

Різниця між Hadoop і вуликом
Hadoop:
Hadoop - це структура або програмне забезпечення, яке було винайдено для управління величезними даними або великими даними. Hadoop використовується для зберігання та обробки великих даних, розподілених по кластеру товарних серверів.
Hadoop зберігає дані за допомогою розподіленої файлової системи Hadoop та обробляє / запитує їх за допомогою моделі програмування Map Reduce.
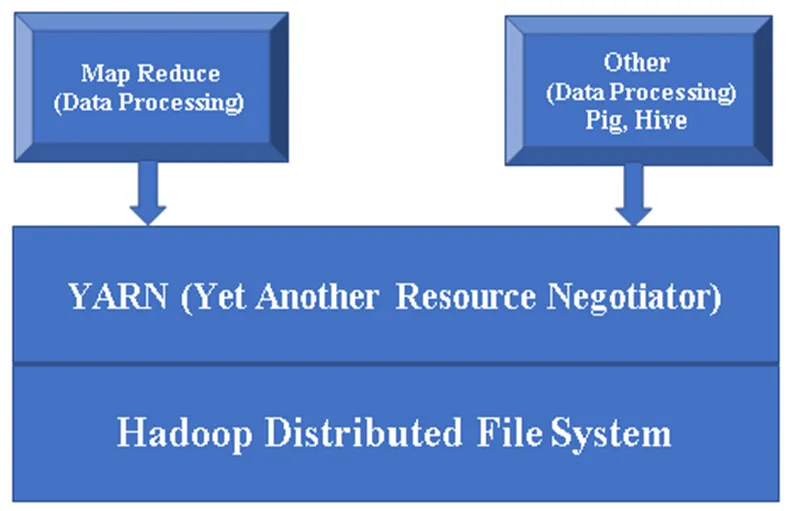
Малюнок 1, Основна архітектура компонента Hadoop.
Основні компоненти Hadoop:
Hadoop Base / Common: Hadoop common надасть вам одну платформу для встановлення всіх її компонентів.
HDFS (розподілена файлова система Hadoop): HDFS є основною частиною системи Hadoop, вона піклується про всі дані в кластері Hadoop. Він працює над Master / Slave Architecture і зберігає дані за допомогою реплікації.
Основна архітектура та копіювання:
- Головний вузол / вузол імені: Вузол імені зберігає метадані кожного блоку / файлу, що зберігаються у HDFS, HDFS може мати лише один головний вузол (у випадку HA інший головний вузол працюватиме як вторинний головний вузол).
- Підлеглий вузол / вузол даних: Вузли даних містять фактичні файли даних у блоках. HDFS може мати кілька вузлів даних.
- Реплікація: HDFS зберігає свої дані, поділяючи їх на блоки. За замовчуванням розмір блоку - 64 Мб. Завдяки реплікації дані зберігаються у 3 (коефіцієнт реплікації за замовчуванням може бути збільшений відповідно до потреби) різні вузли даних, отже, існує найменша можливість втрати даних у разі будь-якого збою вузла.
ПРАВА (ще один переговорник ресурсів): в основному використовується для управління ресурсами Hadoop, також він відіграє важливу роль у плануванні програми користувачів.
MR (Зменшення карти): Це основна модель програмування Hadoop. Він використовується для обробки / запиту даних у рамках Hadoop.
Вулик:
Hive - це програма, яка працює над Hadoop та надає інтерфейс SQL для обробки / запиту даних. Вулик розроблений та розроблений Facebook, перш ніж стати частиною проекту Apache-Hadoop.
Hive виконує свій запит за допомогою HQL (мова запитів Hive). Вулик має таку ж структуру, що і RDBMS, і майже однакові команди можуть використовуватися в вулику.
Hive може зберігати дані у зовнішніх таблицях, тому це не обов'язково для використовуваних HDFS, а також підтримує формати файлів, такі як ORC, файли Avro, файли послідовності та текстові файли тощо.
