

Питання та відповіді щодо інтерв'ю - Вступ
Таким чином, ви нарешті знайшли роботу своєї мрії у Splunk, але цікавитесь, як зламати інтерв'ю Splunk та що може бути ймовірним запитанням щодо інтерв'ю Splunk за 2018 рік. Кожне інтерв'ю різне, а сфера роботи теж різна. Маючи це на увазі, ми розробили найпоширеніші запитання та відповіді щодо інтерв'ю Splunk за 2018 рік, щоб допомогти вам досягти успіху в інтерв’ю.Нижче наведені найпопулярніші запитання та відповіді щодо інтерв'ю Splunk. Ці основні питання розділені на дві частини:
Частина 1 - Питання для інтерв'ю Splunk (основні)
Ця перша частина стосується основних запитань та відповідей щодо інтерв'ю Splunk.
1. Що таке сплюнк? Чому Splunk використовується для аналізу даних машини?
Відповідь:
Один з найбільш використовуваних інструментів для аналітики - це Microsoft Excel, і недолік у ньому полягає в тому, що Excel може завантажувати лише до 1048576 рядків, а дані машини, як правило, величезні. Splunk стає корисним у роботі з машинно створеними даними (великі дані), дані з серверів, пристроїв або мереж можна легко завантажувати в Splunk і можуть бути проаналізовані, щоб перевірити наявність видимості, відповідності, безпеки тощо. Вони також можуть бути використані для моніторингу додатків.
2. Поясніть, як працює Splunk
Відповідь:
Це поширені запитання щодо інтерв'ю Splunk, задані в інтерв'ю. Дані завантажуються в Splunk за допомогою експедитора, який діє як інтерфейс між середовищем Splunk та зовнішнім світом, потім ці дані передаються в індексатор, де дані зберігаються локально або в хмарі. Індексатор індексує дані машини та зберігає їх на сервері. Search Head - це графічний інтерфейс, який надає Splunk для пошуку та аналізу даних (шукає, візуалізує, аналізує та виконує різні інші функції) даних.
Сервер розгортання керує всіма компонентами Splunk, як індексатор, експедитор та голова пошуку в середовищі Splunk. 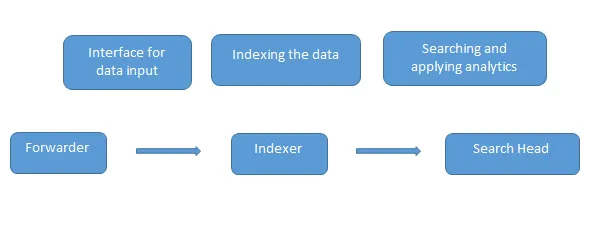
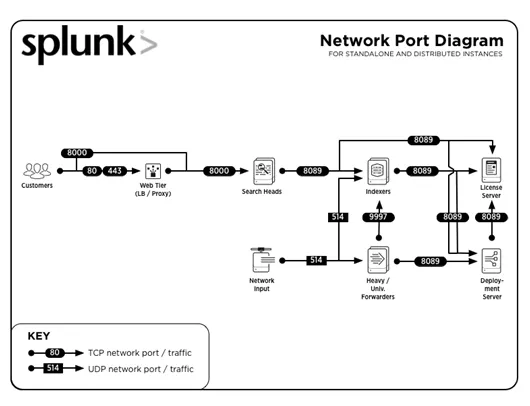
3. Які загальні номери портів використовуються Splunk?
Відповідь :
Загальні номери портів, на яких запускаються служби (за замовчуванням), є:
| Сервіс | Номер порту |
| API управління / REST | 8089 рік |
| Пошук голови / індексатора | 8000 |
| Пошук голови | 8065, 8191 |
| Peer-вузол кластера індексів / Член кластерного пошуку голови | 9887 |
| Індексатор | 9997 |
| Індексатор / експедитор | 514 |
Перейдемо до наступних запитань щодо інтерв'ю Splunk.
4. Навіщо використовувати тільки Splunk?
Відповідь:
Є багато альтернатив для Splunk, які дають йому велику конкуренцію, деякі з них наведені нижче:
• ELK / Logstash (відкритий код)
Elasticsearch використовується для пошуку - це як пошукова головка в Splunk, сховище журналу - для збору даних, схожого на експедитора, який використовується у Splunk, а Kibana використовується для візуалізації даних (пошук пошуку робить те саме в Splunk)
• Graylog (відкритий код з комерційною версією)
Graylog - це ще один інструмент, який отримав назву минулого року з його випуском 1.0. Подібно до ELK стека Graylog також має різні компоненти, він використовує Elasticsearch в якості свого основного компонента, але дані зберігаються в DB DB і використовує Apache Kafka. Він має дві версії, одна основна версія, яка доступна безкоштовно, і корпоративна версія, яка постачається з такими функціями, як архівування.
• Логіка сумо (хмарний сервіс)
Отже, що робить Splunk найкращим серед усіх, це те, що Splunk поставляється як єдиний пакет збирача даних, зберігання, а також вбудований інструмент аналітики. Splunk також масштабується і надає підтримку / професійну допомогу для свого корпоративного видання.
