
Лінійна регресія в Excel (Зміст)
- Вступ до лінійної регресії в Excel
- Методи використання лінійної регресії в Excel
Вступ до лінійної регресії в Excel
Лінійна регресія - це статистична техніка / метод, що використовується для дослідження взаємозв'язку між двома безперервними кількісними змінними. У цій техніці незалежні змінні використовуються для прогнозування значення залежної змінної. Якщо є лише одна незалежна змінна, то це проста лінійна регресія, а якщо кількість незалежних змінних більше однієї, то це множинна лінійна регресія. Моделі лінійної регресії мають залежність між залежними та незалежними змінними, встановлюючи лінійне рівняння до спостережуваних даних. Лінійний стосується того, що ми використовуємо рядок, щоб відповідати нашим даним. Залежні змінні, що використовуються в регресійному аналізі, також називаються змінними відгуку або прогнозованими, а незалежні змінні також називаються пояснювальними змінними або предикторами.
Лінія лінійної регресії має рівняння виду: Y = a + bX;
Де:
- X - пояснювальна змінна,
- Y - залежна змінна,
- b - нахил лінії,
- a - y-перехоплення (тобто значення y, коли x = 0).
Метод найменших квадратів, як правило, використовується в лінійній регресії, яка обчислює найкращу лінію підходи для спостережуваних даних шляхом мінімізації суми квадратів відхилення точок даних від лінії.
Методи використання лінійної регресії в Excel
Цей приклад вчить вас методам виконання лінійного регресійного аналізу в Excel. Давайте розглянемо кілька методів.
Ви можете завантажити цей шаблон лінійної регресії Excel тут - шаблон лінійної регресії ExcelМетод №1 - Розсіяння діаграми з тенденцією
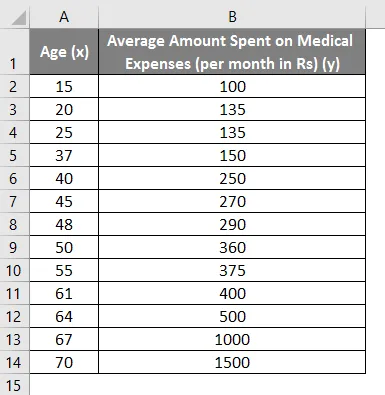
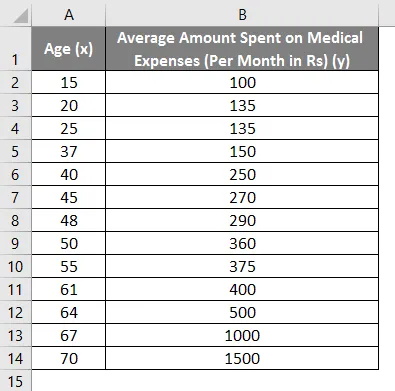
Скажімо, у нас є набір даних про деяких людей з їх віком, індексом масової маси (ІМТ) та сумою, витраченою на медичні витрати за місяць. Тепер, розуміючи такі особливості людей, як вік та ІМТ, ми хочемо знайти, як ці змінні впливають на медичні витрати, і, отже, використовувати їх для проведення регресії та оцінки / прогнозу середніх витрат на медичну допомогу для деяких конкретних людей. Давайте спочатку подивимось, як лише вік впливає на медичні витрати. Давайте подивимося набір даних:
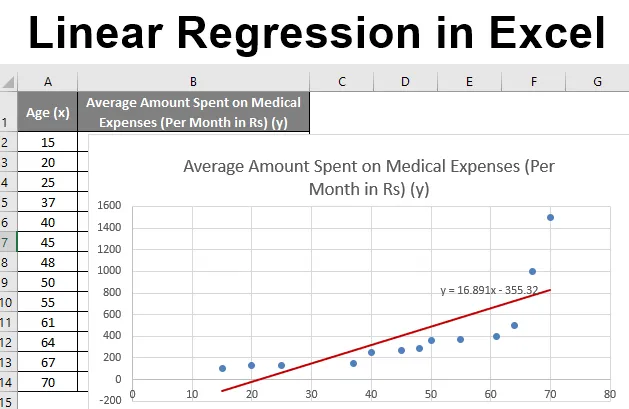
Сума на медичні витрати = b * вік + а
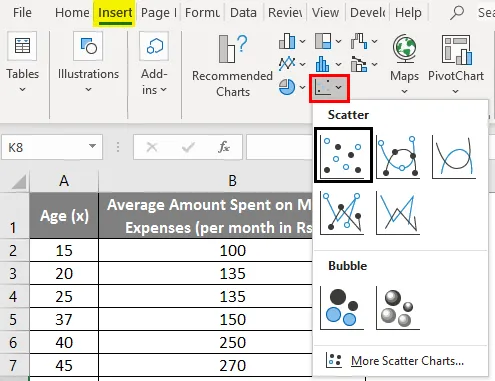
- Виберіть два стовпчики набору даних (x і y), включаючи заголовки.