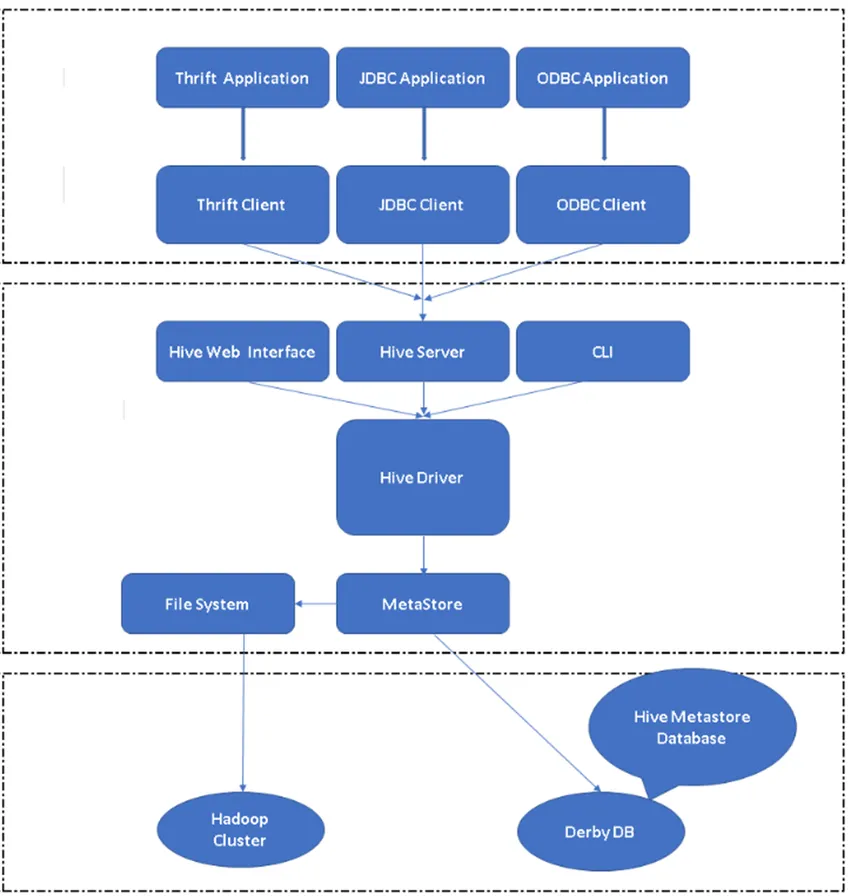
Малюнок 2, Архітектура вулика та його основні компоненти.
Основний компонент вулика:
Клієнти Hive: не тільки SQL, Hive також підтримує мови програмування, такі як Java, C, Python, використовуючи різні драйвери, такі як ODBC, JDBC та Thrift. Можна написати будь-яку програму клієнта вулика іншими мовами і може працювати в Hive за допомогою цих клієнтів.
Послуги вулика: У службі вулика відбувається виконання команд та запитів. Веб-інтерфейс вулика має п'ять підкомпонентів.
- CLI: Інтерфейс командного рядка за замовчуванням, наданий Hive для виконання запитів / команд Hive.
- Веб-інтерфейси вулика: Це простий графічний інтерфейс користувача. Це альтернатива командному рядку Hive і використовується для запуску запитів і команд у додатку Hive.
- Сервер вуликів: Його також називають Apache Thrift. Він несе відповідальність за отримання команд з різних інтерфейсів командного рядка та подання всіх команд / запитів у Hive, також він отримує кінцевий результат.
- Драйвер Apache Hive: Він несе відповідальність за отримання вхідних даних із інтерфейсів CLI, веб-інтерфейсу, ODBC, JDBC або Thrift клієнтом та передає інформацію в мета-магазин, де зберігається вся інформація про файл.
- Metastore: Metastore - це сховище для зберігання всієї інформації метаданих Hive. Метадані Hive зберігають таку інформацію, як структура таблиць, розділів та тип стовпців тощо …
Зберігання вулика: це місце, де виконується фактичне завдання. Усі запити, які виконуються з вулика, виконували дію всередині сховища Hive.
Порівняння між головами та Hiveop (Інфографіка)
Нижче наведено 8 найкращих різниць між Hadoop проти Hive
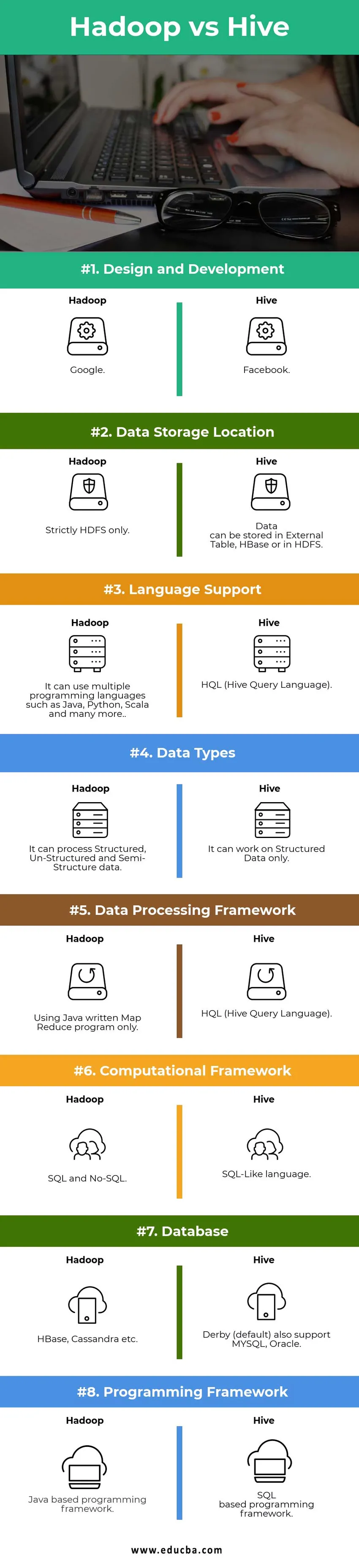
Основні відмінності між Hadoop і Hive:
Нижче наведено списки пунктів, опишіть про ключові відмінності між Hadoop та Hive:
1) Hadoop - це основа для обробки / запиту великих даних, тоді як Hive - це інструмент на основі SQL, який створює Hadoop для обробки даних.
