
Що таке алгоритм SVM?
SVM розшифровується як підтримка векторної машини. SVM - це керований алгоритм машинного навчання, який зазвичай використовується для вирішення проблем класифікації та регресії. Поширені програми алгоритму SVM - це система виявлення вторгнень, розпізнавання рукописного тексту, прогнозування структури білка, виявлення стеганографії в цифрових зображеннях тощо.
В алгоритмі SVM кожна точка представлена як елемент даних у межах n-мірного простору, де значенням кожної функції є значення конкретної координати.
Після побудови графіку класифікацію проводили шляхом знаходження площині hype, яка відрізняє два класи. Нижче див. Зображення, щоб зрозуміти цю концепцію.
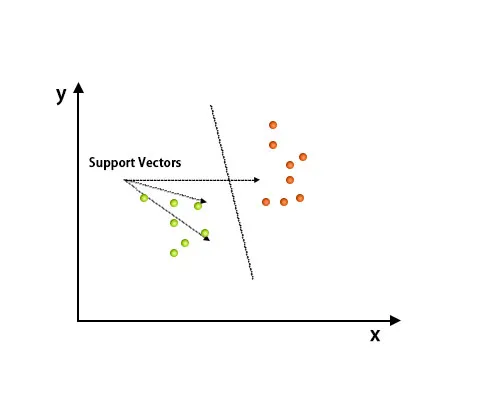
Алгоритм підтримки Vector Machine використовується в основному для вирішення проблем класифікації. Вектори підтримки - це не що інше, як координати кожного елемента даних. Векторна машина підтримки - це межа, яка розрізняє два класи за допомогою гіпер-площини.
Як працює алгоритм SVM?
У наведеному вище розділі ми обговорили диференціацію двох класів за допомогою гіперплощини. Тепер ми побачимо, як насправді працює цей алгоритм SVM.
Сценарій 1: Визначте праву гіперплощину
Тут ми взяли три гіперплощини, тобто A, B і C. Тепер ми повинні визначити правильну гіперплощину для класифікації зірки та кола.
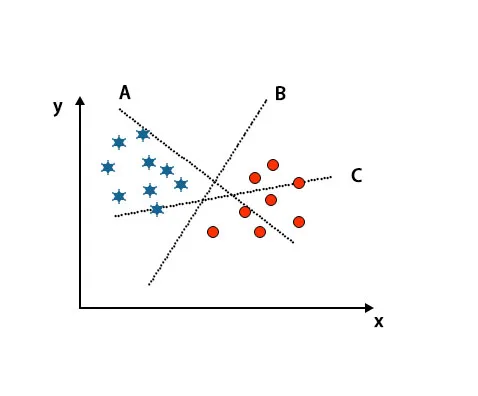
Для виявлення правильної гіперплощини нам слід знати правило великого пальця. Виберіть гіперплощину, яка розрізняє два класи. У вищезгаданому зображенні гіперплощина B дуже добре розмежовує два класи.
Сценарій 2: Визначте праву гіперплощину
Тут ми взяли три гіперплощини, тобто A, B і C. Ці три площини вже дуже добре диференціюють класи.
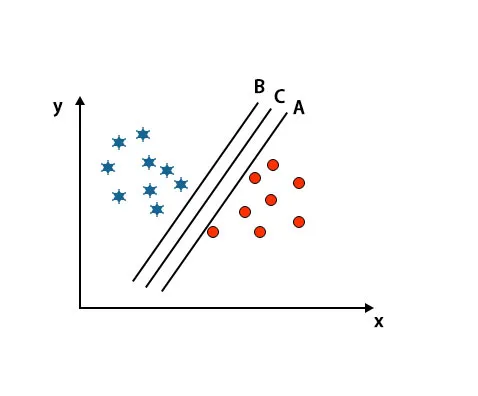
У цьому випадку для виявлення правильної гіперплощини збільшуємо відстань між найближчими точками даних. Ця відстань - це не що інше, як запас. Дивіться нижче зображення.