- Клацніть «Вставити» та розгорніть спадне меню для «Діаграми розсіювання» та виберіть мініатюру «Розсіювач» (перша)
- Тепер з'явиться сюжетний розкид, і ми намалюємо лінію регресії на цьому. Для цього клацніть правою кнопкою миші на будь-якій точці даних та виберіть "Додати лінію тренду"
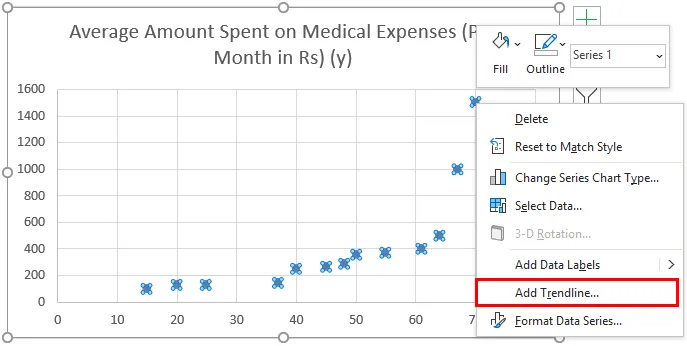
- Тепер на панелі "Форматування лінії трендів" праворуч виберіть "Лінійна лінія тренду" та "Відобразити рівняння на діаграмі".
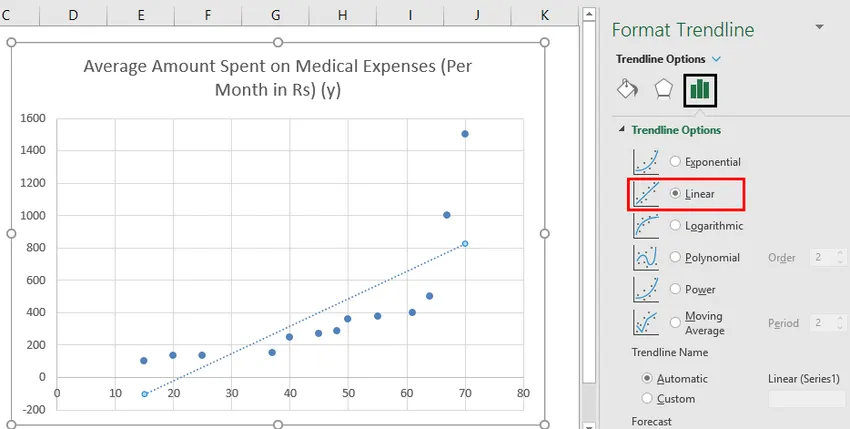
- Виберіть "Відобразити рівняння на діаграмі".
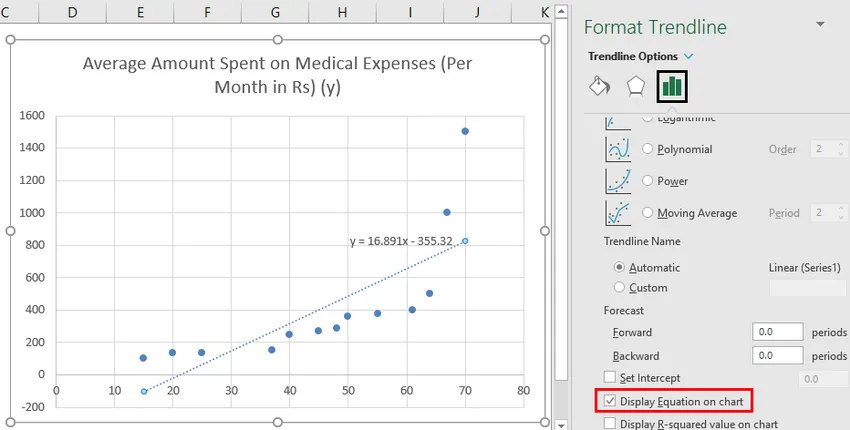
Ми можемо імпровізувати графік відповідно до наших вимог, як додавання заголовків осей, зміна масштабу, кольору та типу лінії.
