

Що таке великі дані та Hadoop?
Дані щодня зростають експоненціально, і при таких зростаючих даних виникає потреба у використанні цих даних. Як і в попередні дні, у нас були дискети для зберігання даних, і передача даних також була повільною, але в наш час їх недостатньо, і хмарне зберігання використовується, оскільки у нас є терабайти даних. У сучасному світі у нас є соціальні медіа, які сприяють зростанню даних. Він складається з поведінки людей, мислення та кількох інших аспектів. Кажуть, що щохвилини 300 годин відео завантажується на YouTube, понад 20 мільйонів фотографій завантажуються у Facebook та багато інших. Більше того, немає належної структури завантажуваних даних, що є найбільшою проблемою для обробки цих даних.
Оскільки величезні дані формуються з високою швидкістю, традиційні системи RDBMS не змогли впоратися з таким швидким зростанням. Більше того, вони також не здатні обробляти неструктуровані дані. Стало дуже важко обробляти таку величезну кількість неоднорідних даних, що швидко зростають, та обробляти ці дані з високою швидкістю обробки. Таким чином, виникла потреба в такій системі, яка здатна ефективно обробляти великі набори даних. Отже, для вирішення сценарію виникло Hadoop. HDFS - це компонент Hadoop, який вирішив питання зберігання великого набору даних, використовуючи розподілене сховище, тоді як YARN - це компонент, який вирішив проблему обробки, різко скоротивши час обробки.
Hadoop - це програмне забезпечення з відкритим кодом для зберігання та обробки наборів великих даних за допомогою розподіленого великого кластеру товарного обладнання. Він був розроблений Дугом Різком та Майклом Дж. Кафарелла та отримав ліцензію під Apache. Він написаний за допомогою Java і був розроблений на основі документа, написаного Google в системі MapReduce, і він застосовує концепції функціонального програмування. Це надійний, економічний гнучкий і масштабований.
Основні компоненти Hadoop
Основними компонентами Hadoop є наступні
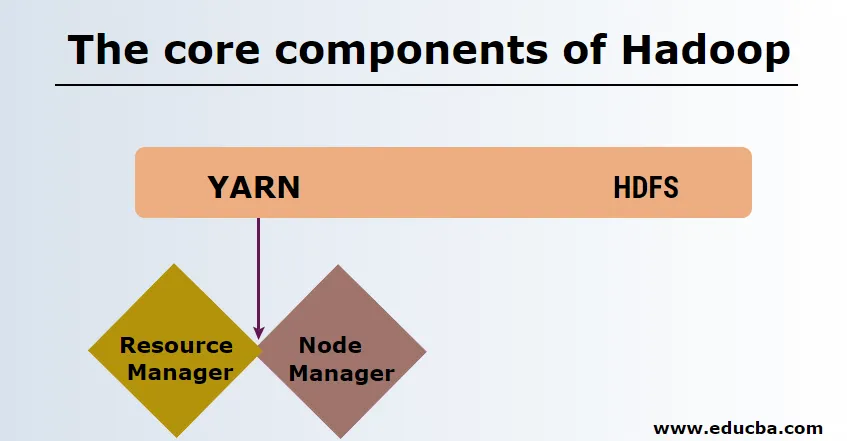
-
HDFS
HDFS або розподілена файлова система Hadoop мають Namenode і вузол даних. Namenode - це головний вузол, на якому працює головний демон, і він керує вузлами даних і відстежує всі операції. Датаноди - це раби, де фактично зберігаються дані.
-
Пряжа
Пряжа складається з двох основних компонентів:
1. ResourceManager: Він працює на головному вузлі і управляє всіма ресурсами і планує всі програми. У ньому є Scheduler & ApplicationManager.
2. NodeManager: Він працює на кожному підлеглому вузлі і відповідає за управління контейнерами та моніторинг використання ресурсів.
Кілька компонентів Hadoop
Є кілька компонентів Hadoop, як свиня, вулик, кукуруза, флюм, махут, озі, зоокер, HBase та ін.
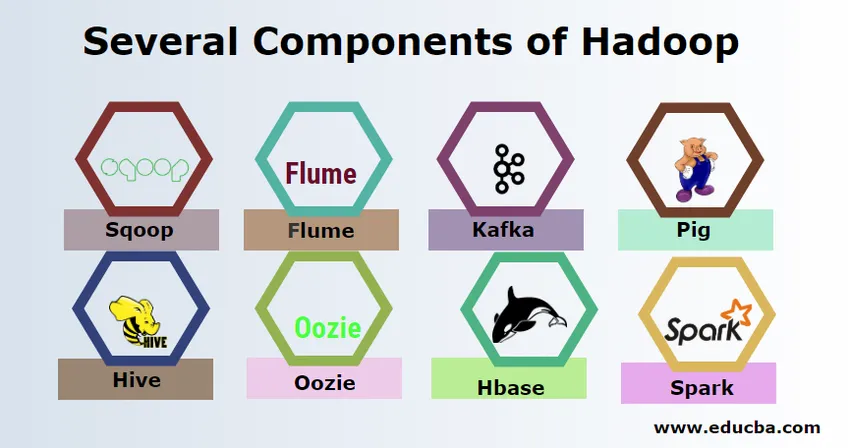
- Sqoop - використовується для імпорту та експорту даних з RDBMS в Hadoop і навпаки.
