

Що таке Кафка?
Щоб зрозуміти Кафку, краще зрозуміти, що таке технологія обробки потоку. «Обробка потоків - це технологія, за допомогою якої користувач може запитувати безперервний потік даних у мікро часовому діапазоні, щоб краще зрозуміти основні відповідальні умови.
Сценарій у режимі реального часу - уявіть, чи ваш датчик температури надсилає дані, які ви можете запитувати та отримувати сповіщення після отримання точки замерзання. Цей запит даних можна виконати за мікросекунди.
Визначення
За даними Wiki, це програмне забезпечення для обробки даних з відкритим кодом. Він був розроблений LinkedIn і згодом пожертвував програмне забезпечення Apache.
Розуміння Кафки
Її зростання вибухає експоненціально. Давайте подивимось деякі факти та статистику, щоб краще підкреслити нашу думку. Він користується головною перевагою більше третини Fortune 500 по всьому світу. Цей розподіл поділяють компанії, що займаються туристичним бізнесом, гіганти телекомунікацій, банки та кілька інших. LinkedIn, Microsoft та Netflix обробляють повідомлення з чотирма комами в день разом з Kafka (майже дорівнює 1 000 000 000 000).
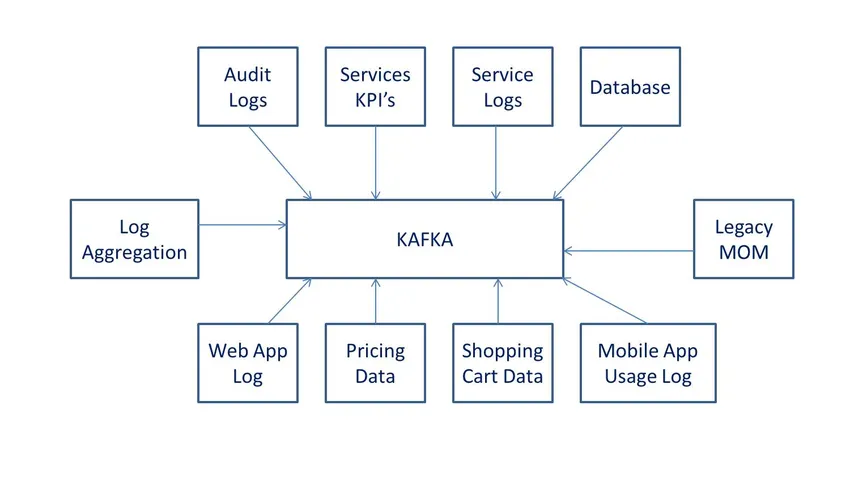
Він використовується для потоків даних у режимі реального часу, для збору великих даних або для аналізу в режимі реального часу (або обох). Kafka використовується з мікросервісами в пам'яті для забезпечення довговічності і може використовуватися для подачі подій на CEP (складні потокові системи потоків) та системи автоматизації в стилі IoT / IFTTT.
Як так легко працює Кафка?
Керована простотою - це правильний спосіб визначити продуктивність. Неважко зрозуміти, як Кафка працює з такою легкістю від її створення та використання. Ця підвищена ефективність поведінки присвячена його стабільності, забезпеченню надійної довговічності, гнучкою вбудованою здатністю публікувати або передплачувати або підтримувати чергу. Це дуже важливо, якщо вам потрібно мати справу з N - кількістю клієнтів, якщо вам доведеться продемонструвати надійну реплікацію на ринку, спрямовану на те, щоб надати своїм клієнтам послідовний підхід (тобто тематичний розділ Kafka). Однією з найважливіших поведінок Kafka, яка відрізняє її від конкурентів, є її сумісність із системами із потоками даних - її процес та дозволяє цим системам об'єднувати, трансформувати та завантажувати інші магазини для зручності роботи. "Усі вищезгадані факти були б неможливими, якби Кафка був повільним". Його виняткові показники роблять це можливим.
З подальшим доповненням для зручності роботи Kafka ми повинні перейти до "OS рівня". Давайте знайдемо, як все працює для Kafka на рівні ОС -
- Він покладається на ядра ОС для швидшого переміщення даних і працює за принципом нульової копії.
- Це дозволяє запису даних збирати в шматки, які можна побачити з файлової системи (він же журнал тематики Kafka) для споживачів.
- Засіб збору даних забезпечує ефективне стиснення даних із зменшенням затримки вводу / виводу.