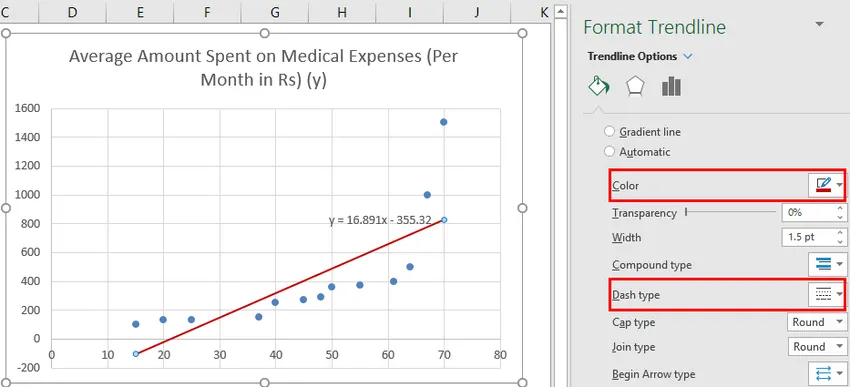
Після вдосконалення діаграми це результат, який ми отримуємо.

Спосіб №2 - Метод надбудови ToolPak для аналізу
Інструмент аналізу ToolPak іноді не включений за замовчуванням, і нам потрібно це робити вручну. Робити так:
- Клацніть на меню "Файл".
Після цього натисніть «Параметри».
- Виберіть "Додатки Excel" у полі "Керування" та натисніть "Перейти"
- Виберіть "Аналіз ToolPak" -> "ОК"
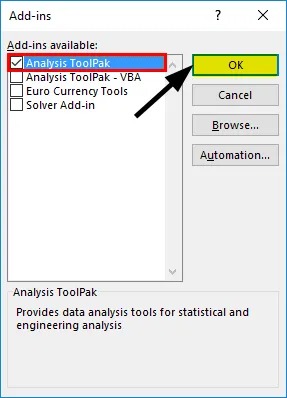
Це додасть інструменти "Аналіз даних" на вкладку "Дані". Тепер ми виконуємо регресійний аналіз:
- Клацніть на "Аналіз даних" на вкладці "Дані"
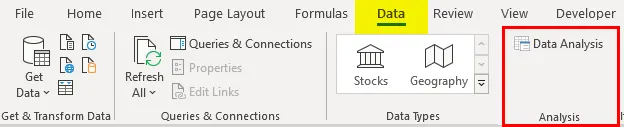
- Виберіть "Регресія" -> "ОК"
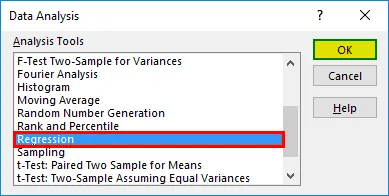
- З'явиться діалогове вікно регресії. Виберіть діапазон Input Y та діапазон Input X (медичні витрати та вік відповідно). У разі множинної лінійної регресії ми можемо вибрати більше стовпців незалежних змінних (наприклад, якщо ми хочемо побачити вплив ІМТ також на медичні витрати).
- Поставте прапорець "Мітки", щоб включити заголовки.
- Виберіть потрібний варіант 'вихід'.
- Установіть прапорець "Залишки" та натисніть "ОК".
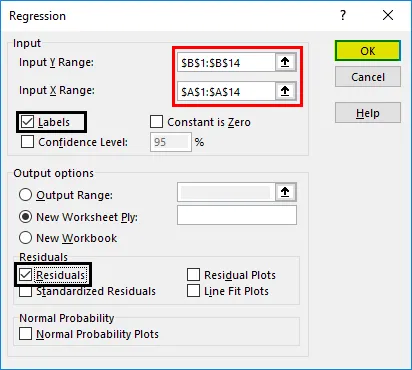
Тепер наш вихід регресійного аналізу буде створений у новому аркуші, в якому зазначається статистика регресії, ANOVA, залишки та коефіцієнти.