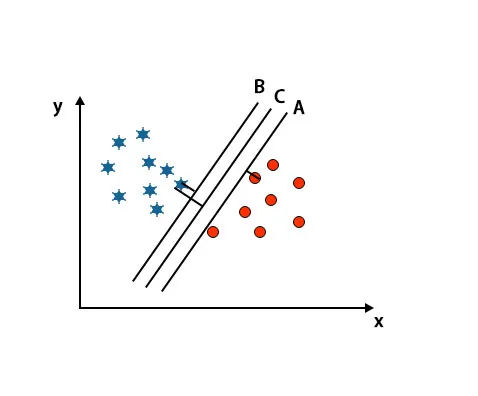
У вищезгаданому зображенні межа гіперплощини C вище, ніж гіперплощина A і гіперплощина B. Отже, у цьому сценарії C - це права гіперплан. Якщо ми обираємо гіперплан з мінімальним запасом, це може призвести до неправильної класифікації. Отже, ми вибрали гіперплан С із максимальним запасом через надійність.
Сценарій 3: Визначте праву гіперплощину
Примітка. Для ідентифікації гіперплощини виконайте ті самі правила, що і в попередніх розділах.
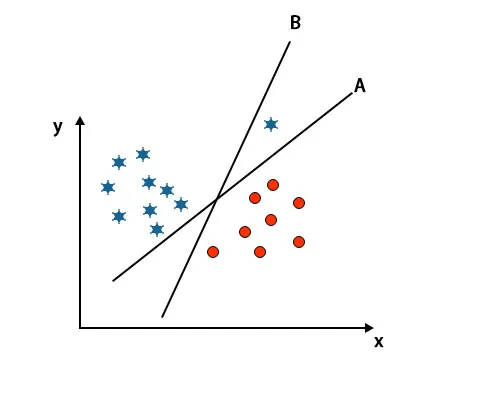
Як ви бачите на вищезгаданому зображенні, межа гіперплощини B вище, ніж межа гіперплощини A, тому деякі виберуть гіпер-площину B як праву. Але в алгоритмі SVM він вибирає ту гіперплощину, яка класифікує класи, точні до досягнення максимального запасу. У цьому сценарії гіперплощина А класифікує все точно і є деяка помилка. З класифікацією гіперплощини В. Тому A є правильною гіперплощиною.
Сценарій 4: Класифікуйте два класи
Як ви бачите на наведеному нижче зображенні, ми не в змозі диференціювати два класи за допомогою прямої лінії, оскільки одна зірка лежить як сторона в другому класі кола.
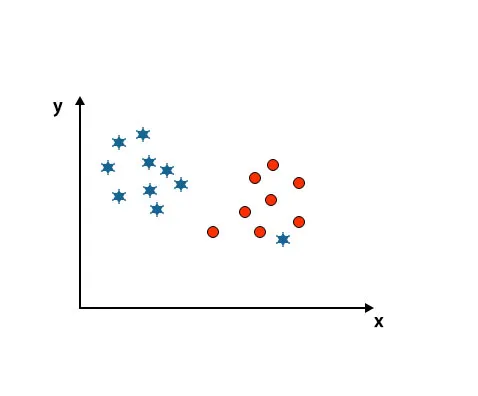
Тут одна зірка в іншому класі. Для зіркового класу ця зірка - це інша людина. Через властивість надійності алгоритму SVM він знайде правильну гіперплану з більш високою маржею, ігноруючи сторонність.
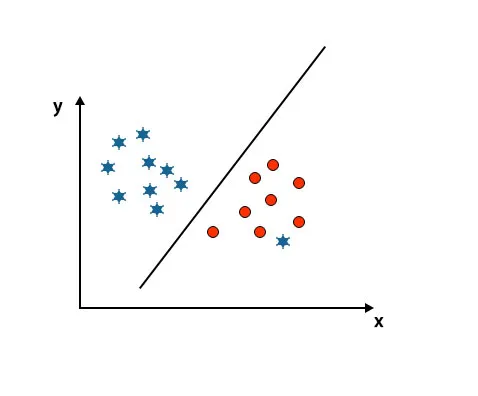
Сценарій 5: Тонка гіперплощина для диференціації класів
До цього часу ми виглядали лінійною гіперплощиною. На наведеному нижче зображенні ми не маємо лінійної гіперплощини між класами.