- Він має можливість масштабування горизонтально за допомогою заточування. Він може розділити журнал заголовків на сотні розділів на тисячі. Це дозволяє їй легко впоратися з великим навантаженням.
Що ти можеш зробити з Кафкою?
Якщо ваша компанія регулярно грає з величезними наборами даних, вам потрібна Kafka. Існує довгий список компаній, які його використовують.
- LinkedIn використовує для відстеження даних та оперативних показників.
- Twitter для забезпечення інфраструктури обробки потоків.
Існує довгий список компаній від Uber до Spotify і Goldman Sachs до Cisco.
Переваги
- Висока пропускна здатність: Він може легко обробляти великий обсяг даних, коли генерування з високою швидкістю є винятковою перевагою на користь Kafka. У цьому додатку не вистачає величезного обладнання. З можливістю підтримувати пропускну здатність повідомлень з частотою тисяч повідомлень в секунду.
- Низька затримка: низька затримка обробки цієї генерації повідомлень високого обсягу.
- Відмовостійкість: Ця функція є дуже корисною, вона має властивість обмежуватися вузлом, вбудованим у кластер.
- Міцний: він дуже довговічний у своїй експлуатації, і тому багато MNC вважають за краще використовувати Kafka. Якщо говорити про довговічність в операціях, повідомлення не можуть загубитися в довгостроковій перспективі.
Необхідні навички
Особливих вимог бути професіоналом Кафки немає. Але ми підкреслили деякі потоки та професіоналів -
- Розробники, які охоче хочуть зробити кар'єру в потоці Big Data і хочуть прискорити кар'єру.
- Фахівці з тестування мають хорошу сферу застосування в Kafka з точки зору систем черги та обміну повідомленнями
- Архітектори - оскільки все потребує певних фреймворків, і цю рамку можна час від часу оновлювати. Архітектори великих даних вважають Кафку гарною інвестицією в кар’єру.
- Керівник проекту потрібен, якщо вищезгаданий фахівець є для кращого управління ресурсами. Отже, вищі посади є також для професіоналів управління в галузі Кафки.
Навіщо використовувати Kafka?
З метою відстеження даних та маніпулювання ними відповідно до потреб бізнесу, Kafka надають перевагу в усьому світі. Це дає можливість передавати дані в режимі реального часу за допомогою аналітики в реальному часі. Він швидкий, масштабований і довговічний і розроблений як стійкість до відмов. В Інтернеті є численні випадки використання, де ви можете зрозуміти, чому JMS, RabbitMQ та AMQP навіть не розглядаються як робота, оскільки необхідність в застосуванні величезних обсягів та чуйності.
Він має високу пропускну здатність, надійну настройку з характеристиками реплікації, що робить його кращим вибором для роботи над датчиками IoT.
Сумісність - ще одна причина його використання та зробила її прийнятною у всьому світі. Його можна легко налаштувати для роботи із переліченим нижче додатком. Ця комбінація дуже важлива для багатьох компаній для розвитку бізнесу та виживання (оскільки це економить час та гроші).
- Флюм
- Іскрова стрічка
- HBase
- Іскра для прийому, обробки та аналізу даних у режимі реального часу.
- Він використовується для годування Hadoop BigData
Область застосування
Це чудово по всьому світу. Ну, ми не говоримо про це, а про статистику. Давай подивимось -
Статистика заробітної плати для професіоналів Kafka - PayScale
- Інженер програмного забезпечення - 109 825 доларів
- Інженер даних - 109 580 доларів
- Розробники - $ 81 182
- Старший інженер даних - 127, 836 дол
Висновок
В даний час Kafka став стандартом де-факто, коли мова йде про аналітику даних у реальному часі з найвищою точністю в мікросекундах. Ми представили свою думку щодо даних та деталей на підтримку технологій Kafka. Є кілька великих компаній, які щодня використовують дані, для цього їм потрібні фахівці, щоб використовувати ці величезні набори даних. З Кафкою можна впевнено вести свою кар’єру в аналітиці BigData
Рекомендовані статті
Це було керівництвом щодо того, що таке Кафка. Тут ми обговорили роботу, масштаби, кар’єрний ріст та переваги компанії Kafka. Ви також можете ознайомитися з іншими запропонованими нами статтями, щоб дізнатися більше -
- Що таке Apache?
- Що таке великі дані та Hadoop?
- Що таке Azure?
- Що таке технології великих даних?
- Кафка проти Іскри | Топ-5 відмінностей
- Огляд та основні програми Kafka
- Кафка проти Кінесіса | 5 Відмінності від Інфографіки