
Вступ до ансамблевих методик
Ансамблеве навчання - це техніка машинного навчання, яка за допомогою декількох базових моделей і поєднує їх результати для створення оптимізованої моделі. Цей тип алгоритму машинного навчання допомагає покращити загальну продуктивність моделі. Тут базовою моделлю, яка найчастіше використовується, є класифікатор дерева рішень. Дерево рішень в основному працює на декількох правилах і забезпечує прогнозований результат, де правила - це вузли, а їхні рішення будуть їхніми дітьми, а вузли листя - це остаточне рішення. Як показано в прикладі дерева рішень.
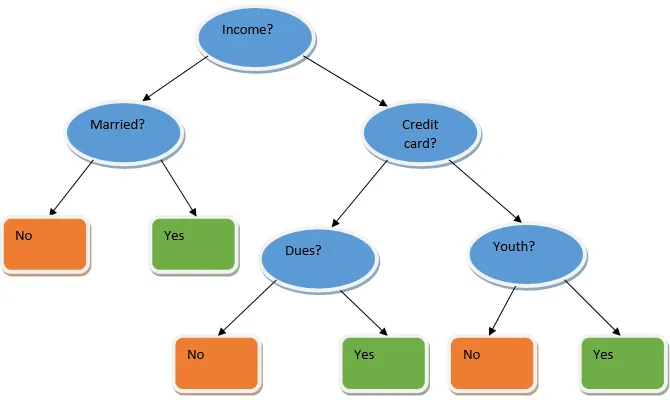
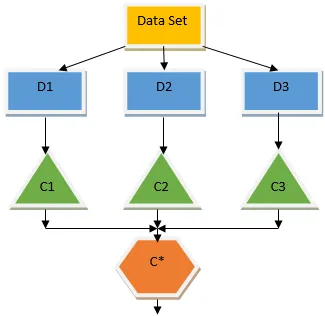
Вищезазначене дерево рішень в основному говорить про те, чи можна людині / замовнику отримати позику чи ні. Одне з правил прийнятності кредиту так - це те, що якщо (дохід = Так && одружений = Ні), тоді Позика = Так, так працює класифікатор дерева рішень. Ми будемо включати ці класифікатори як множинні базові моделі та комбінувати їх вихід для створення однієї оптимальної прогнозної моделі. На малюнку 1.b показана загальна картина алгоритму навчання ансамблю.
Види методик ансамблів
Різні типи ансамблів, але наша основна увага буде зосереджена на наступних двох типах:
- Баггінг
- Підвищення
Ці методи допомагають зменшити дисперсію та упередженість у моделі машинного навчання. Тепер спробуємо зрозуміти, що таке упередженість та дисперсія. Зміщення - це помилка, яка виникає через неправильні припущення в нашому алгоритмі; високий ухил вказує на те, що наша модель є надто простою / недостатньою. Варіантність - похибка, яка виникає внаслідок чутливості моделі до дуже малих коливань у наборі даних; велика дисперсія вказує на те, що наша модель дуже складна / надмірна. Ідеальна модель ML повинна мати належний баланс між ухилом та дисперсією.
Агрегація / завантаження у завантажувальну систему
Баггінг - це ансамблева техніка, яка допомагає зменшити дисперсію в нашій моделі і, отже, уникає переобладнання. Баггінг - приклад алгоритму паралельного навчання. Баггінг працює на двох принципах.
- Завантаження даних: з оригінального набору даних розглядаються різні вибіркові сукупності із заміною.
- Агрегування: усереднення результатів усіх класифікаторів та надання єдиного результату для цього використовує більшість голосів у разі класифікації та усереднення у випадку проблеми регресії. Один з найвідоміших алгоритмів машинного навчання, який використовує концепцію забою, - це випадковий ліс.
Випадковий ліс
У випадковому лісі з випадкової вибірки, вилученої з популяції з заміною, і підмножина ознак вибирається з набору всіх функцій, будується дерево рішень. З цих підмножини функцій, залежно від того, яка функція дає найкращий розкол, вибирається як корінь для дерева рішень. Підмножину функцій потрібно вибирати випадковим чином за будь-яку ціну, інакше ми в кінцевому підсумку виробляємо лише корельовані треси і дисперсія моделі не буде покращена.
