

Введення в методику наукових даних
У сучасному світі, де дані - це нове золото, є різні види аналізу для бізнесу. Результат проекту з наукових даних значно відрізняється від типу наявних даних, а отже, і вплив є змінним. Оскільки доступно багато різного роду аналізів, стає необхідним зрозуміти, для чого потрібно вибрати кілька базових методів. Основна мета методів наукових даних - це не тільки пошук відповідної інформації, а й виявлення слабких зв'язків, які, як правило, призводять до поганої роботи моделі.
Що таке наука даних?
Наука даних - це галузь, яка поширюється на кілька дисциплін. Він включає наукові методи, процеси, алгоритми та системи для збору знань і роботи над тим же. Це поле включає різноманітні жанри і є загальною платформою для уніфікації понять статистики, аналізу даних та машинного навчання. З цього приводу теоретичні знання статистики, а також дані в реальному часі та методики машинного навчання працюють рука об руку, щоб отримати плідні результати для бізнесу. Використовуючи різні методи, використовувані в науці даних, ми в сучасному світі можемо мати на увазі краще рішення, яке інакше може пропустити людське око та розум. Пам'ятайте, машина ніколи не забуває! Для отримання максимального прибутку в керованому даними світі магія Data Science є необхідним інструментом.
Різні типи методики наукових даних
У наступних кількох параграфах ми розглянемо загальні методи наукових даних, що використовуються в кожному іншому проекті. Хоча іноді методика вивчення даних може бути специфічною для бізнес-проблем і може не входити до наведених нижче категорій, цілком нормально називати їх різними типами. На високому рівні ми поділяємо методи на наглядові (ми знаємо цільовий вплив) та непідконтрольні (ми не знаємо про цільову змінну, яку намагаємось досягти). На наступному рівні методики можна розділити за термінами
- Вихід, який ми отримали б, або який є наміром бізнес-проблеми
- Тип використовуваних даних.
Давайте спочатку розглянемо сегрегацію на основі намірів.
1. Непідконтрольне навчання
- Виявлення аномалії
У цьому типі методики ми визначаємо будь-яке несподіване явище у всьому наборі даних. Оскільки поведінка відрізняється від фактичного трактування даних, основними припущеннями є:
- Заява цих випадків дуже мала.
- Різниця в поведінці значна.
Пояснюються алгоритми аномалії, наприклад, Isolation Forest, який забезпечує бал за кожен запис у наборі даних. Цей алгоритм є деревною моделлю. Використовуючи цей тип методів виявлення та його популярність, вони використовуються в різних ділових випадках, наприклад, перегляди веб-сторінок, показник скорочення, дохід за клік тощо. На графіку нижче ми можемо пояснити, як виглядає аномалія.
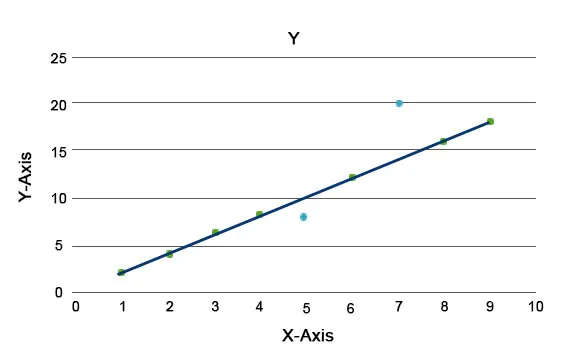
Тут блакитні кольори являють собою аномалію в наборі даних. Вони відрізняються від звичайної лінії тренду і мають менший характер.
- Аналіз кластеризації
Завдяки цьому аналізу головне завдання полягає в тому, щоб розділити весь набір даних по групах, щоб тенденція або ознаки в одній групі точок даних були досить схожими один на одного. У термінології науки про дані ми називаємо їх кластером. Наприклад, у роздрібному бізнесі існує план масштабування бізнесу, і стає необхідним знати, як поводитимуться нові клієнти в новому регіоні, грунтуючись на минулих даних, які ми маємо. Неможливо розробити стратегію для кожної людини в популяції, але корисно буде згрупувати населення в кластери, щоб ця стратегія була ефективною в групі та була масштабованою.
