

Вступ до дерева рішень при обробці даних
У сучасному світі "Big Data" термін "Data Mining" означає, що нам потрібно роздивитися великі набори даних та виконати "майнінг" даних і вивести важливий сік або суть того, що дані хочуть сказати. Дуже аналогічна ситуація з видобутком вугілля, коли для видобутку вугілля, закопаного глибоко під землею, потрібні різні інструменти. З інструментів обміну даними одним із них є «Дерево рішень». Таким чином, обмін даними сам по собі є величезним полем, в якому наступні кілька абзаців ми будемо глибоко занурюватися в «інструмент» Дерева рішень у майнінгу даних.
Алгоритм дерева рішень при обробці даних
Дерево рішень - це підхід під наглядом під наглядом, в якому ми навчаємо наявні дані, вже знаючи, що є цільовою змінною. Як випливає з назви, цей алгоритм має структуру типу дерева. Давайте спочатку розглянемо теоретичний аспект Дерева рішень, а потім розглянемо те саме в графічному підході. У дереві рішень алгоритм розбиває набір даних на підмножини на основі найважливішого або значущого атрибута. Найбільш значущий атрибут позначений у кореневому вузлі, і саме там відбувається розщеплення всього набору даних, присутніх у кореневому вузлі. Це розщеплення відоме як вузли прийняття рішень. У випадку, якщо більше розщеплення неможливо, вузол називається листковим вузлом.
Для того, щоб зупинити алгоритм для досягнення переважної стадії, використовується критерій зупинки. Одним із критеріїв зупинки є мінімальна кількість спостережень у вузлі до того, як відбудеться розкол. Застосовуючи дерево рішень для розбиття набору даних, потрібно бути обережним, щоб багато вузлів просто мали шумні дані. Для задоволення сторонніх чи галасливих проблем з даними ми використовуємо методи, відомі як Обрізка даних. Обрізання даних - це не що інше, як алгоритм класифікації даних із підмножини, що ускладнює навчання за певною моделлю.
Алгоритм дерева рішень був випущений у вигляді ID3 (Ітеративний дихотомізер) дослідником машин Дж. Россом Квінланом. Пізніше C4.5 був звільнений як наступник ID3. І ID3, і C4.5 - жадібний підхід. Тепер розглянемо схему алгоритму дерева рішень.
Для нашого розуміння псевдокоду ми б взяли «n» точки даних, кожна з яких має атрибути «k». Нижче наведено блок-схему, враховуючи «Приріст інформації» як умову розколу.
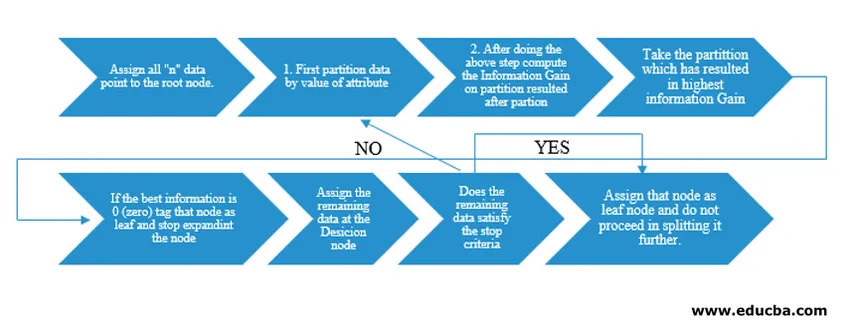
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Замість збільшення інформації (IG) ми також можемо використовувати індекс Джині як критерій розколу. Для розуміння різниці між цими двома критеріями в простому розумінні ми можемо розглянути цей інформаційний приріст як різницю ентропії до розколу та після розколу (розбиття на основі всіх доступних функцій).
Ентропія - це як випадковість, і ми дійшли до точки після розколу, щоб мати стан найменшої випадковості. Отже, інформаційний приріст повинен бути найбільшим у функції, яку ми хочемо розділити. В іншому випадку, якщо ми хочемо вибрати поділ на основі індексу Джині, ми знайдемо індекс Джині для різних атрибутів і, використовуючи той самий, ми знайдемо зважений індекс Джині для різного розділення та використаємо той, який має більш високий індекс Джині, щоб розділити набір даних.
Важливі умови дерева рішень в обміні даними
Ось деякі важливі умови дерева рішень у пошуку даних, наведені нижче:
- Root Node: Це перший вузол, де відбувається розщеплення.
- Листовий вузол: це вузол, після якого більше немає розгалуження.
- Вузол прийняття рішення: Вузол, сформований після розщеплення даних з попереднього вузла, відомий як вузол рішення.
- Гілка: підрозділ дерева, що містить інформацію про наслідки розщеплення у вузлі рішення.
- Обрізка: коли відбувається видалення підвузлів вузла рішення для задоволення сторонніх чи галасливих даних, називається обрізка. Також вважається протилежною розщепленню.
Застосування дерева рішень при обробці даних
Дерево рішень має тип архітектури потокової схеми, вбудований з типом алгоритму. Він, по суті, має зразок “If X, то Y else Z” під час розбиття. Цей тип візерунка використовується для розуміння інтуїції людини в програмній галузі. Отже, можна широко використовувати це в різних проблемах категоризації.
- Цей алгоритм може широко застосовуватися в галузі, де об'єктивна функція пов'язана з аналізом.
- Коли доступні численні напрямки дій.
- Зовнішній аналіз.
- Розуміння значного набору функцій для всього набору даних та «моє» декілька функцій зі списку сотень функцій у великих даних.
- Вибір найкращого рейсу для подорожі до пункту призначення.
- Процес прийняття рішень на основі різних обставин.
- Аналіз Churn.
- Аналіз почуттів.
Переваги Дерева рішень
Ось деякі переваги дерева рішень, пояснених нижче:
- Простота розуміння: те, як зображено дерево рішень у його графічних формах, дозволяє зрозуміти людину, що не має аналітичного походження. Особливо для людей в лідерстві, які хочуть подивитися, які особливості важливі лише поглядом на дерево рішень, можуть викласти свою гіпотезу.
- Дослідження даних: Як обговорювалося, отримання значущих змінних є основною функціональністю дерева рішень, використовуючи це, можна визначити під час дослідження даних щодо вирішення того, яка змінна потребує особливої уваги під час фази збору даних та моделювання.
- На стадії підготовки даних дуже мало втручання людини, і внаслідок цього часу, витраченого під час даних, очищення зменшується.
- Дерево рішень здатне обробляти як категоричні, так і числові змінні, а також вирішує проблеми класифікації класів.
- Як частина припущення, дерева рішень не мають припущення про структуру просторового розподілу та класифікатора.
Висновок
Нарешті, підсумовуючи, Дерева рішень приносять зовсім інший клас нелінійності та сприяють вирішенню проблем з нелінійності. Цей алгоритм є найкращим вибором для імітації мислення людей на рівні рішень та відображення його у математично-графічній формі. Він визначає підхід зверху вниз при визначенні результатів за новими небаченими даними та слідує принципу ділення та перемоги.
Рекомендовані статті
Це посібник з дерева рішень в обробці даних. Тут ми обговорюємо алгоритм, важливість та застосування дерева рішень при обробці даних разом з його перевагами. Ви також можете переглянути наступні статті, щоб дізнатися більше -
- Машинне навчання даних з наукових даних
- Типи методів аналізу даних
- Дерево рішень в R
- Що таке майнінг даних?
- Посібник з різних методологій аналізу даних