

Вступ до DataFrame Pandas Python Pandas
В Інтернеті можна знайти кілька розширень для бібліотеки Python, Pandas. Одним із таких є панельні (панельні) дані (дати). Це слово, * панель *, тонко натякає на двовимірну структуру даних, наявну в цій бібліотеці, надзвичайно розширюючи можливості своїх користувачів. Ця сама структура називається DataFrame.
Це, по суті, матриця рядків і стовпців, що містить весь ваш набір даних, із дуже детальними варіантами індексації однакових. DataFrame (DF), можна уявити мальовничо дуже схожим на лист Excel. Але це робить його потужним - це простота, з якою можна проводити аналітичні та трансформаційні операції над даними, що зберігаються в DataFrame.
Що саме є DataFrame Python Pandas?
Сторінка Pydata може бути посилається на щось офіційне визначення.
Якщо правильно зрозуміти, він згадує DataFrame як стовпчасту структуру, здатну зберігати будь-який об’єкт python (включаючи сам DataFrame) як одне значення комірки. (Клітина індексується за допомогою унікальної комбінації рядків та стовпців)
DataFrames складається з трьох основних компонентів: даних, рядків та стовпців.
- Дані: Це стосується фактичних об'єктів / сутностей, що зберігаються в комірці в DataFrame, та значень, представлених цими об'єктами. Об'єктом є будь-який дійсний тип даних python, будь то вбудований або визначений користувачем.
- Рядки: Посилання, які використовуються для ідентифікації (або індексації) певного набору спостережень із повних даних, що зберігаються у DataFrame, називаються рядками. Для того, щоб було зрозуміло, він представляє використані індекси, а не лише дані в конкретному спостереженні.
- Стовпці: Посилання, що використовуються для ідентифікації (або індексу) набору атрибутів для всіх спостережень у DataFrame. Як і у випадку з рядками, вони посилаються на індекс стовпців (або заголовки стовпців), а не лише на дані у стовпці.
Тож без зайвої приналежності спробуємо кілька способів створення цих приголомшливо потужних структур.
Крок до створення фреймів даних Python Pandas
Файл даних Python Pandas DataFrame можна створити за допомогою наступної реалізації коду,
1. Імпортувати панди
Щоб створити DataFrames, бібліотеку панд потрібно імпортувати (тут не дивно). Ми імпортуємо його з псевдонімом pd для посилання на об'єкти в модулі зручно.
Код:
import pandas as pd
2. Створення першого об'єкта DataFrame
Після імпорту бібліотеки у ваш робочий простір доступні всі методи, функції та конструктори. Отже, спробуємо створити ванільну DataFrame.
Код:
import pandas as pd
df = pd.DataFrame()
print(df)
Вихід:
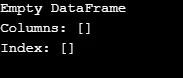
Як показано у висновку, конструктор повертає порожню DataFrame.
Тепер зупинимось на створенні DataFrames з даних, що зберігаються в деяких вірогідних уявленнях.
- Скажімо, DataFrame від A Dictionary: Скажімо, у нас є словник, що зберігає список компаній, що входять у Software Domain, та кількість років, в яких вони були активними.
Код:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Давайте подивимось представлення повернутого об’єкта DataFrame, друкуючи його на консолі.
Вихід:

Як видно, кожен ключ словника трактується як стовпець у DataFrame, а індекси рядків генеруються автоматично, починаючи з 0. Досить просто так!
Тепер скажімо, що ви хотіли дати йому спеціальний індекс замість 0, 1, .. 4. Вам просто потрібно передати потрібний список в якості параметра конструктору, і панди зроблять необхідне.
Код:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Вихід:
Компанія Вік
Альфа Google 21
Бета-Амазонія 23
Gamma Infosys 38
Delta Directi 22
Тепер ви можете встановити індекси рядків на будь-яке бажане значення.
- DataFrame з файлу CSV: Створимо файл CSV, що містить ті самі дані, що і у нашому словнику. Давайте назвемо файл CompanyAge.csv
Google, 21
Амазонка, 23
Інфосис, 38
Directi, 22
Файл можна завантажити в кадр даних (якщо він присутній у поточній робочій директорії) наступним чином.
Код:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Вихід:
Компанія Вік
0 Google 21
1 Амазонка 23
2 Infosys 38
3 Directi 22
Встановлення імен параметрів , минаючи список значень, призначає їх як заголовки стовпців у тому ж порядку, в якому вони є у списку. Аналогічно, індекси рядків можна встановити, передавши список параметру індексу, як показано в попередньому розділі. Заголовок = Немає вказує відсутніх заголовків стовпців у файлі даних.
Скажімо, назви стовпців були частиною файлу даних. Тоді встановлення заголовка = False виконає необхідну роботу.
3. CompanyAgeWithHeader.csv
Компанія, вік
Google, 21
Амазонка, 23
Інфосис, 38
Directi, 22
Кодекс буде змінено на
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Вихід:
Компанія Вік
0 Google 21
1 Амазонка 23
2 Infosys 38
3 Directi 22
- DataFrame з файлу Excel: Дані часто обмінюються у файлах excel, оскільки вони залишаються найпопулярнішим інструментом, який використовують звичайні люди для відстеження Adhoc. Таким чином, не слід ігнорувати нашу дискусію.
Припустимо, ці дані, як і в CompanyAgeWithHeader.csv, тепер зберігаються в CompanyAgeWithHeader.xlsx, на аркуші з назвою Company Age. Той самий DataFrame, як описано вище, буде створений наступним кодом.
Код:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Вихід:
Компанія Вік
0 Google 21
1 Амазонка 23
2 Infosys 38
3 Directi 22
Як бачите, той самий DataFrame можна створити, передавши ім'я файлу та ім'я аркуша.
Подальше читання та наступні кроки
Показані методи складають дуже малий підмножина порівняно з усіма різними способами створення DataFrames. Вони були створені з наміром розпочати роботу. Ви обов'язково повинні вивчити перелічені посилання та спробувати вивчити інші способи, включаючи підключення до бази даних для зчитування даних безпосередньо з DataFrame.
Висновок
Pandas DataFrame зарекомендував себе як зміна ігор у світі наукових даних та даних Analytics, а також є зручним для тимчасових короткострокових проектів. Він оснащений цілою армією інструментів, здатних гранично легко розрізати та записувати набір даних. Сподіваємось, це послужить кроком для вашої подорожі вперед.
Рекомендовані статті
Це посібник із програми Python-Pandas DataFrame. Тут ми обговорюємо кроки створення фрейму даних python-pandas разом з його реалізацією коду. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Топ-15 особливостей Python
- Різні типи наборів Python
- Топ-4 типи змінних на Python
- Топ-6 редакторів Python
- Масиви в структурі даних