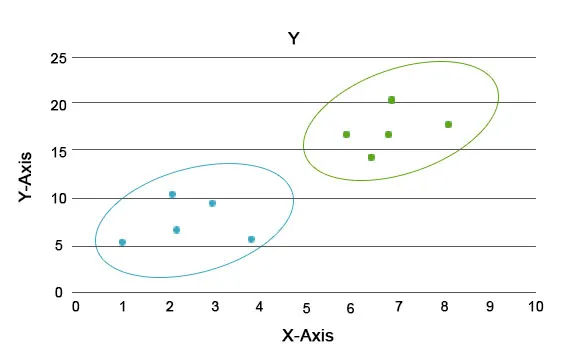
Тут синій і помаранчевий кольори - це різні скупчення, що мають унікальні риси всередині себе.
- Аналіз асоціацій
Цей аналіз допомагає нам вибудовувати цікаві відносини між елементами в наборі даних. Цей аналіз розкриває приховані зв’язки та допомагає представляти елементи набору даних у вигляді правил асоціації або наборів частих елементів. Правило асоціації розбивається на 2 етапи:
- Часте генерування наборів предметів : У цьому створюється набір, коли елементи, що часто зустрічаються, встановлюються разом.
- Генерація правил: Набір, побудований вище, передається через різні шари формування правил, щоб створити приховані відносини між собою. Наприклад, набір може потрапляти як в концептуальні, так і в реалізаційні питання або проблеми із застосуванням. Потім вони розгалужуються у відповідних деревах для побудови правил асоціації.
Наприклад, APRIORI - алгоритм побудови правил асоціації.
2. Контрольоване навчання
- Регресійний аналіз
При регресійному аналізі ми визначаємо залежну / цільову змінну та решту змінних як незалежні змінні та врешті-решт гіпотезуємо, як одна / більше незалежних змінних впливають на цільову змінну. Регресія з однією незалежною змінною називається одноваріантною і з більш ніж однією відомою як багатоваріантна. Давайте розберемося, використовуючи одновимірний, а потім масштабний для багатоваріантного.
Наприклад, y - цільова змінна, а x 1 - незалежна змінна. Отже, з пізнання прямої можемо записати рівняння як y = mx 1 + c. Тут “m” визначає, наскільки сильно y впливає x 1 . Якщо "m" дуже близький до нуля, це означає, що зі зміною x 1 y не впливає сильно. З числом, більшим за 1, вплив посилюється, і невелика зміна х 1 призводить до великих змін у. Подібно до одновимірної, у багатоваріантній можна записати як y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Тут вплив кожної незалежної змінної визначається відповідним їй “m”.
- Класифікаційний аналіз
Аналогічно аналізу кластеризації, побудовані алгоритми класифікації, що мають цільову змінну у вигляді класів. Різниця між кластеризацією та класифікацією полягає в тому, що при кластеризації ми не знаємо, до якої групи потрапляють точки даних, тоді як в класифікації ми знаємо, до якої групи вона належить. І це відрізняється від регресії з точки зору того, що кількість груп має бути фіксованим числом на відміну від регресії, воно є безперервним. Існує купа алгоритмів класифікаційного аналізу, наприклад, Підтримка векторних машин, Логістична регресія, Дерева рішень тощо.
Висновок
На закінчення ми розуміємо, що кожен тип аналізу сам по собі величезний, але тут ми можемо надати невеликий аромат різним методикам. У наступних кількох записках ми б взяли кожну з них окремо і детально розглянемо різні підтемі, що застосовуються в кожному з батьківських методів.
Рекомендована стаття
Це посібник з методик використання даних. Тут ми обговорюємо впровадження та різні види методик в науці даних. Ви також можете ознайомитися з іншими запропонованими нами статтями, щоб дізнатися більше -
- Інструменти наукових даних | Топ-12 інструментів
- Алгоритми наукових даних з типами
- Вступ до кар'єри наукових даних
- Data Science vs Візуалізація даних
- Приклади багатоваріантної регресії
- Створіть дерево рішень з перевагами
- Короткий огляд життєвого циклу Data Science