

Різниця між Hadoop і HBase
Hadoop - це програма з відкритим кодом Java, що використовується для управління та обробки величезної кількості структурованих та неструктурованих даних. Hadoop масово масштабується, тому використовується для обробки великих навантажень даних. Великі дані зберігаються, отримуються доступ та обробляються на надійному та розширюваному кластері. HBase (Hadoop Database) - нереляційна та не тільки SQL, тобто NoSQL база даних, яка працює на вершині Hadoop як розподілений і масштабований склад великих даних. Це база даних із відкритим кодом, у якій дані зберігаються у вигляді рядків та стовпців, у цій комірці - перетин стовпців та рядків.
Нижче наведені основні компоненти архітектури Hadoop:
- Розподілена файлова система Hadoop (HDFS): Hadoop включає в себе розподілену систему зберігання, розподілену файлову систему Hadoop (HDFS). HDFS - це архітектура головного підлеглого, яка зберігає дані в кластері. Дані, що поширюються на декілька ведених вузлів головним вузлом у блоці форм. Головний вузол називається Namenode, а ведені вузли називаються Datanode. HDFS легко розширюється і зберігає величезну кількість даних про Datanodes. HDFS має настроюваний коефіцієнт реплікації із значенням за замовчуванням 3, який можна редагувати.
- MapReduce: MapReduce - парадигма програмування, паралельно обробляє величезну кількість наборів даних по мережі. MapReduce відноситься до двох різних завдань: відображення вхідних даних, в яких дані, розділені на підмножину даних, що називаються кортежами, і зменшення завдання, приймає ці кортежі з карти як вхідні та поєднує для формування виводу оригіналу.
- Пряжа: YARN означає ще один навігатор ресурсів, який обчислює ресурси, такі як управління процесором та пам'яттю, планування запитів на ресурси.
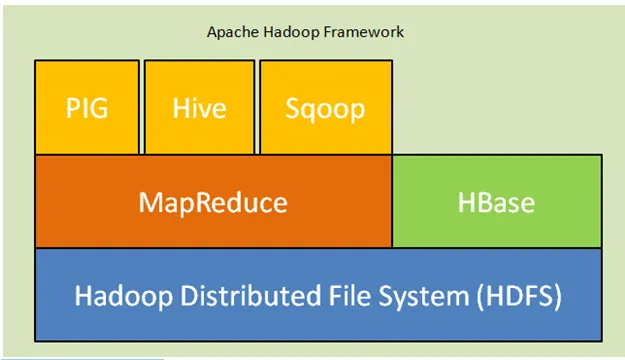
Рис. Рамка Apache Hadoop
Сервер регіону обслуговує дані для операцій читання / запису. Усі дані HBase зберігаються у файлі HDFS. HDFS Datanode зберігає дані, якими управляє регіональний сервер. HDFS Namenode зберігає інформацію метаданих для всіх фізичних блоків даних, що містять файли.
Версія для версії використовується для відстеження змін комірок, що відстежує версію вмісту. З цього його можна отримати будь-яку версію вмісту. Кожне значення комірки включає атрибут 'version' стосовно часової позначки для отримання комірки. Кожне значення на карті - це безперебійний масив байтів. Карта індексується ключем рядка, ключем стовпця та часовою позначкою. Архітектура HBase має масштабовані, розріджені, розподілені, стійкі та багатовимірні сортування карт.
Порівняння між головами та Hadoop проти HBase (Інфографіка)
Нижче наведено найкращі 7 відмінностей між Hadoop проти HBase
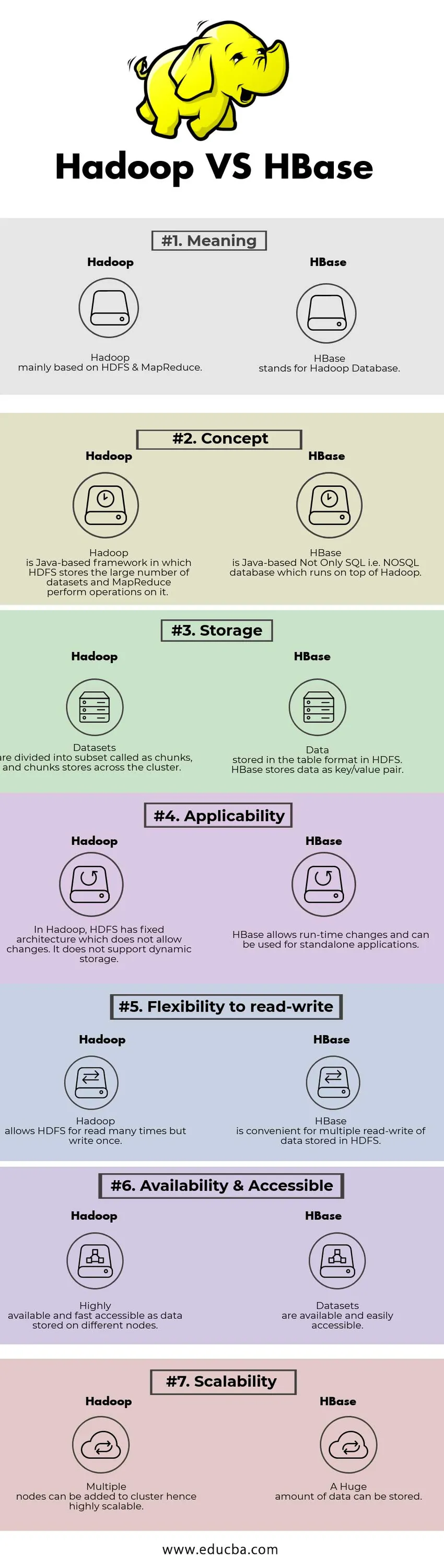
Ключові відмінності між Hadoop і HBase
Різниця між Hadoop і HBase пояснюється в пунктах, представлених нижче:
- Hadoop не підходить для он-лайн аналітичної обробки (OLAP), і HBase є частиною екосистеми Hadoop, яка забезпечує випадковий доступ у реальному часі (читання / запис) до даних у файловій системі Hadoop.