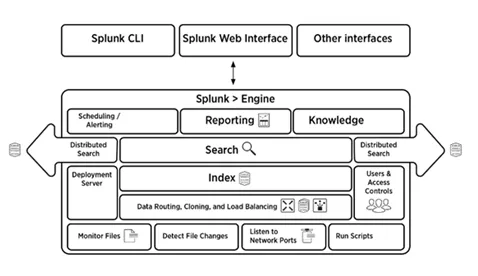
5. Коротко поясніть архітектуру Splunk
Відповідь:
На малюнку нижче короткий огляд архітектури Splunk та її компонентів.
Частина 2 - Питання інтерв'ю Splunk (Додатково)
Давайте тепер подивимося на розширені питання щодо інтерв'ю Splunk.
6. Які компоненти архітектури Splunk?
Відповідь:
У архітектурі Splunk є чотири компоненти. Вони є:
- Індексатор: Індексує машинні дані
- Форвардер: журнали вперед для індексації
- Голова пошуку: надає графічний інтерфейс для пошуку
- Сервер розгортання: Керує компонентами Splunk (індексатором, пересилачем та головою пошуку) у розподіленому середовищі
7. Наведіть кілька випадків використання об'єктів знань.
Відповідь :
Це найчастіші запитання Splunk в інтерв'ю. Об'єкти знань можна використовувати в багатьох областях. Кілька прикладів:
Моніторинг програм: Це може використовуватися для моніторингу програм у режимі реального часу за допомогою налаштованих попереджень, які сповіщатимуть адміністраторів / користувачів про збій програми.
Фізична безпека: у разі повені / вулканічних тощо дані можуть бути використані для отримання розуміння, якщо ваша організація має справу з будь-якими подібними даними.
Безпека мережі: Ви можете створити захищене середовище шляхом чорного списку IP невідомих пристроїв, тим самим зменшивши витоки даних у будь-якій організації.
Управління працівниками: Потерпіння працівників - це одне із викликів, з якими стикається будь-яка організація, і протягом періоду сповіщення можна відстежувати діяльність працівника з метою захисту даних організації, тим самим відстежуючи їхню діяльність та обмежуючи будь-якого іншого працівника у термін повідомлення не робити цього .
8. Поясніть фактор пошуку (SF) та фактор реплікації (РФ)
Відповідь:
Це термінології, які використовуються в методах кластеризації Splunk. Кластер індексаторів - це спеціально налаштована група індексаторів Splunk Enterprise, яка копіює зовнішні дані та використовується для відновлення після аварій.
З точки зору пошуку документації Splunk, коефіцієнт може бути описаний як "Кількість копій даних, які можна шукати, що підтримує кластер індексаторів. Значення фактора пошуку за замовчуванням - 2 ”, тоді як коефіцієнт реплікації визначається як кількість копій даних, які підтримує кластер.
Кластер індексатора має як Фактор пошуку, так і Фактор реплікації, тоді як в кластері пошуку в голові є тільки Фактор пошуку
Перейдемо до наступних запитань щодо інтерв'ю Splunk.
9. Що таке відра Splunk? Поясніть життєвий цикл відра.
Відповідь:
Каталоги, в яких зберігаються індексовані дані, називаються відрами Splunk, і вони мають події певного періоду. Життєвий цикл відра Splunk включає чотири етапи гарячого, теплого, холодного, замороженого та відталого.
- Гаряча - Це відро містить недавно проіндексовані дані і відкрите для запису.
- Теплий - Після того, як дані потрапляють у гаряче відро, залежно від вашої політики передачі даних, вони переходять у прогріті відра
- Холод - Наступний після теплий етап - це холодний етап, на якому дані не можна редагувати.
- Заморожений - за замовчуванням індексатор видаляє дані із заморожених відра, але вони також можуть бути заархівовані.
- Розморожена - отримання інформації з архівованих файлів (заморожене відро) відоме як розморожування.
10. Чому ми повинні використовувати сповіщення Splunk? Які існують варіанти під час налаштування сповіщень?
Відповідь:
Стан спостереження за будь-якою можливою помилкою називається попередженням, а в Splunk повідомлення про оточення можуть виникати через будь-які збої в зв’язку чи порушення безпеки або порушення будь-яких створених користувачем правил.
Наприклад, надсилання сповіщень або звіту користувачів, які не змогли увійти після використання своїх трьох спроб на порталі адміністратору програм.
Під час налаштування сповіщень доступні різні варіанти:
- Можна створити веб-гачок для написання сповіщень на hipchat або GitHub.
- Додайте результати, .csv або pdf або у відповідність із текстом повідомлення, щоб визначити першопричину сповіщення.
- Квитки можна створити, а попередження можна скинути з машини або IP-адреси.
Рекомендована стаття
Це посібник для списку запитань та відповідей щодо інтерв'ю, що дозволяє кандидату легко розправити ці запитання та відповіді щодо інтерв'ю. Ви також можете переглянути наступну статтю s, щоб дізнатися більше -
- Питання щодо інтерв'ю щодо системи SAS - 10 найкращих корисних питань
- 10 чудових запитань щодо інтерв'ю, які Ви повинні знати
- 15 найуспішніших запитань та відповідей щодо інтерв'ю Oracle
- Питання щодо інтерв'ю з мережевої безпеки - найпопулярніші та найбільш задані
- Splunk vs Nagios