2) Обробляйте / запитуйте всі дані за допомогою HQL (мова запиту вуликів), це мова схожа на SQL, тоді як Hadoop може зрозуміти лише зменшення карт.
3) Зменшення карти - невід'ємна частина Hadoop, запит Hive спочатку перетворюється на зменшення карт, ніж обробляє Hadoop для запиту даних.
4) Hive працює на SQL Like query, в той час як Hadoop розуміє його, використовуючи лише Java-базування на основі зменшення карт.
5) У Hive, раніше використовувані традиційні команди "Реляційна база даних" також можна використовувати для запиту великих даних, перебуваючи в Hadoop, повинні писати складні програми зменшення карт за допомогою Java, що не схоже на традиційну Java.
6) Вулик може обробляти / запитувати структуровані дані, тоді як Hadoop призначений для всіх типів даних, будь то структуровані, неструктуровані або напівструктуровані.
7) Використовуючи Hive, можна обробляти / запитувати дані без складного програмування, перебуваючи в екосистемі Simple Hadoop, потрібно записати складну програму Java для тих же даних.
8) Для однієї сторони фреймворків Hadoop потрібна лінія 100s для підготовки MR-програми на базі Java, інша Hadoop з Hive може запитувати ті самі дані, використовуючи 8-10 рядків HQL.
9) У вулику дуже важко вставити вихід одного запиту як введення іншого, тоді як той самий запит можна легко виконати за допомогою Hadoop з MR.
10) Не обов'язково мати Metastore в кластері Hadoop, поки Hadoop зберігає всі свої метадані всередині HDFS (розподіленої файлової системи Hadoop).
Таблиця порівняння Hadoop проти вуликів
| Бали порівняння | Вулик | Hadoop |
|
Дизайн та розробка | ||
| Місце зберігання даних |
Дані можна зберігати у Зовнішньому Таблиця, HBase або HDFS. | Суворо лише HDFS. |
| Мовна підтримка | HQL (мова запиту вуликів) |
Він може використовувати кілька мов програмування, таких як Java, Python, Scala та багато інших. |
| Типи даних | Він може працювати лише на структурованих даних. |
Він може обробляти структуровані, неструктуровані та напівструктурні дані. |
| Рамка обробки даних |
HQL (мова запиту вуликів) | Використання лише програми, написаної на Java, для зменшення карт. |
|
Обчислювальна рамка | Мова, схожа на SQL | SQL і No-SQL. |
| База даних |
Дербі (за замовчуванням) також підтримує MYSQL, Oracle… | HBase, Cassandra тощо…. |
| Програма програмування |
Основа програмування на основі SQL. | На базі програми Java програмування. |
Висновок - Хадоп проти вулика
Hadoop і Hive використовуються для обробки великих даних. Hadoop - це структура, яка забезпечує платформу для інших додатків для запиту / обробки великих даних, тоді як Hive - це лише програма, заснована на SQL, яка обробляє дані за допомогою HQL (мова запитів Hive)
Hadoop можна використовувати без вулика для обробки великих даних, тоді як використовувати Hive без Hadoop непросто.
Як висновок, ми не можемо порівнювати Hadoop і Hive так чи інакше і в будь-якому аспекті. І Hadoop, і Hive абсолютно різні. Використання обох технологій разом може зробити процес запиту Big Data набагато простішим та зручнішим для користувачів Big Data.
Рекомендовані статті:
Це було керівництвом щодо Hadoop vs Hive, їх значення, порівняння «голова до голови», ключових відмінностей, таблиці порівняння та висновку. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Hadoop vs Apache Spark - цікаві речі, які потрібно знати
- HADOOP vs RDBMS | Знай 12 корисних відмінностей
- Наскільки великі дані змінюють обличчя охорони здоров’я
- Топ-12 порівнянь Apache Hive - Apache HBase (Інфографіка)
- Дивовижний путівник по Hadoop vs Spark