- Рамка Hadoop є стійкою до відмов конструкцією і підтримує швидку передачу даних між вузлами навіть під час відмов системи. HBase - це нереляційна та відкрита база даних не лише для SQL, що працює на вершині Hadoop. HBase підпадає під тип теореми CAP (узгодженість, доступність та толерантність розділів).
- Hadoop найбільш підходить для проведення пакетної аналітики. Однак одним з найбільших його недоліків є нездатність здійснювати аналіз у режимі реального часу - тенденція, що потребує ІТ-індустрії. HBase, з іншого боку, може обробляти великі набори даних і не підходить для пакетної аналітики. Натомість використовується для запису / читання даних з Hadoop в режимі реального часу.
- І Hadoop, і HBase здатні обробляти структуровані, напівструктуровані, а також неструктуровані дані. У Hadoop HDFS не вистачає механізму обробки пам'яті, який уповільнює процес аналізу даних; як це використовується звичайний старий MapReduce для цього. HBase, навпаки, може похвалитися процесором обробки пам'яті, який різко збільшує швидкість читання / запису.
- Hadoop дуже прозорий у виконанні аналізу даних. HBase, з іншого боку, будучи базою даних NoSQL у табличному форматі, отримує значення, сортуючи їх за різними ключовими значеннями.
Таблиця порівняння Hadoop проти HBase
| ОСНОВА для порівняння | Hadoop | HBase |
| Значення | Hadoop в основному базується на HDFS та MapReduce. | HBase означає Базу даних Hadoop. |
| Концепція | Hadoop - це база на Java, в якій HDFS зберігає велику кількість наборів даних, а MapReduce виконує операції над нею. | HBase - це базована на Java не тільки SQL, тобто база даних NoSQL, яка працює на вершині Hadoop. |
| Зберігання | Набори даних поділяються на підмножини, які називаються фрагментами, і блоки зберігання в кластері. | Дані, що зберігаються у форматі таблиці у форматі HDFS. HBase зберігає дані як пара ключів / значень. |
| Застосовуваність | У Hadoop HDFS має виправлену архітектуру, яка не дозволяє змінювати. Він не підтримує динамічне зберігання. | HBase дозволяє змінювати час роботи і може використовуватися для автономних програм. |
| Гнучкість читати-писати | Hadoop дозволяє HDFS читати багато разів, але писати один раз. | HBase зручна для багаторазового читання-запису даних, що зберігаються у HDFS |
| Доступність та доступність | Високодоступні та швидко доступні дані, що зберігаються на різних вузлах. | Набори даних доступні та легко доступні |
| Масштабованість | Кілька вузлів можуть бути додані до кластеру, отже, високо масштабований. | Величезна кількість даних може бути збережена. |
Висновок - Hadoop проти HBase
Архітектура Hadoop в основному базується на HDFS та MapReduce. HBase є підтримуючим компонентом у системі Hadoop. HBase здатний розмістити величезні таблиці та забезпечити швидкий випадковий доступ до наявних даних, тоді як HDFS підходить для зберігання великих файлів. І Hadoop, і HBase забезпечують швидкий доступ до даних, але при операціях зчитування / запису HBase можна виконувати, а для HDFS - читати багато разів, і один раз можна виконати запис. У цій статті описано розуміння Hadoop та HBase, коротко висвітлено особливості та розумно порівняно.
Рекомендована стаття
- Apache Hadoop vs Apache Spark | Топ-10 порівнянь, які ти повинен знати!
- Хадоп проти вулика - з’ясуйте найкращі відмінності
- HBase vs Cassandra - хто краще (інфографіка)
- Топ-12 порівнянь Apache Hive - Apache HBase (Інфографіка)
- Hadoop vs Spark: Які особливості