- Flume - використовується для перетягування даних у режимі реального часу в Hadoop.
- Kafka - це система обміну повідомленнями, яка використовується для маршрутизації даних у режимі реального часу в Hadoop.
- Свиня - використовується як сценарій мови для обробки даних.
- Вулик - це структура для зберігання даних, побудована на HDFS, щоб користувачі, знайомі з SQL, могли виконувати запити для отримання даних. Ці запити називаються HiveQL.
- Oozie - Він використовується для планування робочого процесу завдань, які виконуються на визначені події або час.
- Hbase - це не база даних SQL, яка є частиною Apache Hadoop.
- Іскра - Використовується для виконання обробки в пам'яті, яка значно швидше, ніж зменшення карти Hadoop.
Провайдери Hadoop
Є багато компаній, що пропонують дистрибуцію Hadoop. Нижче наведено кілька кращих постачальників послуг Hadoop:
- Cloudera
- Hortonworks
- MapR
Існує небагато передумов для вивчення Hadoop. Попередній досвід роботи в Java та мовах скриптів необхідний. Хоча Hadoop вже має власні мови програмування високого рівня, такі як свиня та вулик, що генерує резервний код для подальшої обробки, все ж можна створити власну програму зменшення карти будь-якою мовою програмування, як програмування Ruby, Python, Perl і навіть C.
Bigdata та Hadoop користуються великим попитом на сучасному ринку. Це збільшиться в найближчі дні. Багато організацій уже переїхали в Hadoop, а ті, хто не збирається переїхати незабаром. Існує поточний звіт, в якому йдеться про те, що великі корпорації почали інвестувати в аналітику великих даних. Прогноз маркетингу великих даних завжди в тенденції до зростання, і це зовсім не короткочасний стан. Крім усього цього, робочі місця в Hadoop і великі дані завжди пропонують високу оплату порівняно з іншими технологіями.
Найкращі великі компанії даних та Hadoop
Нижче наведено кілька найкращих компаній, що використовують найбільшу кількість ресурсів Hadoop.
- Yahoo
- Амазонка
- Королівський банк Шотландії
- British Airways
- Експедиція
- Вальмарт
Є велика кількість компаній, які використовують додатки великих даних. Це:
-
Nokia
Для цього використовується компоненти Cloudera та Hadoop, такі як HDFS, HBase, Sqoop, Scribe. Він ефективно використовував дані користувачів, щоб зрозуміти та покращити роботу користувача. Він використовує обробку даних та комплексний аналіз для побудови карти з прогнозним трафіком та шаруватими моделями висот.
-
SAS
Він співпрацює з Hadoop для того, щоб допомогти науковцям даних краще зрозуміти, забезпечуючи середовище, що надає візуальний та інтерактивний досвід, допомагаючи досліджувати нові тенденції. Аналітичні програми отримують значущі відомості з даних, а технологія в пам'яті допомагає більш швидкому доступу до даних.
Існує також багато інших компаній, які використовують великі платформи даних для різних аналізів. Це аналіз даних польотів чорної скриньки в авіаційній галузі, різний аналіз на ринку акцій тощо.
Переваги Хаддопа
Нижче наведено декілька переваг Hadoop
- Масштабованість - На відміну від традиційних RDBMS, це дуже масштабована платформа, оскільки вона може зберігати великі набори даних у розподілених кластерах над товарним обладнанням, що працює паралельно.
- Економічно вигідна - вартість була занадто високою для RDBMS для зберігання даних, які були зняті в Hadoop.
- Швидкий та гнучкий - Він пропонує швидкий доступ до даних через розподілену файлову систему. Він також пропонує отримати ділову інформацію з напівструктурованих та неструктурованих даних.
- Толерантність до відмов - кожного разу, коли будь-які дані надсилаються до вузла, ті самі дані реплікуються в інші вузли, до яких можна отримати доступ у разі будь-якого збою першого вузла.
Висновок - що таке Big Data та Hadoop
Дані постійно зростають, і тому завжди знадобляться великі дані, а Hadoop має сенс використовувати ці дані. З цієї причини професіонали з навичками Hadoop завжди знайдуть широкі можливості в найближчі дні і можуть стати життєво важливим надбанням для організації, що сприяє розвитку бізнесу та їх кар’єрі.
Рекомендовані статті
Це було керівництвом щодо того, що таке Big Data та Hadoop. Тут ми обговорили основні поняття та компоненти великих даних та Hadoop. Ви також можете переглянути наступну статтю, щоб дізнатися більше -
- Приклади великих даних Analytics
- Використання Hadoop
- Посібник з візуалізації даних
- Що таке аналітика великих даних?