Зараз ми побудували нашу модель із зразків, взятих у населення, питання полягає в тому, як ми перевіряємо модель? Оскільки ми розглядаємо зразки із заміною, отже, всі зразки не будуть розглянуті, а деякі з них не будуть включені до жодної сумки, вони називаються зразками мішків. Ми можемо підтвердити нашу модель за допомогою цих зразків OOB (з мішка). Важливими параметрами, які слід враховувати у випадковому лісі, є кількість зразків та кількість дерев. Розглянемо «m» як підмножину функцій, а «p» - це повний набір функцій, тепер, як правило, слід вибрати ідеально
- m as√і мінімальний розмір вузла як 1 для проблеми класифікації.
- m як P / 3 і мінімальний розмір вузла, який дорівнює 5, для проблеми з регресією.
M і p слід розглядати як параметри настройки, коли ми маємо справу з практичною проблемою. Навчання може бути припинено, коли помилка OOB стабілізується. Одним недоліком випадкового лісу є те, що коли у нашому наборі даних є 100 функцій і важливі лише пара особливостей, то цей алгоритм буде погано працювати.
Підвищення
Підвищення - це послідовний алгоритм навчання, який допомагає зменшити упередженість нашої моделі та відхилитись у деяких випадках контрольованого навчання. Це також допомагає перетворити слабких учнів на сильних учнів. Стимулювання працює за принципом послідовного розміщення слабких учнів, і це присвоює вагу кожній точці даних після кожного раунду; більша вага присвоюється помилково класифікованій точці даних у попередньому раунді. Цей послідовно зважений метод навчання нашого набору даних є ключовою відмінністю від методу розфасовки.
Фіг.33а показує загальний підхід у прискоренні
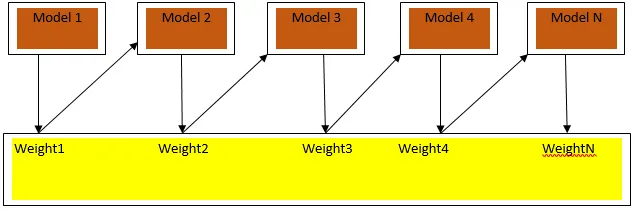
Остаточні прогнози поєднуються на основі голосування зваженої більшості у випадку класифікації та зваженої суми у разі регресу. Найпоширенішим алгоритмом прискорення є адаптивне прискорення (Adaboost).
Адаптивне підвищення
Етапи алгоритму Adaboost такі:
- Для заданих n точок даних ми визначаємо цільовий клас та ініціалізуємо всі ваги до 1 / n.
- Ми підключаємо класифікатори до набору даних і вибираємо класифікацію з найменш зваженою помилкою класифікації
- Ми присвоюємо ваги класифікатору правилом великого пальця на основі точності, якщо точність перевищує 50%, то вага позитивна і навпаки.
- Ми оновлюємо ваги класифікаторів наприкінці ітерації; ми оновлюємо більше ваги для помилково класифікованої точки, щоб у наступній ітерації ми її класифікували правильно.
- Після всієї ітерації ми отримуємо остаточний результат прогнозування, виходячи із середнього голосування / середньозваженого.
Адабустінг ефективно працює із слабкими (менш складними) учнями та з високими класифікаторами упередженості. Основні переваги Adaboosting полягають у тому, що він швидкий, немає параметрів настройки, подібних до випадків розробки мішків, і ми не робимо жодних припущень щодо слабких учнів. Ця методика не дає точного результату, коли
- За нашими даними є більше людей, що переживають люди.
- Набір даних недостатній.
- Слабкі студенти дуже складні.
Вони також чутливі до шуму. Дерева рішень, які утворюються в результаті прискорення, матимуть обмежену глибину та високу точність.
Висновок
Ансамблеві методи навчання широко застосовуються для підвищення точності моделі; ми маємо вирішити, яку техніку використовувати на основі нашого набору даних. Але ці методи не є переважними в деяких випадках, коли інтерпретація має важливе значення, оскільки ми втрачаємо інтерпретацію ціною підвищення продуктивності. Вони мають величезне значення в галузі охорони здоров’я, де невелике поліпшення результатів діяльності є дуже цінним.
Рекомендовані статті
Це посібник з Ансамблевих технік. Тут ми обговорюємо вступ та два основні типи технік ансамблю. Ви також можете ознайомитись з іншими пов'язаними з нами статтями, щоб дізнатися більше -
- Технології стеганографії
- Методи машинного навчання
- Методи побудови команди
- Алгоритми наукових даних
- Найчастіше використовувані методи ансамблевого навчання