
Визначення алгоритму середнього зсуву
Алгоритм середнього зсуву підпадає під непідконтрольне навчання, яке класифікується як алгоритм кластеризації. Ідеологія алгоритму середнього зсуву полягає в тому, що він ітеративно присвоює точки даних кластерам шляхом зміщення в бік точки, що має точку найбільшої щільності (Режим). Середня логіка зрушення, що лежить в основі, заснована на концепції оцінки щільності ядра, що називається KDE.
Середнє зсув алгоритму зсуву
Техніка навчання без нагляду, виявлена Фукунага та Хостеллером для пошуку кластерів:
- Середній зсув також відомий як алгоритм пошуку режимів, який призначає точки даних кластерам таким чином, зміщуючи точки даних у напрямку високої щільності. Найвища щільність точок даних називається моделлю в регіоні. Алгоритм Mean Shift має додатки, широко використовувані в області комп’ютерного зору та сегментації зображень.
- KDE - це метод оцінки розподілу точок даних. Він працює, розміщуючи ядро на кожній точці даних. Ядро в математичному терміні - це система зважування, яка застосовуватиме ваги для окремих точок даних. Додавання всіх окремих ядер створює ймовірність.
Функція ядра повинна відповідати наступним умовам:
- Перша вимога - забезпечити нормалізацію оцінки щільності ядра.
- Друга вимога - KDE добре асоціюється з симетрією простору.
Дві популярні функції ядра
Нижче наведені дві популярні функції ядра:
- Плоский ядро
- Гауссова ядро
- На основі використаної парами Кернела функція густини в результаті змінюється. Якщо параметр ядра не згадується, за замовчуванням викликається ядро Гаусса. KDE використовує концепцію функції щільності ймовірності, яка допомагає знайти локальні максимуми розподілу даних. Алгоритм працює, створюючи точки даних для залучення один одного, дозволяючи точкам даних у напрямку високої щільності.
- Точки даних, які намагаються сходитись до локальних максимумів, будуть тієї ж групи кластерів. На відміну від алгоритму кластеризації K-Means, вихід алгоритму середнього зсуву не залежить від припущень щодо форми точки даних та кількості кластерів. Кількість кластерів визначатиметься алгоритмом щодо даних.
- Для того, щоб виконати реалізацію алгоритму середнього зсуву, ми використовуємо пакет python SKlearn.
Впровадження алгоритму середнього зсуву
Нижче наведено реалізацію алгоритму:
Приклад №1
На основі підручника Sklearn для алгоритму кластеризації середнього зсуву. Перший фрагмент реалізує алгоритм середнього зсуву для пошуку кластерів двовимірного набору даних. Пакети, які використовуються для реалізації алгоритму середнього зсуву.
Код:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Важливо відзначити, що ми будемо використовувати бібліотеку make_blobs sklearn для генерування точок даних, зосереджених у трьох місцях. Для того, щоб застосувати алгоритм середнього зсуву до згенерованих точок, ми повинні встановити пропускну здатність, яка представляє взаємодію між довжиною. Бібліотека Склеарна має вбудовані функції для оцінки пропускної здатності.
Код:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Вищенаведений фрагмент виконує кластеризацію, а алгоритм знайдених кластерів зосереджений на кожній створеній нами крапці. Ми бачимо, що із наведеного нижче зображення, нанесеного фрагментом, показаний алгоритм середнього зсуву, здатний ідентифікувати кількість кластерів, необхідних за час виконання, та визначити відповідну пропускну здатність для відображення тривалості взаємодії.
Вихід:
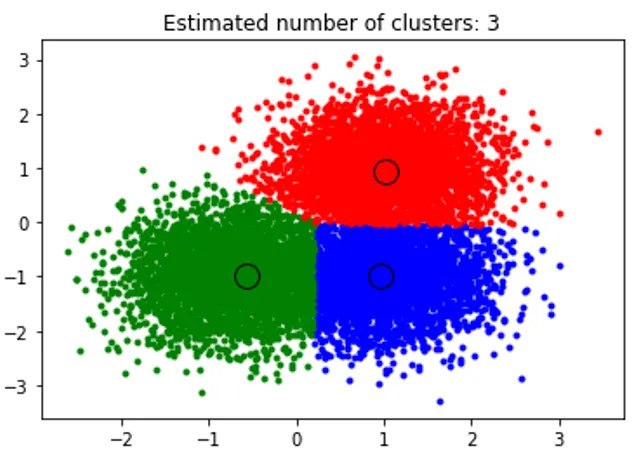
Приклад №2
На основі сегментації зображень у комп’ютерному баченні. Другий фрагмент вивчить, як алгоритм середнього зсуву використовується в глибокому навчанні для виконання сегментації кольорового зображення. Ми використовуємо алгоритм середнього зсуву для ідентифікації просторових кластерів. У попередньому фрагменті ми використовували двовимірний набір даних, тоді як у цьому прикладі буде вивчено 3-D простір. Піксель зображення буде розглядатися як точки даних (r, g, b). Нам потрібно перетворити зображення у формат масиву, щоб кожен піксель представляв собою точку даних у зображенні, яке ми збираємося в сегмент. Кластеризація кольорових значень у просторі повертає серію кластерів, де пікселі кластера будуть аналогічні простору RGB. Пакети, які використовуються для реалізації алгоритму середнього зсуву:
Код:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Нижче фрагмент, щоб виконати сегментацію вихідного зображення:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Згенероване зображення констатує, що такий підхід до виявлення форм зображень та визначення просторових кластерів може бути здійснений ефективно без будь-якої обробки зображень.
Вихід:


Переваги та застосування Алгоритм середнього зсуву
Нижче наведено переваги та застосування середнього алгоритму:
- Він широко використовується для вирішення комп’ютерного зору, де він використовується для сегментації зображень.
- Кластеризація точок даних у режимі реального часу без згадування кількості кластерів.
- Відмінна в сегментації зображень та відстеженні відео.
- Більш надійний для людей, що переживають.
Плюси алгоритму середнього зсуву
Нижче наведено алгоритм зсуву плюсів:
- Вихід алгоритму не залежить від ініціалізації.
- Процедура ефективна, оскільки має лише один параметр - пропускну здатність.
- Ніяких припущень щодо кількості кластерів даних та форми.
- Він має кращі показники, ніж K-Means Clustering.
Мінуси алгоритму середнього зсуву
Нижче наведені мінуси алгоритму середнього зсуву:
- Дорогий для великих функцій.
- У порівнянні з кластеризацією K-Means це дуже повільно.
- Вихід алгоритму залежить від пропускної здатності параметра.
- Вихід залежить від розміру вікна.
Висновок
Хоча це прямолінійний підхід, який в основному використовується для вирішення проблем, пов'язаних із сегментацією зображень, кластеризацією. Він порівняно повільніше, ніж K-Means, і обчислювально дорогий.
Рекомендовані статті
Це керівництво до алгоритму середнього зсуву. Тут ми обговорюємо проблеми, пов’язані з сегментацією зображення, кластеризацією, перевагами та двома функціями ядра. Ви також можете ознайомитись з іншими пов'язаними з нами статтями, щоб дізнатися більше -
- K- означає алгоритм кластеризації
- Алгоритм KNN в R
- Що таке генетичний алгоритм?
- Методи ядра
- Методи ядра в машинному навчанні
- Детально Пояснення алгоритму С ++