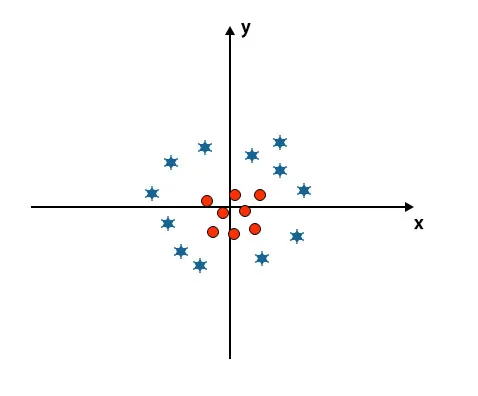
Для класифікації цих класів SVM вводить деякі додаткові функції. У цьому сценарії ми будемо використовувати цю нову функцію z = x 2 + y 2.
Позначення всіх точок даних на осі x і z.

Примітка
- Усі значення на осі z повинні бути позитивними, оскільки z дорівнює сумі x у квадраті та y у квадраті.
- У вищезгаданому сюжеті червоні кола закриті до початку осі x та осі y, приводячи значення z до нижчого, а зірка - прямо протилежну від кола, воно знаходиться далеко від початку виникнення осі x і вісь y, ведучи значення z до високого.
В алгоритмі SVM класифікувати за допомогою лінійної гіперплощини між двома класами легко. Але тут виникає питання, чи варто додати цю особливість SVM для виявлення гіперплощини. Отже, відповідь - ні, для вирішення цієї проблеми SVM має техніку, яку зазвичай називають хитрістю ядра.
Хитрість ядра - це функція, яка перетворює дані у відповідну форму. Існують різні типи функцій ядра, що використовуються в алгоритмі SVM, тобто поліноміальна, лінійна, нелінійна, радіальна основна функція і т.д.
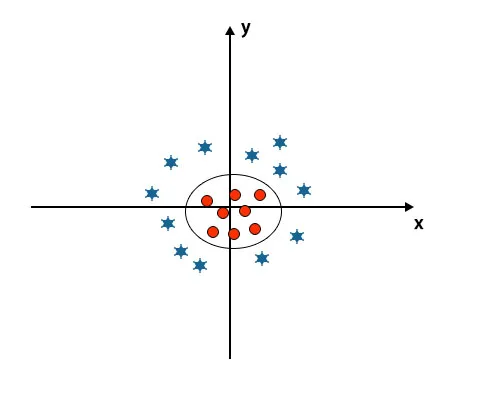
Коли ми дивимося на гіперплощину походження осі та осі у, це виглядає як коло. Дивіться нижче зображення.
Плюси алгоритму SVM
- Навіть якщо вхідні дані нелінійні та нероздільні, SVM генерують точні результати класифікації через її надійність.
- У функції прийняття рішення він використовує підмножину навчальних пунктів, які називаються векторами підтримки, отже, це ефективність пам'яті.
- Корисно вирішити будь-яку складну проблему за допомогою відповідної функції ядра.
- На практиці моделі SVM узагальнені, з меншим ризиком перевиконання у SVM.
- SVM чудово підходить для класифікації тексту та при пошуку найкращого лінійного роздільника.
Мінуси алгоритму SVM
- Робота з великими наборами даних займає тривалий час навчання.
- Важко зрозуміти остаточну модель та індивідуальний вплив.
Висновок
Він керується підтримкою алгоритму векторної машини, який є алгоритмом машинного навчання. У цій статті ми обговорили, що таке алгоритм SVM, як він працює і які його переваги докладно.
Рекомендовані статті
Це було керівництвом до алгоритму SVM. Тут ми обговорюємо його роботу зі сценарієм, плюсами та мінусами алгоритму SVM. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Алгоритми майнінгу даних
- Методи обміну даними
- Що таке машинне навчання?
- Інструменти машинного навчання
- Приклади алгоритму С ++