'я акумулятора в коді також можна побачити в інтерфейсі Spark.
-
Карта
Функція карти допомагає в ітерації кожного рядка в RDD. Функція, яка використовується на карті, застосовується до кожного елемента RDD.
Наприклад, в RDD (1, 2, 3, 4, 6), якщо застосувати "rdd.map (x => x + 2)", ми отримаємо результат у вигляді (3, 4, 5, 6, 8).
-
Плоска карта
Flatmap працює аналогічно карті, але карта повертає лише один елемент, тоді як flatmap може повернути список елементів. Отже, для розділення речень на слова знадобиться рівна карта.
-
Злиття
Ця функція допомагає уникнути переміщення даних. Це застосовується в існуючому розділі, щоб менше даних переміщувалося. Таким чином, ми можемо обмежити використання вузлів у кластері.
Поради та рекомендації щодо використання іскрових команд
Нижче наведено різні поради та рекомендації команд Spark: -
- Новачки Spark можуть використовувати Spark-shell. Оскільки команди Spark побудовані на Scala, то, безумовно, чудово використовувати шкаралупу іскри. Однак іскрова оболонка python також доступна, так що навіть те, що можна використати, добре розбирається з python.
- Іскрова оболонка має багато варіантів управління ресурсами кластера. Нижче команда може допомогти вам у цьому:

- У Spark робота з довгими наборами даних - звичайна річ. Але все піде не так, коли поганий внесок прийнятий. Завжди корисно опустити погані рядки, використовуючи функцію фільтра Spark. Хороший набір входу буде чудовим кроком.
- Spark вибирає хороший розділ для власних даних. Але завжди корисно стежити за перегородками, перш ніж розпочати роботу. Випробування різних розділів допоможе вам паралелізму вашої роботи.
Висновок - Іскрові команди:
Команда Spark - це революційний та універсальний механізм великих даних, який може працювати для пакетної обробки, обробки в режимі реального часу, кешування даних тощо. Spark має багатий набір бібліотек машинного навчання, який може давати можливість науковцям даних та аналітичним організаціям створювати потужні, інтерактивні та швидкі програми.
Рекомендовані статті
Це було керівництвом команд Spark. Тут ми обговорили основні, а також вдосконалені команди Spark та деякі безпосередні команди Spark. Ви також можете переглянути наступну статтю, щоб дізнатися більше -
- Команди Adobe Photoshop
- Важливі команди VBA
- Команди Табау
- Чит аркуш SQL (Команди, безкоштовні поради та підказки)
- Типи приєднань до Spark SQL (приклади)
- Іскрові компоненти | Огляд та основні 6 компонентів