Інтерпретація на виході:
- Статистика регресії говорить про те, наскільки рівняння регресії відповідає вмісту даних:
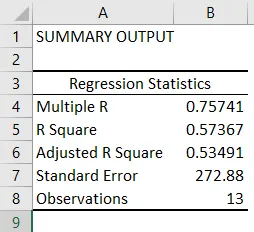
- Множина R - коефіцієнт кореляції, який вимірює силу лінійної залежності між двома змінними. Він лежить між -1 і 1, а його абсолютне значення зображує міцність відносини з великим значенням, що вказує на більш сильну взаємозв'язок, низьке значення вказує на негативне і нульове значення, що вказує на відсутність відносини.
- R Square - коефіцієнт рішучості, який використовується як показник корисності. Він лежить між 0 і 1, значення, близьке до 1, вказує на те, що модель добре підходить. У цьому випадку 0, 57 = 57% значень y пояснюються значеннями x.
- Регульована площа R - це R-квадрат, скоригований для кількості предикторів у разі множинної лінійної регресії.
- Стандартна помилка зображує точність регресійного аналізу.
- Спостереження зображує кількість модельних спостережень.
- Анова розповідає про рівень мінливості в межах регресійної моделі.

Зазвичай це не використовується для простої лінійної регресії. Однак значення "Значення F" вказують на те, наскільки надійні наші результати, значення яких перевищує 0, 05, що дозволяє вибрати інший предиктор.
- Коефіцієнти - це найважливіша частина, яка використовується для складання рівняння регресії.

Отже, наше рівняння регресії було б: y = 16, 891 x - 355, 32. Це те саме, що зроблено методом 1 (діаграма розкидання з лінійкою тренду).
Тепер, якщо ми хочемо прогнозувати середні витрати на медичну допомогу, коли вік становить 72 роки:
Так у = 16.891 * 72 -355.32 = 860.832
Таким чином, ми можемо передбачити значення y для будь-яких інших значень x.
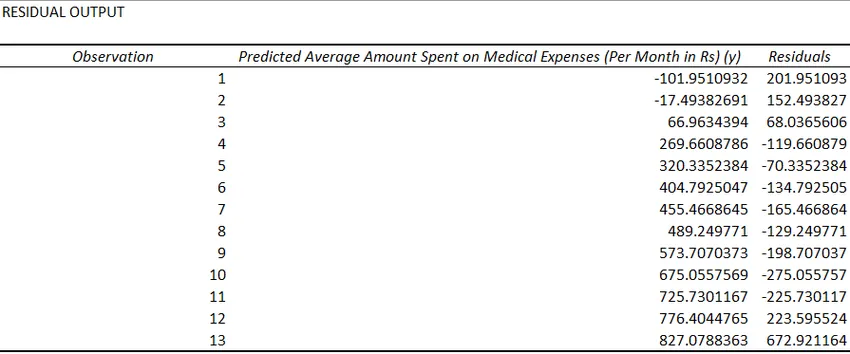
- Залишки вказують на різницю між фактичними та прогнозованими значеннями.
Останній метод регресії використовується не так часто, і для проведення регресійного аналізу потрібні статистичні функції, такі як нахил (), перехоплення (), кореляція () тощо.
Що слід пам’ятати про лінійну регресію в Excel
- Регресійний аналіз зазвичай використовується для того, щоб перевірити, чи існує статистично значуща залежність між двома наборами змінних.
- Він використовується для прогнозування значення залежної змінної на основі значень однієї або декількох незалежних змінних.
- Щоразу, коли ми хочемо приєднати лінійну модель регресії до групи даних, тоді діапазон даних слід ретельно дотримуватись так, ніби ми використовуємо рівняння регресії для прогнозування будь-якого значення поза цим діапазоном (екстраполяція), то це може призвести до неправильних результатів.
Рекомендовані статті
Це посібник з лінійної регресії в Excel. Тут ми обговорюємо, як зробити лінійну регресію в Excel разом з практичними прикладами та шаблоном Excel, який можна завантажити. Ви також можете ознайомитися з іншими запропонованими нами статтями -
- Як підготувати заробітну плату в Excel?
- Використання формули MAX в Excel
- Навчальні посібники з посилань на стільники в Excel
- Створення регресійного аналізу в Excel
- Лінійне програмування в Excel